


原文:https://gitbook.cn/books/5954c9600326c7705af8a92a/index.html
接上一篇:史上最详细、最全面的Hadoop环境搭建
HA方式安装部署才是最常见的生产环境上的安装部署方式。Hadoop HA是Hadoop 2.x中新添加的特性,包括NameNode HA 和 ResourceManager HA。因为DataNode和NodeManager本身就是被设计为高可用的,所以不用对他们进行特殊的高可用处理。
时间服务器搭建
Hadoop对集群中各个机器的时间同步要求比较高。
#配置NTP服务器我们选择第三台机器(bigdata-senior03.chybinmy.com)为NTF服务器,其他机器和这台机器进行同步。检查ntp服务是否已经安装[hadoop@bigdata-senior03 data]$ sudo rpm -qa | grep ntpntpdate-4.2.6p5-1.el6.centos.x86_64ntp-4.2.6p5-1.el6.centos.x86_64#显示已经安装过了ntp程序,其中ntpdate-4.2.6p5-1.el6.centos.x86_64 是用来和某台服务器进行同步的,ntp-4.2.6p5-1.el6.centos.x86_64是用来提供时间同步服务的。#修改配置文件ntp.conf[hadoop@bigdata-senior03 data]$ vim /etc/ntp.conf#启用restrice,修改网段restrict 192.168.100.0 mask 255.255.255.0 nomodify notrap 将这行的注释去掉,并且将网段改为集群的网段,我们这里是100网段。#注释掉server域名配置#server 0.centos.pool.ntp.org iburst#server 1.centos.pool.ntp.org iburst#server 2.centos.pool.ntp.org iburst#server 3.centos.pool.ntp.org iburst是时间服务器的域名,这里不需要连接互联网,所以将他们注释掉。修改server 127.127.1.0fudge 127.127.1.0 stratum 10#修改配置文件ntpd[hadoop@bigdata-senior03 ~]$ sudo vim /etc/sysconfig/ntpd添加一行配置:SYNC_CLOCK=yes
#启动ntp服务[hadoop@bigdata-senior03 ~]$ sudo chkconfig ntpd on这样每次机器启动时,ntp服务都会自动启动。#配置其他机器的同步切换到root用户进行配置通过contab进行定时同步:[root@bigdata-senior02 hadoop]# crontab -e */10 * * * * /usr/sbin/ntpdate bigdata-senior03.chybinmy.com[root@bigdata-senior02 hadoop]# crontab -e */10 * * * * /usr/sbin/ntpdate bigdata-senior03.chybinmy.com#测试同步是否有效,查看目前三台机器的时间。[hadoop@bigdata-senior03 ~]$ date "+%Y-%m-%d %H:%M:%S"2016-09-23 16:43:56[hadoop@bigdata-senior02 ~]$ date "+%Y-%m-%d %H:%M:%S"2016-09-23 16:44:08[hadoop@bigdata-senior01 data]$ date "+%Y-%m-%d %H:%M:%S"2016-09-23 16:44:18#修改bigdata-senior01上的时间,将时间改为一个以前的时间:[hadoop@bigdata-senior01 data]$ sudo date -s '2016-01-01 00:00:00'Fri Jan 1 00:00:00 CST 2016[hadoop@bigdata-senior01 data]$ date "+%Y-%m-%d %H:%M:%S"2016-01-01 00:00:05等10分钟,看是否可以实现自动同步,将bigdata-senior01上的时间修改为和bigdata-senior03上的一致。#查看是否自动同步时间[hadoop@bigdata-senior01 data]$ date "+%Y-%m-%d %H:%M:%S"2016-09-23 16:54:36可以看到bigdata-senior01上的时间已经实现自动同步了。Zookeeper分布式机器部署
zookeeper说明
Zookeeper在Hadoop集群中的作用。
Zookeeper是分布式管理协作框架,Zookeeper集群用来保证Hadoop集群的高可用,(高可用的含义是:集群中就算有一部分服务器宕机,也能保证正常地对外提供服务。)
安装zookeeper
我们这里在BigData01、BigData02、BigData03三台机器上安装zookeeper集群。
#解压安装包在BigData01上安装解压zookeeper安装包。[hadoop@bigdata-senior01 hadoop-2.5.0]$ tar -zxf /opt/sofeware/zookeeper-3.4.8.tar.gz -C /opt/modules/# 修改配置拷贝conf下的zoo_sample.cfg副本,改名为zoo.cfg。zoo.cfg是zookeeper的配置文件:[hadoop@bigdata-senior01 zookeeper-3.4.8]$ cp conf/zoo_sample.cfg conf/zoo.cfgdataDir属性设置zookeeper的数据文件存放的目录:dataDir=/opt/modules/zookeeper-3.4.8/data/zData指定zookeeper集群中各个机器的信息:server.1=bigdata-senior01.chybinmy.com:2888:3888server.2=bigdata-senior02.chybinmy.com:2888:3888server.3=bigdata-senior03.chybinmy.com:2888:3888server后面的数字范围是1到255,所以一个zookeeper集群最多可以有255个机器。
