字典树
在计算机科学中, 字典树(trie,中文又被称为”单词查找树“或 ”键树“), 也称为数字树,有时候也被称为基数树或前缀树(因为它们可以通过前缀搜索), 它是一种搜索树--一种已排序的数据结构,通常用于存储动态集或键为字符串的关联数组。
与二叉搜索树不同, 树上没有节点存储与该节点关联的键; 相反,节点在树上的位置定义了与之关联的键。 一个节点的全部后代节点都有一个与该节点关联的通用的字符串前缀, 与根节点关联的是空字符串。 值对于字典树中关联的节点来说,不是必需的,相反,值往往和相关的叶子相关,以及与一些键相关的内部节点相关。 有关字典树的空间优化示意,请参阅紧凑前缀树
图
在计算机科学中, 图(graph) 是一种抽象数据类型, 旨在实现数学中的无向图和有向图概念,特别是图论领域。 一个图数据结构是一个(由有限个或者可变数量的)顶点/节点/点和边构成的有限集。 如果顶点对之间是无序的,称为无序图,否则称为有序图; 如果顶点对之间的边是没有方向的,称为无向图,否则称为有向图; 如果顶点对之间的边是有权重的,该图可称为加权图。
哈希表
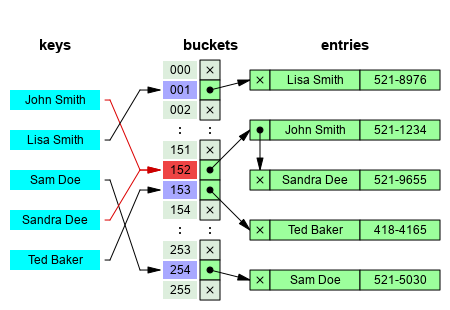
在计算中, 一个 哈希表(hash table 或hash map) 是一种实现 关联数组(associative array) 的抽象数据;类型, 该结构可以将 键映射到值。
哈希表使用 哈希函数/散列函数 来计算一个值在数组或桶(buckets)中或槽(slots)中对应的索引,可使用该索引找到所需的值。
理想情况下,散列函数将为每个键分配给一个唯一的桶(bucket),但是大多数哈希表设计采用不完美的散列函数,这可能会导致"哈希冲突(hash collisions)",也就是散列函数为多个键(key)生成了相同的索引,这种碰撞必须 以某种方式进行处理。
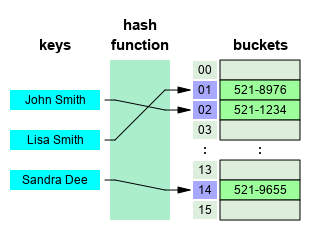
通过单独的链接解决哈希冲突
堆 (数据结构)
在计算机科学中, 一个 ** 堆(heap)** 是一种特殊的基于树的数据结构,它满足下面描述的堆属性。
在一个 最小堆(min heap) 中, 如果 P 是 C 的一个父级节点, 那么 P 的key(或value)应小于或等于 C 的对应值.
