

选自arXiv
作 者: Xinyue Liu、Xiangnan Kong、Lei Liu、Kuorong Chiang
机器之心编译
参与:Geek AI、张倩
生成对抗网络(GAN)在图像生成领域表现出了很强的能力。最近,GAN 从图像生成领域扩展到了序列生成领域。用于序列生成的现有 GAN 主要关注的是一些语法无关的一般序列。然而,在许多实际应用程序中,我们需要生成一种形式语言的序列,并受相应语法的约束。生成这样的序列非常具有挑战性。为了解决这些问题,本文研究了通过 GAN 实现的有句法意识的序列生成问题,提出了一个新的 GAN 框架——TreeGAN,将给定的上下文无关文法(CFG)融入序列生成过程中。本文证明了 TreeGAN 可以为任何 CFG 生成序列,它的生成完全符合给定的句法。在合成和真实数据集上的实验表明,TreeGAN 显著提高了上下文无关语言中序列生成的质量。
1. 引言
生成对抗网络是由生成网络和判别网络组成的无监督学习框架。我们将它们称为生成器(G)和判别器(D)。D 学着去区分某个数据实例是来自真实世界还是人为合成的。G 试图通过生成高质量的合成实例来迷惑 D。在 GAN 框架中,D 和 G 被不断地轮流训练直到它们达到纳什均衡。训练好的 GAN 会得到一个能够产生看起来与真实数据十分相似的高质量数据实例的生成器。
受到其在图像生成和相关领域取得的巨大成功的启发,GAN[1] 最近已经被扩展到序列生成任务中 [2,3]。用于序列生成的 GAN 在现实世界中有许多重要的应用。例如,为了给一个数据库构建一个良好的查询优化器,研究人员可能希望生成大量高质量的合成 SQL 查询语句对优化器进行基准对比测试。不同于图像生成任务,大多数语言都有其固有的语法或句法。现有的用于序列生成的 GAN 模型 [2,3,7] 主要着眼于如图 1a 所示的句法无关(grammar-free)的环境。这些方法试图从数据中学习到复杂的底层句法和语法模式,这通常是非常具有挑战性的,需要大量的真实数据样本才能取得不错的性能。在许多形式语言中,语法规则或句法(例如,SQL 句法,Python PL 句法)是预定义好的。将这样的句法引入到 GAN 的训练中,应该会得出一个具有句法意识的更好的序列生成器,并且在训练阶段显著缩小搜索空间。有句法意识的现有序列生成模型 [4] 主要是通过极大似然估计(MLE)进行训练的,它们高度依赖于真实数据样本的质量和数量。一些研究 [2,5] 表明,对抗性训练可以进一步提高基于极大似然估计的序列生成性能。即使有句法意识的现有序列生成方法引入了语法信息,其生成结果也可能不是最好的。