#创建myid文件在dataDir所指定的目录下创一个名为myid的文件,文件内容为server点后面的数字。
#分发到其他机器[hadoop@bigdata-senior01 zookeeper-3.4.8]$ scp -r /opt/modules/zookeeper-3.4.8 bigdata-senior02.chybinmy.com:/opt/modules[hadoop@bigdata-senior01 zookeeper-3.4.8]$ scp -r /opt/modules/zookeeper-3.4.8 bigdata-senior03.chybinmy.com:/opt/modules#修改其他机器上的myid文件[hadoop@bigdata-senior02 zookeeper-3.4.8]$ echo 2 > /opt/modules/zookeeper-3.4.8/data/zData/myid[hadoop@bigdata-senior02 zookeeper-3.4.8]$ cat /opt/modules/zookeeper-3.4.8/data/zData/myid [hadoop@bigdata-senior03 ~]$ echo 3 > /opt/modules/zookeeper-3.4.8/data/zData/myid[hadoop@bigdata-senior03 ~]$ cat /opt/modules/zookeeper-3.4.8/data/zData/myid#启动zookeeper需要在各个机器上分别启动zookeeper。[hadoop@bigdata-senior01 zookeeper-3.4.8]$ bin/zkServer.sh start[hadoop@bigdata-senior02 zookeeper-3.4.8]$ bin/zkServer.sh start[hadoop@bigdata-senior03 zookeeper-3.4.8]$ bin/zkServer.sh start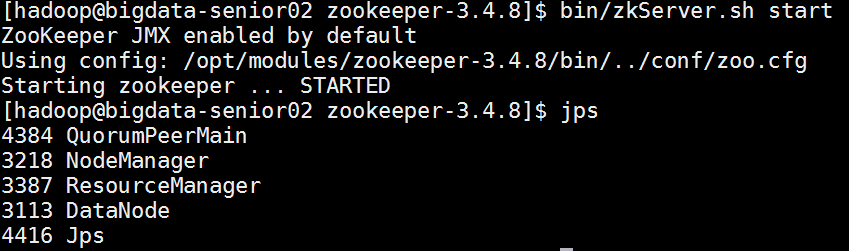
zookeeper命令

#进入zookeeper Shell:在zookeeper根目录下执行 bin/zkCli.sh进入zk shell模式。zookeeper很像一个小型的文件系统,/是根目录,下面的所有节点都叫zNode。进入zk shell 后输入任意字符,可以列出所有的zookeeper命令#查询zNode上的数据:get /zookeeper#创建一个zNode : create /znode1 “demodata “#列出所有子zNode:ls /#删除znode : rmr /znode1#退出shell模式:quitHadoop 2.x HDFS HA 部署
HDFS HA原理单NameNode的缺陷存在单点故障的问题,如果NameNode不可用,则会导致整个HDFS文件系统不可用。所以需要设计高可用的HDFS(Hadoop HA)来解决NameNode单点故障的问题。解决的方法是在HDFS集群中设置多个NameNode节点。但是一旦引入多个NameNode,就有一些问题需要解决。
HDFS HA需要保证的四个问题:
-
保证NameNode内存中元数据数据一致,并保证编辑日志文件的安全性。
-
多个NameNode如何协作
-
客户端如何能正确地访问到可用的那个NameNode。
-
怎么保证任意时刻只能有一个NameNode处于对外服务状态。
HDFS HA架构图

-
HDFS HA架构中有两台NameNode节点,一台是处于活动状态(Active)为客户端提供服务,另外一台处于热备份状态(Standby)。
-
元数据文件有两个文件:fsimage和edits,备份元数据就是备份这两个文件。JournalNode用来实时从Active NameNode上拷贝edits文件,JournalNode有三台也是为了实现高可用。
-
Standby NameNode不对外提供元数据的访问,它从Active NameNode上拷贝fsimage文件,从JournalNode上拷贝edits文件,然后负责合并fsimage和edits文件,相当于SecondaryNameNode的作用。最终目的是保证Standby NameNode上的元数据信息和Active NameNode上的元数据信息一致,以实现热备份。
-
Zookeeper来保证在Active NameNode失效时及时将Standby NameNode修改为Active状态。
-
ZKFC(失效检测控制)是Hadoop里的一个Zookeeper客户端,在每一个NameNode节点上都启动一个ZKFC进程,来监控NameNode的状态,并把NameNode的状态信息汇报给Zookeeper集群,其实就是在Zookeeper上创建了一个Znode节点,节点里保存了NameNode状态信息。当NameNode失效后,ZKFC检测到报告给Zookeeper,Zookeeper把对应的Znode删除掉,Standby ZKFC发现没有Active状态的NameNode时,就会用shell命令将自己监控的NameNode改为Active状态,并修改Znode上的数据。 Znode是个临时的节点,临时节点特征是客户端的连接断了后就会把znode删除,所以当ZKFC失效时,也会导致切换NameNode。
-
DataNode会将心跳信息和Block汇报信息同时发给两台NameNode,DataNode只接受Active NameNode发来的文件读写操作指令。
搭建HDFS HA 环境
服务器角色规划
| bigdata-senior01.chybinmy.com | bigdata-senior01.chybinmy.com | bigdata-senior01.chybinmy.com |
|---|---|---|
| NameNode | NameNode | |
| Zookeeper | Zookeeper | Zookeeper |
