

Javascript中的事件循环
javascript是一门单线程的非阻塞的脚本语言。单线程,即js代码在执行的任何时候,都只有一个主线程来处理所有任务。非阻塞,只要指的是执行异步任务(如I/O事件)时,主线程会挂起这个任务,然后在异步任务返回结果的时候再按照一定规则执行相应的回调。
Web worker 技术所实现的多线程技术也存在诸多限制。如,所有新线程都受到主线程的完全控制,不能独立执行。这意味着这些‘线程’实际上是主线程的子线程。另外,这些子线程没有执行I/O操作的权限,只能为主线程分担一些如计算等任务。所以严格来讲,web worker并没有改变javascript的单线程本质。
- 执行栈和同步执行
执行栈与存储对象指针和基础类型变量的栈是不同的。执行栈是指,当调用一个方法时,js会生成与这个方法对应的一个执行环境(context),即执行上下文。这个执行环境中包含:这个执行环境的私有作用域、上层作用域的指向,方法的参数,私有变量以及该作用域的this指向。因为js是单线程的,同一时间只能执行一个方法,也就是说,当一个方法被执行的时候,其他方法会被排队到一个单独的地方,即执行栈。
当一个脚本第一次执行的时候,js引擎会解析这段代码,并将其中的同步代码按照执行顺序加入执行栈,然后从头开始执行。当执行一个方法时,js会向执行栈中添加这个方法的执行环境,然后进入这个执行环境继续执行其中的代码。当这个执行环境中的代码执行完毕并返回结果后,js会退出当前执行环境并撤销该环境,回到上一个方法的执行环境,这个过程反复执行,知道执行栈中的代码全部执行完毕。
案列1:
function Func1 () {
console.log(1)
function Func2 () {
console.log(2)
function Func3 () {
console.log(3)
}
Func3()
}
Func2()
}
Func1()
// 1 2 3
同步执行遵循先进后出的规则,在执行Func1时,会向执行栈加入该方法的执行环境,输出1,然后解析了Func2,执行时加入了Func2的执行环境,输出2,然后解析Func3并执行,输出3,Func3执行完毕后会撤销Func3的执行环境,接着是Func2执行完毕并撤销Func2的执行环境,最后撤销Func1的执行环境。该过程若没有终止,会无限进行直到栈溢出。
- 异步执行
方法执行时,异步执行事件挂起加入与执行栈不同的另一个队列,即事件队列中,并继续执行执行栈中的其他任务。被放入事件队列不会立即执行其回调,而是等待当前执行栈中的所有任务执行完毕,在主线程出于闲置状态时,主线程会查找事件队列是否有任务。如果有,则会取第一个事件并将该事件的回调放入执行栈中执行,然后执行其中的同步代码,如此反复就是事件循环。
异步任务因为各任务的不同和执行优先级的区别,分为 宏任务 (macro task) 和 微任务 (micro task)
属于宏任务的事件:setTimeout(), setInterval()
属于微任务的事件:new Promise(), new MutaionObserver()(已废除)
当执行栈为空时,主线程会优先查看微任务是否有事件。如果没有,就会执行宏任务中的第一个事件并将对应的回调加入当前执行栈中;如果有,就会依次执行微任务中事件对应的回调,直到微任务队列为空,然后再执行宏任务中的第一个事件对应的回调,如此反复,进入循环。同一次事件循环中,微任务永远优先宏任务执行。
案列2:
setTimeout(function ()
{
console.log(1);
});
new
Promise(function(resolve,reject){
console.log(2)
resolve(3)
}).then(function(val){
console.log(val);
})
// 2 3 1
node环境下的事件循环
在node中,事件循环与浏览器中的略有不同。node中的事件循环的实现是依靠的libuv引擎。node选用chrome的v8引擎作为解释器,v8引擎将js代码解析后会调用node api,而api则是由libuv引擎驱动,因此node中的事件循环是在libuv引擎中执行。