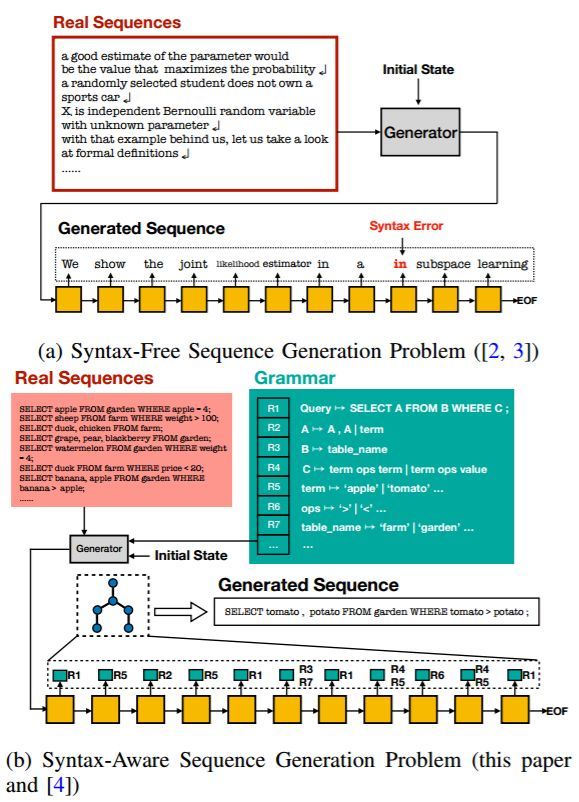
图 1:两个问题设定背景的比较。(a)句法无关的序列生成问题。仅仅使用了一组真实序列训练生成器,生成的序列可能会出现句法错误。(b)有句法意识的序列生成问题。除了一组真实序列(方框左侧顶部),我们还给出了一套句法规则作为先验知识(方框右侧顶部,例如「A 7→ A, A」和「B 7→ 表名」)。在每个步骤中,生成器都遵循一个或多个预定义的规则(输出箭头中间的小方框,如「R1」、「R2」等)来构造一个序列(虚线框),该序列与实际序列相类似并且遵循语法。
为了解决上述问题,我们深入研究了在预定义的语法环境下使用 GAN 生成序列的问题。我们在图 1b 中阐述了这个问题,其中给出了一个真实序列的语料库(方框左侧顶部)和一组语法规则(方框右侧顶部)作为输入。我们的目的是学到一个生成网络 G,使其能够根据给定的语法构建高质量序列,同时通过对抗性训练模拟真实序列。我们根据著名的乔姆斯基层级(Chomsky hierarchy)[8] 将研究重点放在上下文无关语法(Context-Free Grammar,CFG)上,它可以应用于许多现有的形式语言。上下文无关语法的正式定义在本文的第二章-C 中给出。据我们所知,我们的工作是第一份致力于为序列生成任务构建一个有句法意识的 GAN 的研究工作。
虽然 GAN 在很多任务上都取得了成功,想要学习到这样一个具有句法意识的生成网络并非易事,它面临着如下挑战:
-
确保句法的正确性:保证句法正确性的困难是序列生成器与生俱来的:它依次逐个生成单词。大多数语法模型都适用一种自顶向下的结构,例如用树形结构来抽象语法信息。为了充分实现句法意识,序列生成器必须遵循一定的语法树结构。然而,语法树的结构可能有很大的区别,序列生成器不可能涵盖所有可能存在的树形结构情况。
-
跟踪不完整短语的句法状态:循环神经网络(RNN)通常在序列生成任务中被用作生成器,它在每个步骤中将生成的单词的摘要存储在其隐藏状态中。然而这样的摘要并没有跟踪部分生成的序列中的句法信息,这会导致整个序列中可能出现句法错误。为了构建一个有句法意识的生成器,我们需要建立一种机制,使 RNN 能够在生成序列时存储完整的句法信息,并跟踪当前状态。
-
有句法意识的判别器:判别器是一个 GAN 框架的关键组成部分,应该根据待研究任务的特性专门设计。DCGAN 使用了卷积神经网络(CNN)[9] 作为判别器在图像表示和生成方面取得了更好的模型性能。而 MaskGAN[6 ] 则使用了 LSTM[10] 作为判别器训练序列生成器,用来填补缺失的文本。在我们的问题中,简单地使用 LSTM 或 CNN 作为判别模型可能会遗漏关键的语法模式,这会让 GAN 框架得到一个较弱的分类器。因此,对于具有句法感知能力的序列生成任务来说,需要精心设计一个量身定做的判别器,从而对序列中丰富的语法信息进行恰当的编码,引导生成器更好地获取底层句法模式。