| DataNode | DataNode | DataNode |
| ResourceManage | ResourceManage | |
| NodeManager | NodeManager | NodeManager |
#创建HDFS HA 版本Hadoop程序目录在bigdata01、bigdata02、bigdata03三台机器上分别创建目录/opt/modules/hadoopha/用来存放Hadoop HA环境。[hadoop@bigdata-senior01 modules]$ mkdir /opt/modules/hadoopha#新解压Hadoop 2.5.0[hadoop@bigdata-senior01 ~]$ tar -zxf /opt/sofeware/hadoop-2.5.0.tar.gz -C /opt/modules/hadoopha/#配置Hadoop JDK路径修改hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的JDK路径export JAVA_HOME="/opt/modules/jdk1.7.0_67"#配置hdfs-site.xml<?xml version="1.0" encoding="UTF-8"?><configuration> <property> <!-- 为namenode集群定义一个services name --> <name>dfs.nameservices</name> <value>ns1</value> </property> <property> <!-- nameservice 包含哪些namenode,为各个namenode起名 --> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <property> <!-- 名为nn1的namenode 的rpc地址和端口号,rpc用来和datanode通讯 --> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>bigdata-senior01.chybinmy.com:8020</value> </property> <property> <!-- 名为nn2的namenode 的rpc地址和端口号,rpc用来和datanode通讯 --> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>bigdata-senior02.chybinmy.com:8020</value> </property> <property> <!--名为nn1的namenode 的http地址和端口号,web客户端 --> <name>dfs.namenode.http-address.ns1.nn1</name> <value>bigdata-senior01.chybinmy.com:50070</value> </property> <property> <!--名为nn2的namenode 的http地址和端口号,web客户端 --> <name>dfs.namenode.http-address.ns1.nn2</name> <value>bigdata-senior02.chybinmy.com:50070</value> </property> <property> <!-- namenode间用于共享编辑日志的journal节点列表 --> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://bigdata-senior01.chybinmy.com:8485;bigdata-senior02.chybinmy.com:8485;bigdata-senior03.chybinmy.com:8485/ns1</value> </property> <property> <!-- journalnode 上用于存放edits日志的目录 --> <name>dfs.journalnode.edits.dir</name> <value>/opt/modules/hadoopha/hadoop-2.5.0/tmp/data/dfs/jn</value> </property> <property> <!-- 客户端连接可用状态的NameNode所用的代理类 --> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <!-- --> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property></configuration>#配置core-site.xml<?xml version="1.0" encoding="UTF-8"?><configuration> <property> <!-- hdfs 地址,ha中是连接到nameservice --> <name>fs.defaultFS</name> <value>hdfs://ns1</value> </property> <property> <!-- --> <name>hadoop.tmp.dir</name> <value>/opt/modules/hadoopha/hadoop-2.5.0/data/tmp</value> </property></configuration>hadoop.tmp.dir设置hadoop临时目录地址,默认时,NameNode和DataNode的数据存在这个路径下。#配置slaves文件bigdata-senior01.chybinmy.combigdata-senior02.chybinmy.combigdata-senior03.chybinmy.com#分发到其他节点分发之前先将share/doc目录删除,这个目录中是帮助文件,并且很大,可以删除。[hadoop@bigdata-senior01 hadoop-2.5.0]$ scp -r /opt/modules/hadoopha bigdata-senior02.chybinmy.com:/opt/modules[hadoop@bigdata-senior01 hadoop-2.5.0]$ scp -r /opt/modules/hadoopha bigdata-senior03.chybinmy.com:/opt/modules启动HDFS HA集群
