相似度计算
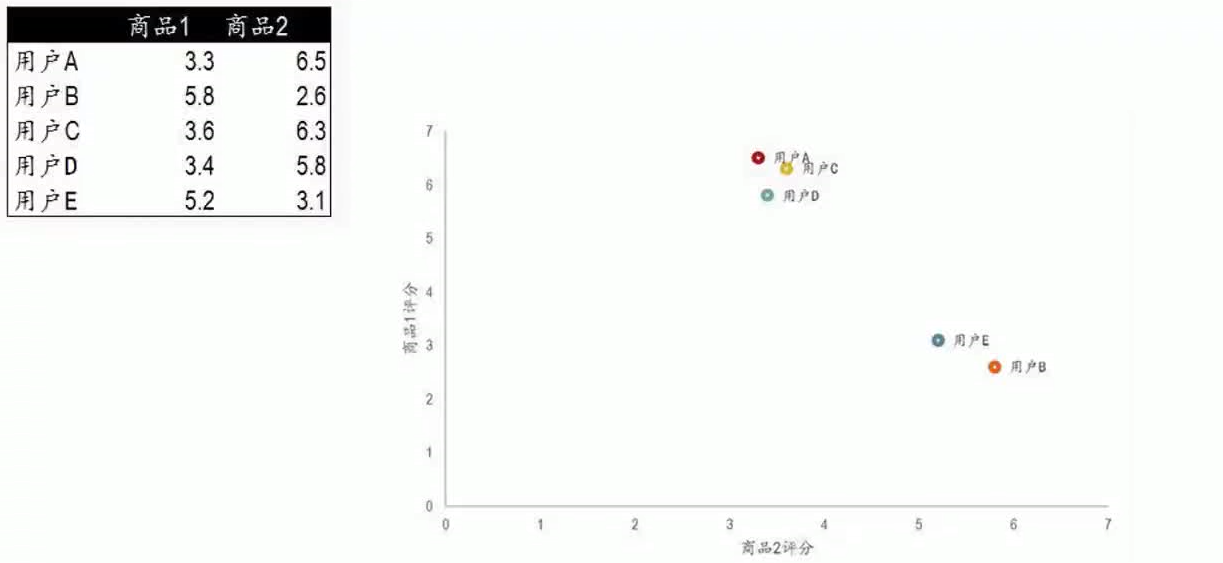

皮尔逊相关系数

协方差取值范围:-1到1,越趋近于1两个变量完全正相关,越趋近于-1两个变量完全负相关
 通常情况下选择使用:皮尔逊相关系数。
通常情况下选择使用:皮尔逊相关系数。
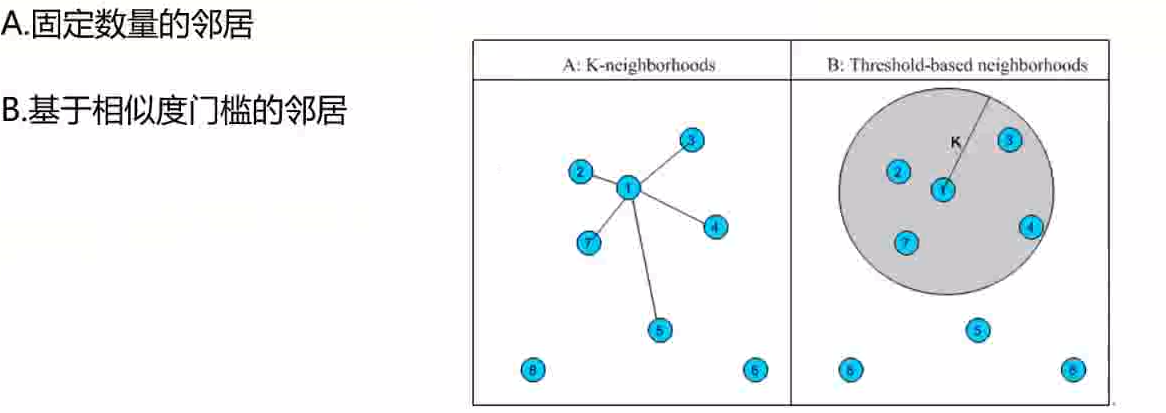
邻居的选择
基于用户的协同过滤