在一个 最大堆(max heap) 中, P 的key(或value)大于 C 的对应值。
在堆“顶部”的没有父级节点的节点,被称之为根节点。
双向链表
在计算机科学中, 一个 双向链表(doubly linked list) 是由一组称为节点的顺序链接记录组成的链接数据结构。每个节点包含两个字段,称为链接,它们是对节点序列中上一个节点和下一个节点的引用。开始节点和结束节点的上一个链接和下一个链接分别指向某种终止节点,通常是前哨节点或null,以方便遍历列表。如果只有一个前哨节点,则列表通过前哨节点循环链接。它可以被概念化为两个由相同数据项组成的单链表,但顺序相反。

两个节点链接允许在任一方向上遍历列表。
在双向链表中进行添加或者删除节点时,需做的链接更改要比单向链表复杂得多。这种操作在单向链表中更简单高效,因为不需要关注一个节点(除第一个和最后一个节点以外的节点)的两个链接,而只需要关注一个链接即可。
基础操作的伪代码
插入
Add(value)
Pre: value is the value to add to the list
Post: value has been placed at the tail of the list
n ← node(value)
if head = ø
head ← n
tail ← n
else
n.previous ← tail
tail.next ← n
tail ← n
end if
end Add
删除
Remove(head, value)
Pre: head is the head node in the list
value is the value to remove from the list
Post: value is removed from the list, true; otherwise false
if head = ø
return false
end if
if value = head.value
if head = tail
head ← ø
tail ← ø
else
head ← head.Next
head.previous ← ø
end if
return true
end if
n ← head.next
while n = ø and value = n.value
n ← n.next
end while
if n = tail
tail ← tail.previous
tail.next ← ø
return true
else if n = ø
n.previous.next ← n.next
n.next.previous ← n.previous
return true
end if
return false
end Remove
反向遍历
ReverseTraversal(tail)
Pre: tail is the node of the list to traverse
Post: the list has been traversed in reverse order
n ← tail
while n = ø
yield n.value
n ← n.previous
end while
end Reverse Traversal
复杂度
时间复杂度
| Access | Search | Insertion | Deletion |
|---|---|---|---|
| O(n) | O(n) | O(1) | O(1) |
空间复杂度
O(n)
链表
在计算机科学中, 一个 链表 是数据元素的线性集合, 元素的线性顺序不是由它们在内存中的物理位置给出的。 相反, 每个元素指向下一个元素。它是由一组节点组成的数据结构,这些节点一起,表示序列。
在最简单的形式下,每个节点由数据和到序列中下一个节点的引用(换句话说,链接)组成。这种结构允许在迭代期间有效地从序列中的任何位置插入或删除元素。
更复杂的变体添加额外的链接,允许有效地插入或删除任意元素引用。链表的一个缺点是访问时间是线性的(而且难以管道化)。
更快的访问,如随机访问,是不可行的。与链表相比,数组具有更好的缓存位置。

基本操作的伪代码
插入
Add(value)
Pre: value is the value to add to the list
Post: value has been placed at the tail of the list
n ← node(value)
if head = ø
head ← n
tail ← n
else
tail.next ← n
tail ← n
end if
end Add
搜索
Contains(head, value)
Pre: head is the head node in the list
value is the value to search for
Post: the item is either in the linked list, true; otherwise false
n ← head
while n != ø and n.value != value
n ← n.next
end while
if n = ø