三台机器分别启动Journalnode。
[hadoop@bigdata-senior01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start journalnode[hadoop@bigdata-senior02 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start journalnode[hadoop@bigdata-senior03 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start journalnodejps命令查看是否启动。启动Zookeeper
#在三台节点上启动Zookeeper:[hadoop@bigdata-senior01 zookeeper-3.4.8]$ bin/zkServer.sh start[hadoop@bigdata-senior02 zookeeper-3.4.8]$ bin/zkServer.sh start[hadoop@bigdata-senior03 zookeeper-3.4.8]$ bin/zkServer.sh start#格式化NameNode在第一台上进行NameNode格式化:[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs namenode -format在第二台NameNode上:[hadoop@bigdata-senior02 hadoop-2.5.0]$ bin/hdfs namenode -bootstrapStandby#启动NameNode在第一台、第二台上启动NameNode:[hadoop@bigdata-senior01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start namenode[hadoop@bigdata-senior02 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start namenode#查看HDFS Web页面,此时两个NameNode都是standby状态。切换第一台为active状态:[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs haadmin -transitionToActive nn1可以添加上forcemanual参数,强制将一个NameNode转换为Active状态。[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs haadmin –transitionToActive -forcemanual nn1此时从web 页面就看到第一台已经是active状态了。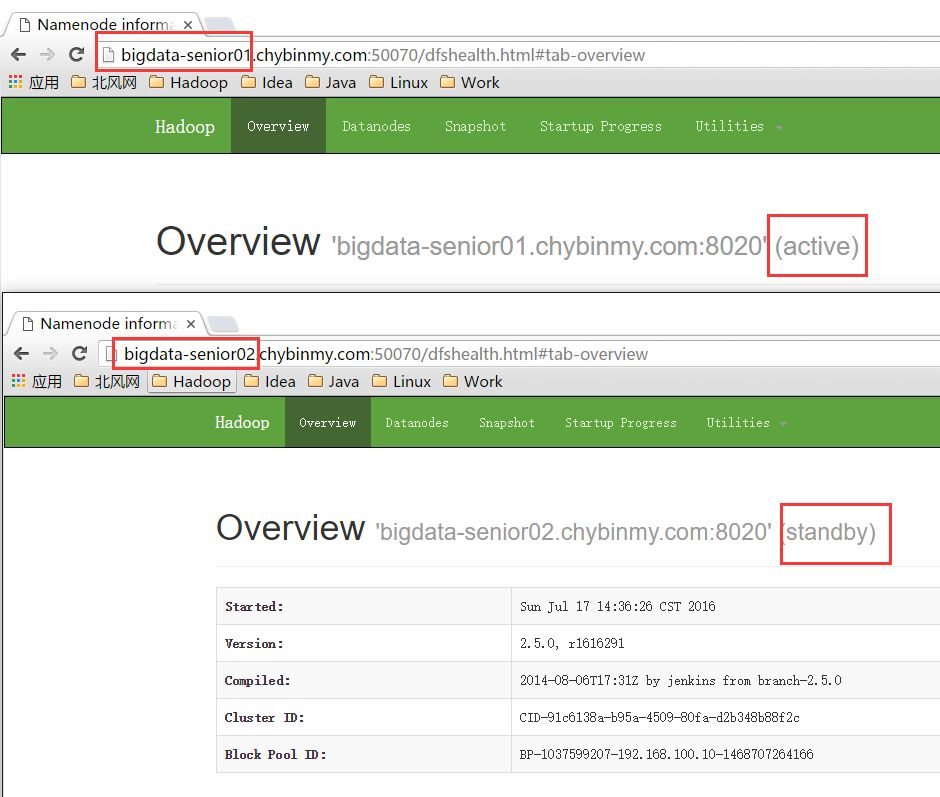
配置故障自动转移
利用zookeeper集群实现故障自动转移,在配置故障自动转移之前,要先关闭集群,不能在HDFS运行期间进行配置。
#关闭NameNode、DataNode、JournalNode、zookeeper[hadoop@bigdata-senior01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh stop namenode[hadoop@bigdata-senior01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh stop datanode[hadoop@bigdata-senior01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh stop journalnode[hadoop@bigdata-senior01 hadoop-2.5.0]$ cd ../../zookeeper-3.4.8/[hadoop@bigdata-senior01 zookeeper-3.4.8]$ bin/zkServer.sh stop[hadoop@bigdata-senior02 hadoop-2.5.0]$ sbin/hadoop-daemon.sh stop namenode[hadoop@bigdata-senior02 hadoop-2.5.0]$ sbin/hadoop-daemon.sh stop datanode[hadoop@bigdata- senior02 hadoop-2.5.0]$ sbin/hadoop-daemon.sh stop journalnode[hadoop@bigdata- senior02 hadoop-2.5.0]$ cd ../../zookeeper-3.4.8/[hadoop@bigdata- senior02 zookeeper-3.4.8]$ bin/zkServer.sh stop[hadoop@bigdata- senior03 hadoop-2.5.0]$ sbin/hadoop-daemon.sh stop datanode[hadoop@bigdata- senior03 hadoop-2.5.0]$ sbin/hadoop-daemon.sh stop journalnode[hadoop@bigdata- senior03 hadoop-2.5.0]$ cd ../../zookeeper-3.4.8/[hadoop@bigdata- senior03 zookeeper-3.4.8]$ bin/zkServer.sh stop#修改hdfs-site.xml<property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value></property>#修改core-site.xml<property> <name>ha.zookeeper.quorum</name> <value>bigdata-senior01.chybinmy.com:2181,bigdata-senior02.chybinmy.com:2181,bigdata-senior03.chybinmy.com:2181</value></property>#将hdfs-site.xml和core-site.xml分发到其他机器[hadoop@bigdata-senior01 