基于用户的协同过滤要解决的问题
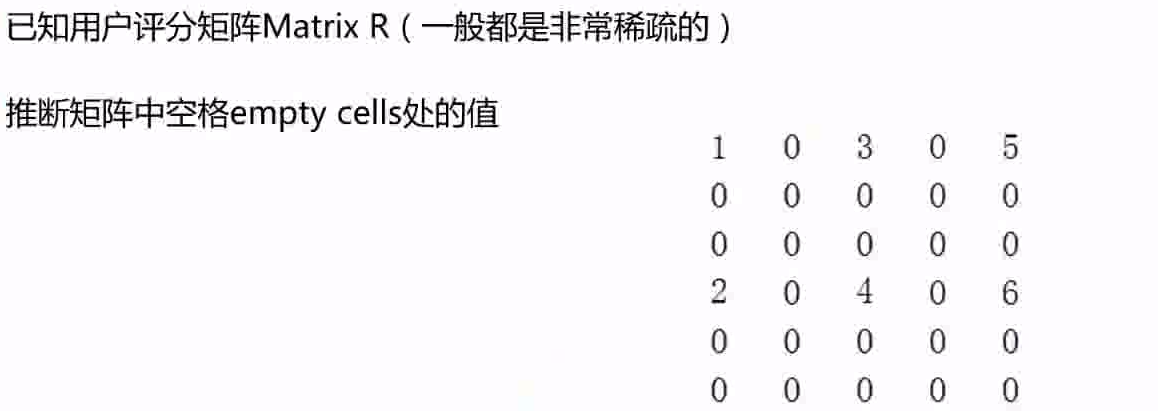
基于用户的协同过滤存在的问题issues:

基础解决方案:

基于用户的协同过滤不常用问题?

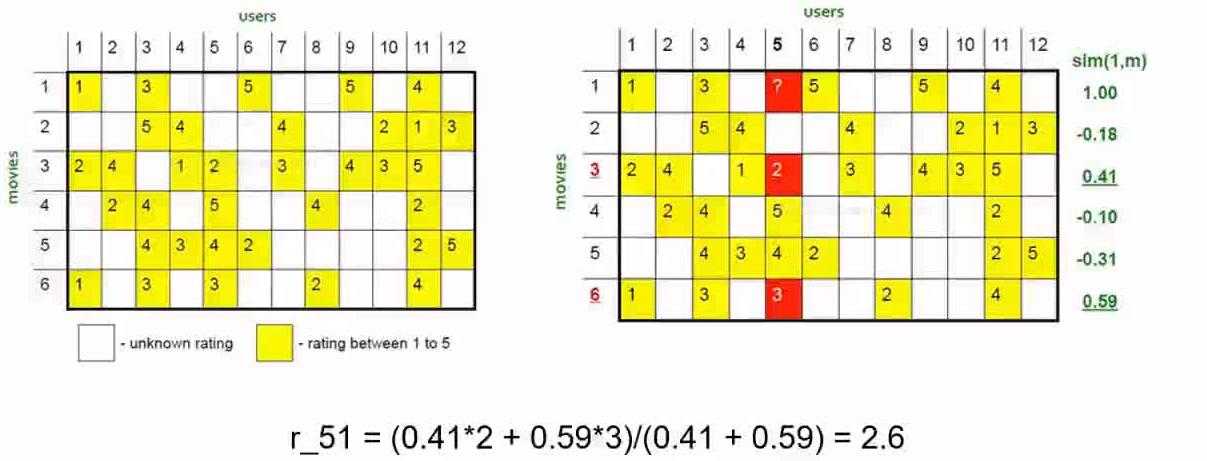
基于物品的协同过滤:

不是计算物品A和物品C之间物品属性的相似度,而是计算这些物品在用户之间联系的相似度。和物品的内在属性木有关系。
基于物品的协同过滤优势:

用户冷启动的问题:

物品冷启动的问题:

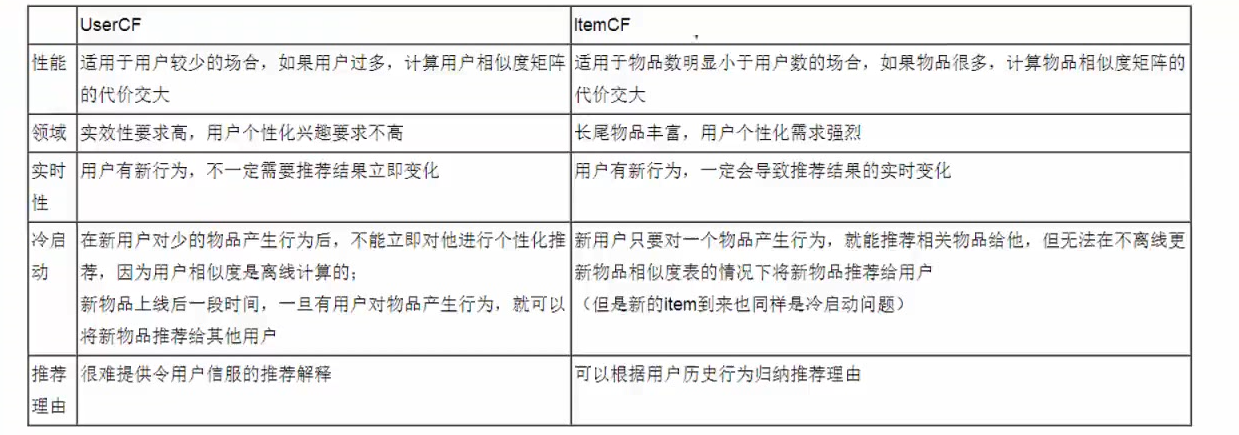
隐语义模型:

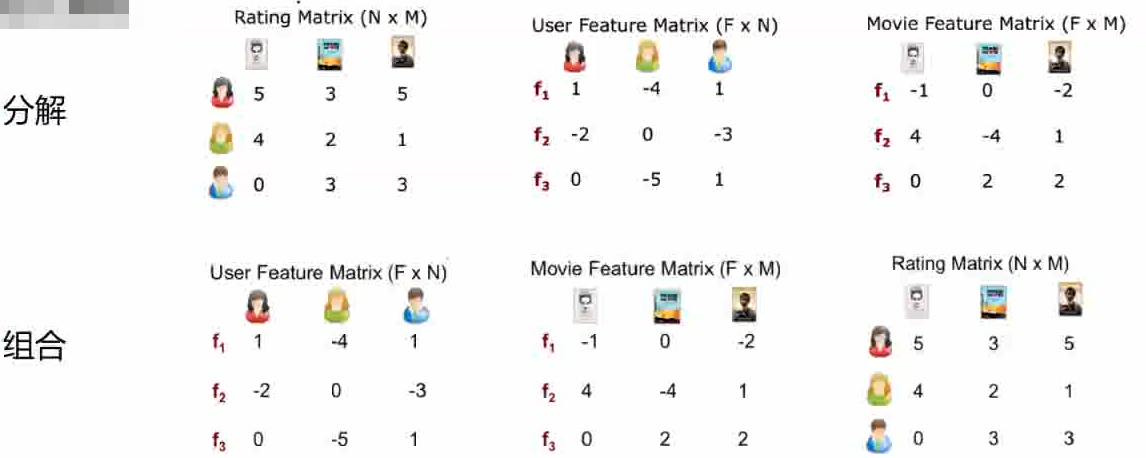
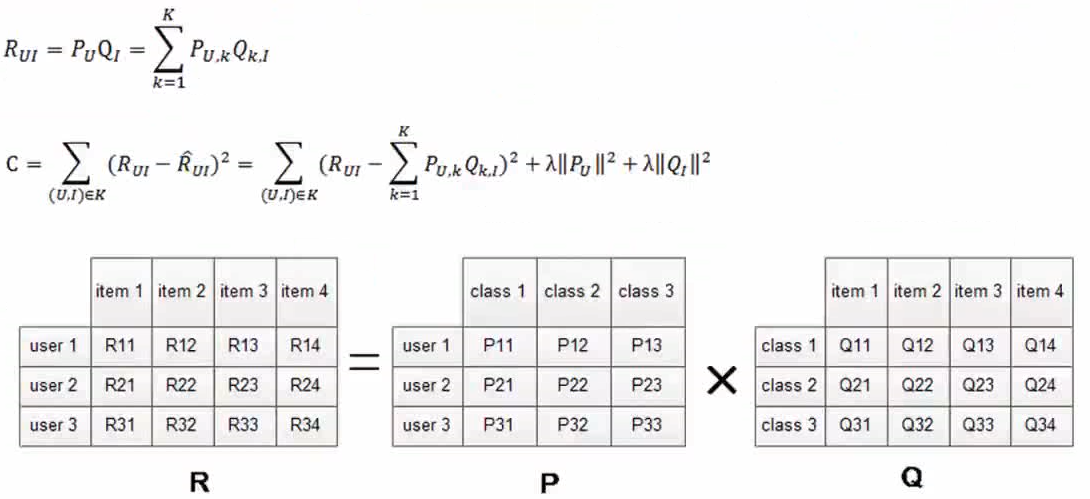
公式后两个是正则化项。
隐语义模型求解:
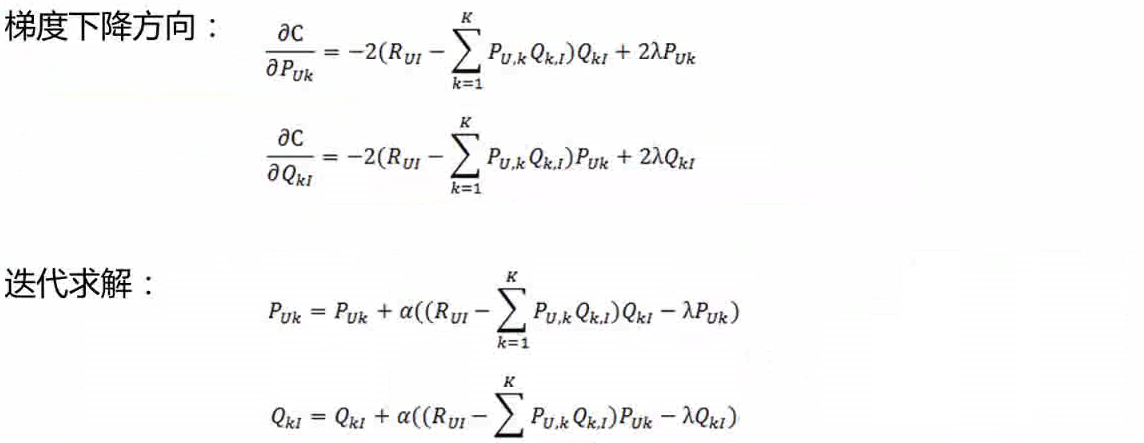
隐语义模型负样本选择:

隐语义模型参数的选择:
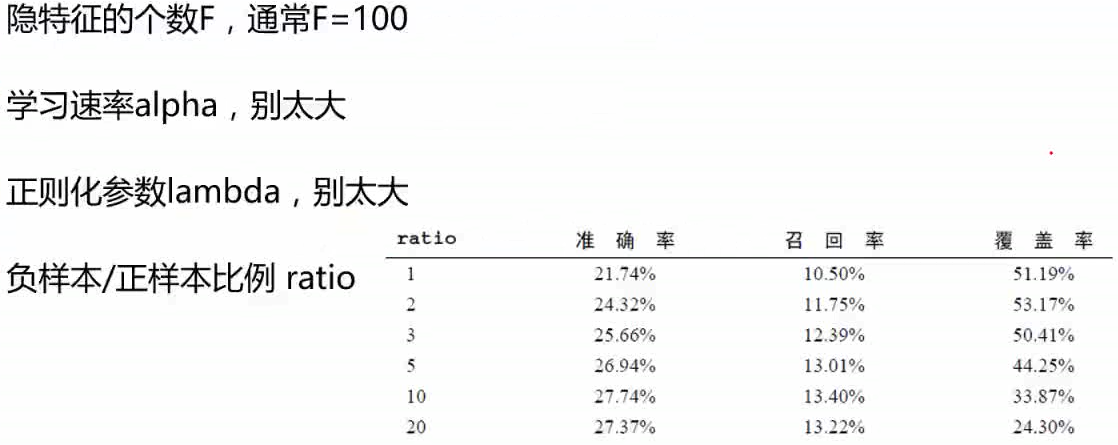
ratio值一般5--10
协同过滤VS隐语义

评估标准:

RMSE (均方根误差):其中T为测试集;rui为用户u对物品i的实际评分,r^ui为预测评分。
准确率定义为系统的推荐列表中用户喜欢的产品和所有被推荐产品的比率。
召回率 = 提取出的正确信息条数 / 样本中的信息条数。
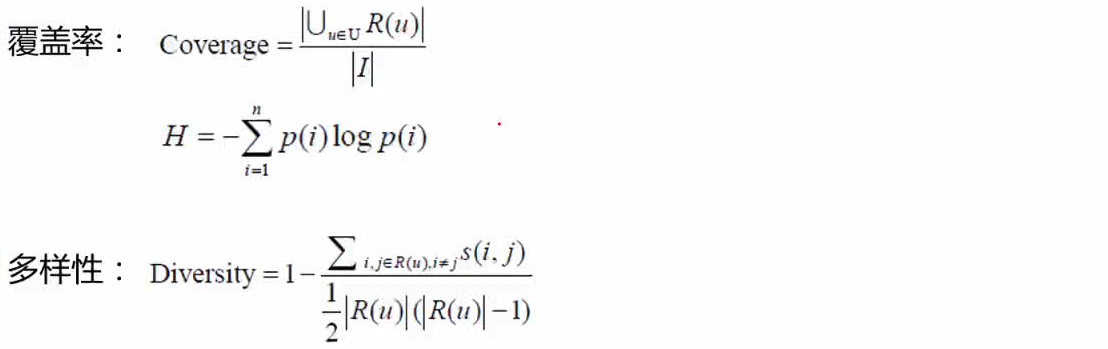
覆盖率:体现了挖掘算法对挖掘长尾商品的能力。最简单的定义是,对所有用户推荐出的产品做并集,然后看这个出现的并集产品与总产品数中所占的比例,这种方式比较的粗线条,因为推荐系统中马太效应频繁,所以好的推荐算法应当是所有商品被推荐的几率差不多,都可以找到各自合适的用户,所以实际中会考虑信息熵、基尼系数等指标。
多样性:其原理可以表述为不在一棵树上吊死。因整个推荐系统涉及到的因素太多,如果只推荐用户一个类别的相似物品,失败风险比较的大,而且也难以实现整个推荐效益的最大化。