return false
end if
return true
end Contains
删除
Remove(head, value)
Pre: head is the head node in the list
value is the value to remove from the list
Post: value is removed from the list, true, otherwise false
if head = ø
return false
end if
n ← head
if n.value = value
if head = tail
head ← ø
tail ← ø
else
head ← head.next
end if
return true
end if
while n.next = ø and n.next.value = value
n ← n.next
end while
if n.next = ø
if n.next = tail
tail ← n
end if
n.next ← n.next.next
return true
end if
return false
end Remove
遍历
Traverse(head)
Pre: head is the head node in the list
Post: the items in the list have been traversed
n ← head
while n = 0
yield n.value
n ← n.next
end while
end Traverse
反向遍历
ReverseTraversal(head, tail)
Pre: head and tail belong to the same list
Post: the items in the list have been traversed in reverse order
if tail = ø
curr ← tail
while curr = head
prev ← head
while prev.next = curr
prev ← prev.next
end while
yield curr.value
curr ← prev
end while
yeild curr.value
end if
end ReverseTraversal
复杂度
时间复杂度
| Access | Search | Insertion | Deletion |
|---|---|---|---|
| O(n) | O(n) | O(1) | O(1) |
空间复杂度
O(n)
优先队列
在计算机科学中, 优先级队列(priority queue) 是一种抽象数据类型, 它类似于常规的队列或栈, 但每个元素都有与之关联的“优先级”。
在优先队列中, 低优先级的元素之前前面应该是高优先级的元素。 如果两个元素具有相同的优先级, 则根据它们在队列中的顺序是它们的出现顺序即可。
优先队列虽通常用堆来实现,但它在概念上与堆不同。优先队列是一个抽象概念,就像“列表”或“图”这样的抽象概念一样;
正如列表可以用链表或数组实现一样,优先队列可以用堆或各种其他方法实现,例如无序数组。
队列
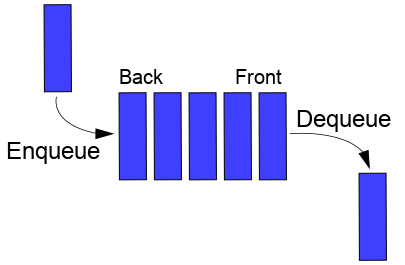
在计算机科学中, 一个 队列(queue) 是一种特殊类型的抽象数据类型或集合。集合中的实体按顺序保存。
队列基本操作有两种: 向队列的后端位置添加实体,称为入队,并从队列的前端位置移除实体,称为出队。
队列中元素先进先出 FIFO (first in, first out)的示意
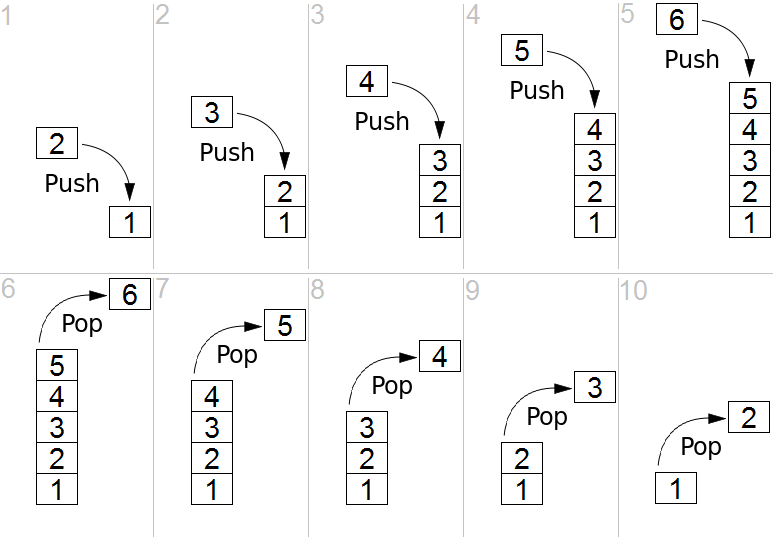
栈
在计算机科学中, 一个 栈(stack) 时一种抽象数据类型,用作表示元素的集合,具有两种主要操作:
- push, 添加元素到栈的顶端(末尾);
- pop, 移除栈最顶端(末尾)的元素.
以上两种操作可以简单概括为“后进先出(LIFO = last in, first out)”。
此外,应有一个 peek 操作用于访问栈当前顶端(末尾)的元素。
"栈"这个名称,可类比于一组物体的堆叠(一摞书,一摞盘子之类的)。
栈的 push 和 pop 操作的示意
树
- 二叉搜索树
- AVL 树
- 红黑树
- 线段树 - with min/max/sum range queries examples
- 芬威克树/Fenwick Tree (Binary Indexed Tree)
在计算机科学中, 树(tree) 是一种广泛使用的抽象数据类型(ADT)— 或实现此 ADT 的数据结构 — 模拟分层树结构, 具有根节点和有父节点的子树,表示为一组链接节点。
树可以被(本地地)递归定义为一个(始于一个根节点的)节点集, 每个节点都是一个包含了值的数据结构, 除了值,还有该节点的节点引用列表(子节点)一起。 树的节点之间没有引用重复的约束。
一棵简单的无序树; 在下图中:
标记为 7 的节点具有两个子节点, 标记为 2 和 6; 一个父节点,标记为 2,作为根节点, 在顶部,没有父节点。