hadoop-2.5.0]$ scp /opt/modules/hadoopha/hadoop-2.5.0/etc/hadoop/hdfs-site.xml bigdata-senior02.chybinmy.com:/opt/modules/hadoopha/hadoop-2.5.0/etc/hadoop/[hadoop@bigdata-senior01 hadoop-2.5.0]$ scp /opt/modules/hadoopha/hadoop-2.5.0/etc/hadoop/hdfs-site.xml bigdata-senior03.chybinmy.com:/opt/modules/hadoopha/hadoop-2.5.0/etc/hadoop/[hadoop@bigdata-senior01 hadoop-2.5.0]$ scp /opt/modules/hadoopha/hadoop-2.5.0/etc/hadoop/core-site.xml bigdata-senior02.chybinmy.com:/opt/modules/hadoopha/hadoop-2.5.0/etc/hadoop/[hadoop@bigdata-senior01 hadoop-2.5.0]$ scp /opt/modules/hadoopha/hadoop-2.5.0/etc/hadoop/core-site.xml bigdata-senior03.chybinmy.com:/opt/modules/hadoopha/hadoop-2.5.0/etc/hadoop/启动zookeeper
#三台机器启动zookeeper[hadoop@bigdata-senior01 hadoop-2.5.0]$ /opt/modules/zookeeper-3.4.8/bin/zkServer.sh start#创建一个zNode[hadoop@bigdata-senior01 hadoop-2.5.0]$ cd /opt/modules/hadoopha/hadoop-2.5.0/[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs zkfc -formatZK在Zookeeper上创建一个存储namenode相关的节点。启动HDFS、JournalNode、zkfc
#启动NameNode、DataNode、JournalNode、zkfc[hadoop@bigdata-senior01 hadoop-2.5.0]$ sbin/start-dfs.shzkfc只针对NameNode监听。测试HDFS HA
#测试故障自动转移和数据是否共享在nn1上上传文件,目前bigdata-senior01节点上的NameNode是Active状态的。
[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs dfs -put /opt/data/wc.input /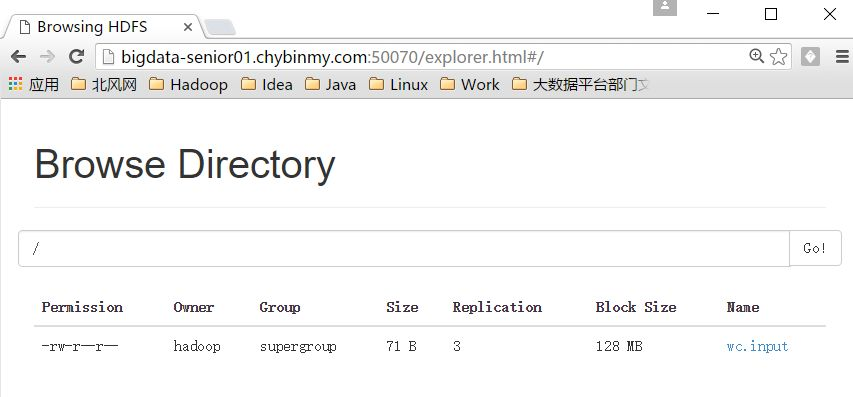
#将nn1上的NodeNode进程杀掉[hadoop@bigdata-senior01 hadoop-2.5.0]$ kill -9 3364nn1上的namenode已经无法访问了。查看nn2是否是Active状态。
#在nn2上查看是否看见文件
经以上验证,已经实现了nn1和nn2之间的文件同步和故障自动转移。Hadoop 2.x YARN HA 部署
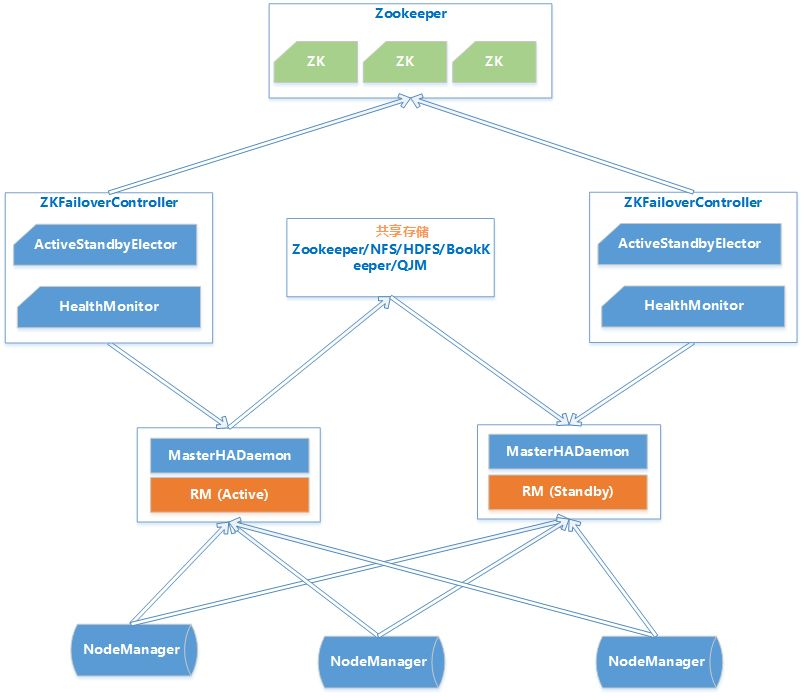
YARN HA原理Hadoop2.4版本之前,ResourceManager也存在单点故障的问题,也需要实现HA来保证ResourceManger的高可也用性。ResouceManager从记录着当前集群的资源分配情况和JOB的运行状态,YRAN HA 利用Zookeeper等共享存储介质来存储这些信息来达到高可用。另外利用Zookeeper来实现ResourceManager自动故障转移。
-
MasterHADaemon:控制RM的 Master的启动和停止,和RM运行在一个进程中,可以接收外部RPC命令。
-
共享存储:Active Master将信息写入共享存储,Standby Master读取共享存储信息以保持和Active Master同步。
-
ZKFailoverController:基于Zookeeper实现的切换控制器,由ActiveStandbyElector和HealthMonitor组成,ActiveStandbyElector负责与Zookeeper交互,判断所管理的Master是进入Active还是Standby;HealthMonitor负责监控Master的活动健康情况,是个监视器。
-
Zookeeper:核心功能是维护一把全局锁控制整个集群上只有一个Active的ResourceManager。
搭建YARN HA环境
服务器角色规划
| bigdata-senior01.chybinmy.com | bigdata-senior01.chybinmy.com | bigdata-senior01.chybinmy.com |
|---|---|---|
| NameNode | NameNode | |
| Zookeeper | Zookeeper | Zookeeper |
| DataNode | DataNode | DataNode |
| ResourceManage | ResourceManage | |
| NodeManager | NodeManager | NodeManager |