-
预训练:生成器和判别器通常都需要适当的预训练。然而,由于我们是首次使用 GAN 研究该问题,尚不清楚如何为有句法意识的序列生成任务设计一个合适的预训练策略。
为了解决上述问题,我们提出了一个新的 GAN 模型,称为 TreeGAN。TreeGAN 纳入了一套语法规则并且学着生成解析树,而不是直接生成序列。每棵生成的树都对应于一个序列,该序列在给定的语法下是正确的。这种方法对生成器有严格的限制,并且保证了生成序列的句法正确性。我们将在第三章-B 中详细介绍如何应用这些限制。由于 TreeGAN 的生成器生成的是树而不是普通的序列,基本的 RNN/LSTM 并不再是判别器的最佳选择。为了更好地区分假解析树(不正确的人为合成的解析树)和真解析树,我们在对抗训练中使用 TreeLSTM [11] 指导树生成器,本文的第三章-C 将会介绍详细细节。相应的预训练策略将在第三章-D 中讨论。现将本文的贡献总结如下:
-
我们将序列生成任务转化为解析树生成任务,从而有效地引入结构化的信息。我们说明了在一个上下文无关句法环境下的序列可以被转换为相应的解析树,这在 TreeGAN 中被用于指导生成器生成真实的解析树。
-
我们提出了一个树生成器,它使用 LSTM 生成遵循预定义的上下文无关语法的解析树。
-
我们提出了一个名为 TreeGAN 的对抗训练框架,其中使用树结构的 LSTM 模型 [11] 作为判别器指导树生成器构建解析树。
-
在合成数据集和真实数据集上进行的大量实验表明,本文提出的 TreeGAN 框架可以根据预定义的上下文无关语法生成高质量的文本/序列。
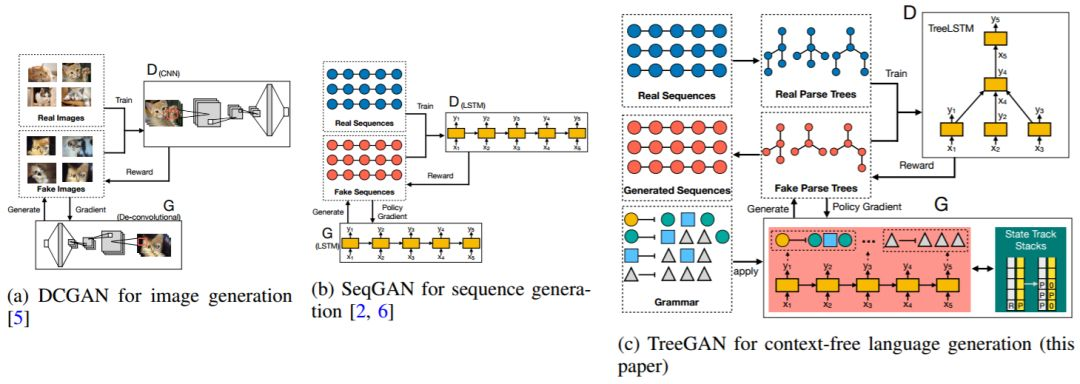
图 2: 相关的 GAN 模型的对比。「D」代表 GAN 模型的判别器,「G」代表生成器。(a)DCGAN[5](b)MaskGAN[6](c)TreeGAN(本文提出的模型)
论文:TreeGAN: Syntax-Aware Sequence Generation with Generative Adversarial Networks

论文链接:https://arxiv.org/abs/1808.07582