node中,同步代码执行完,会先清空微任务队列,轮询时会清空当前队列所有任务,才会切换到下一个队列,在切换下一个队列之前也会先清空微任务队列。
- 事件循环模型
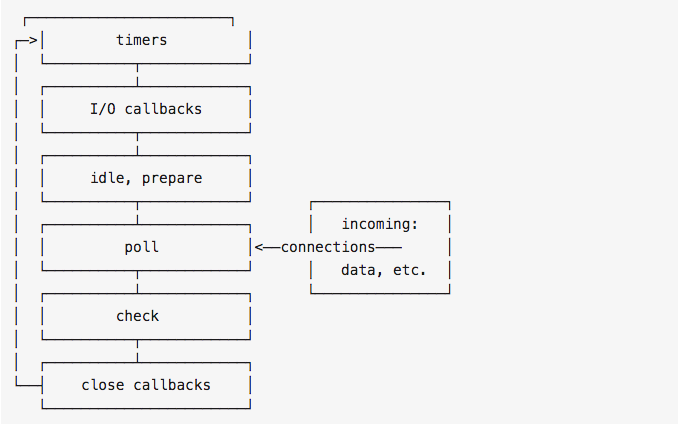
(来自:node官网)
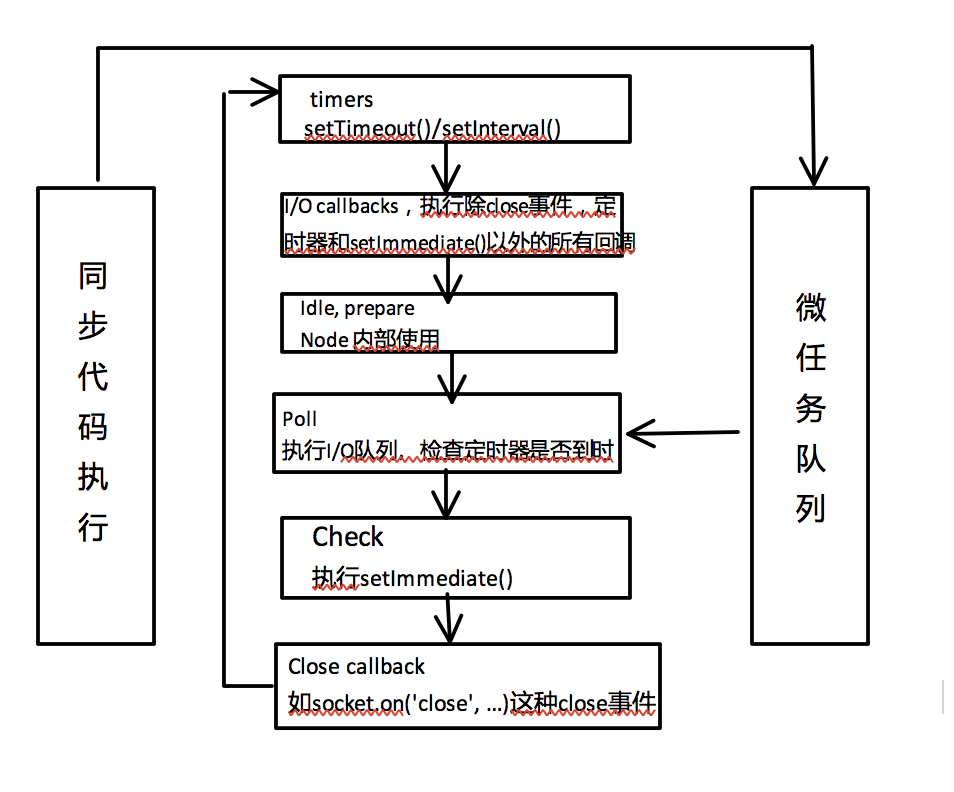
- 事件循环说明
node的事件循环顺序:
外部输入数据—>poll阶段—>检查阶段(check)—>关闭事件回调阶段(close callback)—>定时器检测执行阶段(timers)—>I/O事件回调阶段(I/O callbacks)—>idle,prepare—>poll…
setTimeout(() => {console.log('setTimeout')} , 0)
setImmediate(() => {console.log('immediate')})
默认情况下setTimeout()和 setImmediate()不知道哪一个会先执行,node执行也需要准备时间。setTimeout()延迟时间设置为0,实际还是有4ms的延迟,假设node准备时间在4ms内,定时器没有执行,poll阶段没有执行setTimeout(),会先执行check中的setImmediate(),等到下一轮询进入时,poll检测到定时器已到时,再执行timer中的setTimeout()
队列中有一个特殊的推迟任务执行的方法process.nextTick再此执行。我们知道,每一次事件循环都是从微任务开始的,并且每一阶段都是按照事件循环顺序进行执行。而在每一次的队列切换之前,都会检查nextTick queue中是否有事件,若有则优先执行。
案列3:
setImmediate(() => {
console.log("setImmediate1");
setTimeout(() => {
console.log("setTimeout1");
}, 0);
});
setTimeout(() => {
process.nextTick(() => console.log("nextTick"));
console.log("setTimeout2");
setImmediate(() => {
console.log("setImmediate2");
});
}, 0);
// 结果一
// setImmediate1, setTimeout2, setTimeout1, nextTick, setImmediate2
// 结果二
// setTimeout2, nextTick, setImmediate1, setImmediate2, setTimeout1
产生上面两种结果的原因,是node准备时间的差异。
案例4:
const fs = require('fs');
fs.readFile(__filename, () => {
setImmediate(() => {
console.log("setImmediate1");
setTimeout(() => {
console.log("setTimeout1");
}, 0);
});
setTimeout(() => {
process.nextTick(() => console.log("nextTick"));
console.log("setTimeout2");
setImmediate(() => {
console.log("setImmediate2");
});
}, 0);
});
// setImmediate1, setTimeout2, setTimeout1, nextTick, setImmediate2
此时只会有一种结果,因为是在一个I/O事件的回调中,node准备已结束,setTimeout执行需要等待4ms,setImmediate则立即执行,又setTimeout2和setTimeout1在同一个timers队列中所以按顺序执行,之后需要切换到check队列执行setImmediate2,在切换之前会先检查nextTick队列并执行,因此最后输出nextTick,setImmediate2
注:欢迎大家监督指导,如有疑问或错误,请留言一起探讨~~