#修改配置文件yarn-site.xml<?xml version="1.0" encoding="UTF-8"?><configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property> <property> <!-- 启用resourcemanager的ha功能 --> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <!-- 为resourcemanage ha 集群起个id --> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-cluster</value> </property> <property> <!-- 指定resourcemanger ha 有哪些节点名 --> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm12,rm13</value> </property> <property> <!-- 指定第一个节点的所在机器 --> <name>yarn.resourcemanager.hostname.rm12</name> <value>bigdata-senior02.chybinmy.com</value> </property> <property> <!-- 指定第二个节点所在机器 --> <name>yarn.resourcemanager.hostname.rm13</name> <value>bigdata-senior03.chybinmy.com</value> </property> <property> <!-- 指定resourcemanger ha 所用的zookeeper 节点 --> <name>yarn.resourcemanager.zk-address</name> <value>bigdata-senior01.chybinmy.com:2181,bigdata-senior02.chybinmy.com:2181,bigdata-senior03.chybinmy.com:2181</value> </property> <property> <!-- --> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <!-- --> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property></configuration>#分发到其他机器[hadoop@bigdata-senior01 hadoop-2.5.0]$ scp /opt/modules/hadoopha/hadoop-2.5.0/etc/hadoop/yarn-site.xml bigdata-senior02.chybinmy.com:/opt/modules/hadoopha/hadoop-2.5.0/etc/hadoop/[hadoop@bigdata-senior01 hadoop-2.5.0]$ scp /opt/modules/hadoopha/hadoop-2.5.0/etc/hadoop/yarn-site.xml bigdata-senior03.chybinmy.com:/opt/modules/hadoopha/hadoop-2.5.0/etc/hadoop/\#启动在bigdata-senior01上启动yarn:[hadoop@bigdata-senior01 hadoop-2.5.0]$ sbin/start-yarn.sh在bigdata-senior02、bigdata-senior03上启动resourcemanager:[hadoop@bigdata-senior02 hadoop-2.5.0]$ sbin/yarn-daemon.sh start resourcemanager[hadoop@bigdata-senior03 hadoop-2.5.0]$ sbin/yarn-daemon.sh start resourcemanager#启动后各个节点的进程。

Web客户端访问bigdata02机器上的resourcemanager正常,它是active状态的。http://bigdata-senior02.chybinmy.com:8088/cluster访问另外一个resourcemanager,因为他是standby,会自动跳转到active的resourcemanager。http://bigdata-senior03.chybinmy.com:8088/cluster测试YARN HA
#运行一个mapreduce job[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /wc.input /input#在job运行过程中,将Active状态的resourcemanager进程杀掉。[hadoop@bigdata-senior02 hadoop-2.5.0]$ kill -9 4475# 观察另外一个resourcemanager是否可以自动接替。bigdata02的resourcemanage Web客户端已经不能访问,bigdata03的resourcemanage已经自动变为active状态。#观察job是否可以顺利完成。而mapreduce job 也能顺利完成,没有因为resourcemanager的意外故障而影响运行。经过以上测试,已经验证YARN HA 已经搭建成功。HDFS Federation 架构部署
HDFS Federation 的使用原因
1、 单个NameNode节点的局限性
-
命名空间的限制。NameNode上存储着整个HDFS上的文件的元数据,NameNode是部署在一台机器上的,因为单个机器硬件的限制,必然会限制NameNode所能管理的文件个数,制约了数据量的增长。
-
数据隔离问题。整个HDFS上的文件都由一个NameNode管理,所以一个程序很有可能会影响到整个HDFS上的程序,并且权限控制比较复杂。
-
性能瓶颈。单个NameNode时HDFS文件系统的吞吐量受限于单个NameNode的吞吐量。因为NameNode是个JVM进程,JVM进程所占用的内存很大时,性能会下降很多。
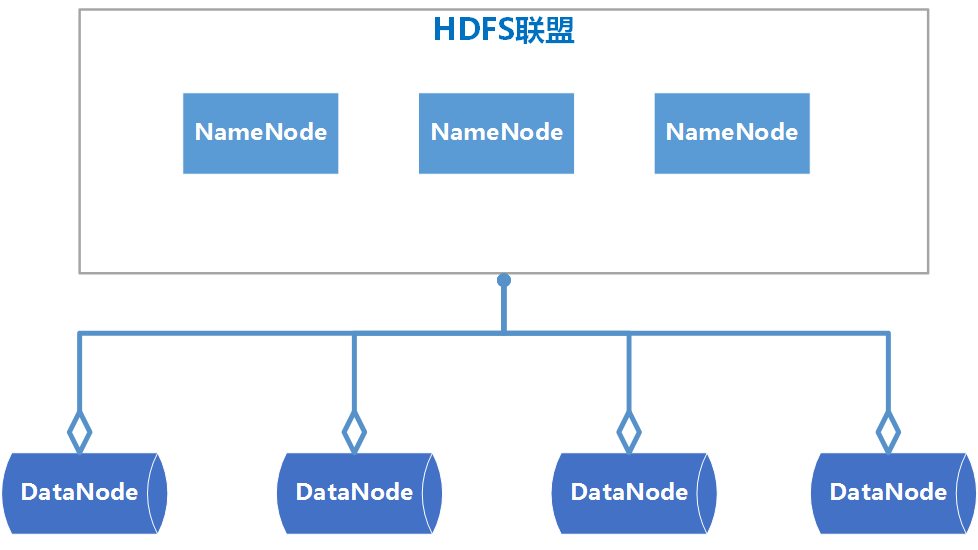
HDFS Federation介绍
-