生成对抗网络(GAN)在图像生成领域表现出了很强的能力,GAN 框架中有一个指导生成器模型进行训练的判别器模型,从而构建与真实图像极为相似的图像。最近,GAN 从图像生成领域扩展到了序列生成领域(例如,诗歌、音乐和代码)。用于序列生成的现有 GAN 主要关注的是一些语法无关的一般序列。然而,在许多实际应用程序中,我们需要生成一种形式语言的序列,并受相应语法的约束。例如,为了测试数据库的性能,可能需要生成一组 SQL 查询语句,这些查询不仅需要与真实的用户查询相类似,还需要遵循目标数据库的 SQL 句法。生成这样的序列非常具有挑战性,因为 GAN 的生成器和判别器都需要考虑序列的结构和形式语言中给定的语法。为了解决这些问题,我们研究了通过 GAN 实现的有句法意识的序列生成问题,在该问题中,判别器和生成器同时获得了一组真实序列和一组预定义的语法规则。我们提出了一个新的 GAN 框架,即 TreeGAN,将给定的上下文无关文法(CFG)融入序列生成过程中。在 TreeGAN 中,生成器使用循环神经网络(RNN)来构造解析树。然后,可以将每个生成的解析树转换为给定语法的正确序列。判别器使用树结构的 RNN 来区分生成的树和真实的树。我们证明了 TreeGAN 可以为任何 CFG 生成序列,它的生成完全符合给定的句法。在合成和真实数据集上的实验表明,TreeGAN 显著提高了上下文无关语言中序列生成的质量。
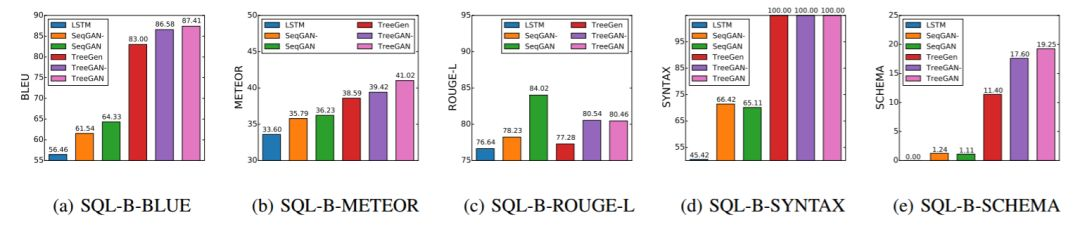
图 7:在 SQL-B 上进行的定量分析

表 3:SQL—B 中的 SQL 查询语句生成结果。句法错误用红字标注。
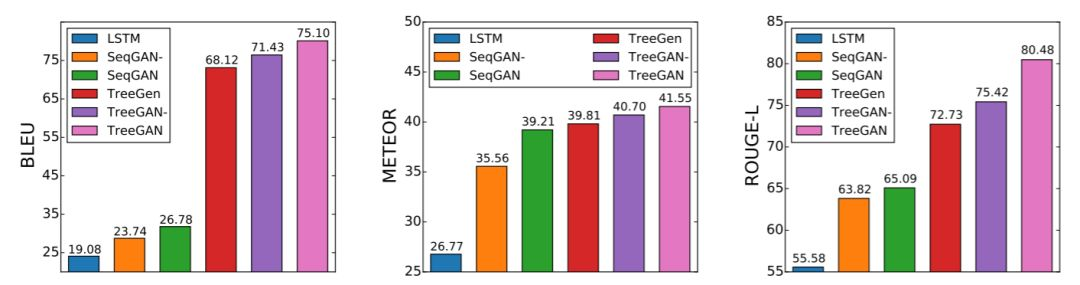
图 8:在 Django 上进行的定量分析

表 4:Django 中生成的 Python 代码。句法错误用红字标注。
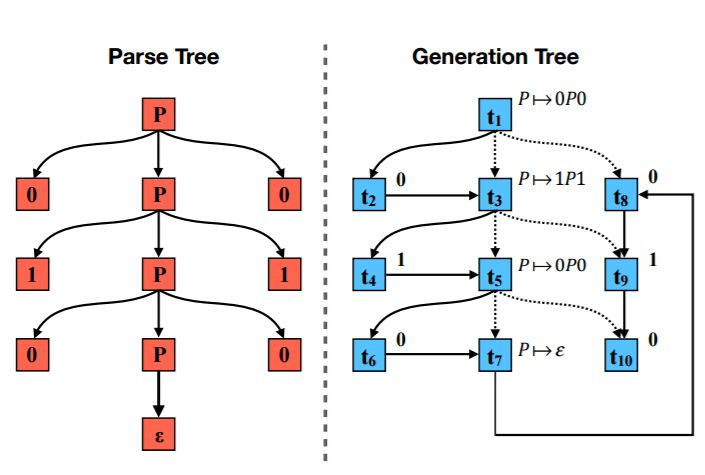
图 3:左图:序列「010010」的解析树。右图:用于生成左图所示的解析树的动作序列。实线箭头表示动作流的时间顺序,虚线肩头表示上一层嵌入的输入(参见第三章-B)
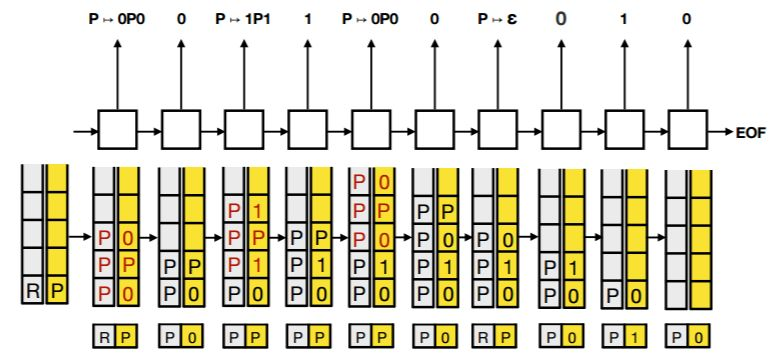
图 4: 图 3 所示的解析树的生成过程。生成器维护了一个父栈(灰色的列)和一个子栈(黄色的列),当前节点(子栈下方的黄色方框)及其父节点(灰色方框)在每个生成步骤中分别从两个栈中弹出。栈中的红色元素指的是在每一步中压入栈的元素。当两个栈都为空时停止序列生成。
本文为机器之心编译,转载请联系本公众号获得授权 。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