HDFS Federation是可以在Hadoop集群中设置多个NameNode,不同于HA中多个NameNode是完全一样的,是多个备份,Federation中的多个NameNode是不同的,可以理解为将一个NameNode切分为了多个NameNode,每一个NameNode只负责管理一部分数据。
-
HDFS Federation中的多个NameNode共用DataNode。
HDFS Federation的架构图
HDFS Federation搭建
服务器角色规划
| bigdata-senior01.chybinmy.com | bigdata-senior01.chybinmy.com | bigdata-senior01.chybinmy.com |
|---|---|---|
| NameNode1 | NameNode2 | NameNode3 |
| ResourceManage | ||
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
#创建HDFS Federation 版本Hadoop程序目录在bigdata01上创建目录/opt/modules/hadoopfederation /用来存放Hadoop Federation环境。[hadoop@bigdata-senior01 modules]$ mkdir /opt/modules/hadoopfederation#新解压Hadoop 2.5.0[hadoop@bigdata-senior01 ~]$ tar -zxf /opt/sofeware/hadoop-2.5.0.tar.gz -C /opt/modules/hadoopfederation/# 配置Hadoop JDK路径修改hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的JDK路径。export JAVA_HOME=”/opt/modules/jdk1.7.0_67”#配置hdfs-site.xml<configuration><property><!—配置三台NameNode --> <name>dfs.nameservices</name> <value>ns1,ns2,ns3</value> </property> <property><!—第一台NameNode的机器名和rpc端口,指定了NameNode和DataNode通讯用的端口号 --> <name>dfs.namenode.rpc-address.ns1</name> <value>bigdata-senior01.chybinmy.com:8020</value> </property> <property><!—第一台NameNode的机器名和rpc端口,备用端口号 --> <name>dfs.namenode.serviceerpc-address.ns1</name> <value>bigdata-senior01.chybinmy.com:8022</value> </property> <property><!—第一台NameNode的http页面地址和端口号 --> <name>dfs.namenode.http-address.ns1</name> <value>bigdata-senior01.chybinmy.com:50070</value> </property><property><!—第一台NameNode的https页面地址和端口号 --> <name>dfs.namenode.https-address.ns1</name> <value>bigdata-senior01.chybinmy.com:50470</value> </property> <property> <name>dfs.namenode.rpc-address.ns2</name> <value>bigdata-senior02.chybinmy.com:8020</value> </property> <property> <name>dfs.namenode.serviceerpc-address.ns2</name> <value>bigdata-senior02.chybinmy.com:8022</value> </property> <property> <name>dfs.namenode.http-address.ns2</name> <value>bigdata-senior02.chybinmy.com:50070</value> </property> <property> <name>dfs.namenode.https-address.ns2</name> <value>bigdata-senior02.chybinmy.com:50470</value></property><property> <name>dfs.namenode.rpc-address.ns3</name> <value>bigdata-senior03.chybinmy.com:8020</value> </property> <property> <name>dfs.namenode.serviceerpc-address.ns3</name> <value>bigdata-senior03.chybinmy.com:8022</value> </property> <property> <name>dfs.namenode.http-address.ns3</name> <value>bigdata-senior03.chybinmy.com:50070</value> </property> <property> <name>dfs.namenode.https-address.ns3</name> <value>bigdata-senior03.chybinmy.com:50470</value> </property> </configuration>#配置core-site.xml<configuration><property> <name>hadoop.tmp.dir</name> <value>/opt/modules/hadoopha/hadoop-2.5.0/data/tmp</value></property></configuration>hadoop.tmp.dir设置hadoop临时目录地址,默认时,NameNode和DataNode的数据存在这个路径下。#配置slaves文件bigdata-senior01.chybinmy.combigdata-senior02.chybinmy.combigdata-senior03.chybinmy.com#配置yarn-site.xml<configuration><property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>bigdata-senior02.chybinmy.com</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property> </configuration>#分发到其他节点分发之前先将share/doc目录删除,这个目录中是帮助文件,并且很大,可以删除。[hadoop@bigdata-senior01 hadoop-2.5.0]$ scp -r /opt/modules/ /opt/modules/hadoopfederation bigdata-senior02.chybinmy.com:/opt/modules[hadoop@bigdata-senior01 hadoop-2.5.0]$ scp -r /opt/modules/hadoopfederation bigdata-senior03.chybinmy.com:/opt/modules#格式化NameNode在第一台上进行NameNode格式化:[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs namenode -format -clusterId hadoop-federation-clusterId这里一定要指定一个集群ID,使得多个NameNode的集群ID是一样的,因为这三个NameNode在同一个集群中,这里集群ID为hadoop-federation-clusterId。在第二台NameNode上:[hadoop@bigdata-senior02 hadoop-2.5.0]$ bin/hdfs namenode -format -clusterId hadoop-federation-clusterId在第三台NameNode上:[hadoop@bigdata-senior03 hadoop-2.5.0]$ bin/hdfs namenode -format -clusterId hadoop-federation-clusterId# 启动NameNode在第一台、第二台、第三台机器上启动NameNode:[hadoop@bigdata-senior01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start namenode[hadoop@bigdata-senior02 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start namenode[hadoop@bigdata-senior03 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start namenode启动后,用jps命令查看是否已经启动成功。查看HDFS Web页面,此时三个NameNode都是standby状态。


#启动DataNode[hadoop@bigdata-senior01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start datanode[hadoop@bigdata-senior02 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start datanode[hadoop@bigdata-senior03 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start datanode启动后,用jps命令确认DataNode进程已经启动成功。测试HDFS Federation
#修改core-site.xml在bigdata-senior01机器上,修改core-site.xml文件,指定连接的NameNode是第一台NameNode。[hadoop@bigdata-senior01 hadoop-2.5.0]$ vim etc/hadoop/core-site.xml<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://bigdata-senior01.chybinmy.com:8020</value> </property><property> <name>hadoop.tmp.dir</name> <value>/opt/modules/hadoopfederation/hadoop-2.5.0/data/tmp</value></property></configuration>#在bigdate-senior01上传一个文件到HDFS[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs dfs -mkdir /tmp[hadoop@bigdata-senior01 hadoop-2.5.0]$ bin/hdfs dfs -put ~/shuffle_daily.sh /tmp/shuffle_daily.sh#查看HDFS文件
可以看到,刚才的文件只上传到了bigdate-senior01机器上的NameNode上了,并没有上传到其他的NameNode上去。这样,在HDFS的客户端,可以指定要上传到哪个NameNode上,从而来达到了划分NameNode的目的。推荐阅读
使用docker Registry快速搭建私有镜像仓库(内附干货)
·end·
—写文不易,你的转发就是对我最大的支持—
我们一起愉快的玩耍吧

目前40000+人已关注加入我们















关注公众号点击菜单“微信群” 入群一起交流吧

喜欢,就扫码关注给它增加一个读者吧!
