

碎碎念
在大一学习C语言的时候,举过一个用栈实现的括号匹配算法,当时觉得很难,不过现在回顾起来,这个算法也算是比较简单的一个关于栈的应用了。而现在所常见的算法问题也都是什么中缀表达式转后缀表达式,双栈找最小值之类的。难度比之括号匹配稍有提升,不过倒也算是必须要掌握的算法。
上述所说的表达式求值在程序设计语言中是一个最基本的问题,也是栈的实现的一个典型范例。
为什么说是最基本? 我们知道,中缀表达式对于人来说是比较友好的,学过四则运算就可以对其求值,然而对于计算机来说,虽然也可以想办法计算,但是却算不上友好了;相反,后缀表达式虽然对人不友好,但是却是计算机所喜欢的。
(话说,后缀表达式在编译原理中的重要性也是能栖身前列的。)
栈
在C语言入门的时候,我们就会通过递归来求斐波那契数列,很简单:
int fibonacci(int n) {
if (n==0 || n==1) return 1;
return fibonacci(n-1) + fibonacci(n-2);
}
但是那时候还不懂原理,仅仅知道,递归就是函数调用其本身,但是接触到数据结构的时候,再一次提出了递归的概念。
什么是递归?递归就是函数调用其本身。
reverse(know) { // 1. go on
if (you know) return you know; // 2. look 4
else back to see the 1; // 3. go back to 1.
} // 4. you know what is recurision now.
这时候,我们不仅知道递归真正的用法,同时也知道了一个事实,即递归程序的开销通常很大,但与之相反的,其代码量又是非常少的。
通常情况下,我们会选择将递归程序改写成非递归程序,即所谓消除递归,但是当改写后和改写前的程序并不会有太大的性能提升,我们也没有必要去改写,比如:cout << fibonacci(5); ,为了这样的调用去消除递归,有必要吗?
可实际情况是,一个应用所要处理的数据并不算小,消除递归是不可避免的。
递归的精髓在于能否将原始的问题转换为属性相同,但问题规模较小的问题,学过算法就知道,这同样也是贪心策略和动态规划的本质。
优化
对于递归程序的优化,我们通常会选择栈做辅助,为什么?我们知道,在操作系统中,有一种叫做**“函数调用堆栈”**的名词,大概的解释就是:当在某一函数A中调用另一函数B时,我们将A中的内容保存后,压入系统堆栈(你可以说这是在创建还原点,也可以说这个是现场保护,开心就好。),然后执行函数B的内容,当函数B执行结束后,将A从系统堆栈中弹出,继续从断点处执行,同时销毁之前申请的栈空间。
同时,我们要知道,操作系统的主存是由空间上限的,不可能是无限的。系统堆栈的大小自然是受操作系统存储空间大小的约束的,而且绝对小于系统存储空间(不可能等于)。所以,当递归程序不断申请栈空间到达系统栈所能分配的上限时,就有了所谓的“系统堆栈溢出”,即我们通常所说的“爆栈”。
- 斐波那契函数n=6时,递归调用树
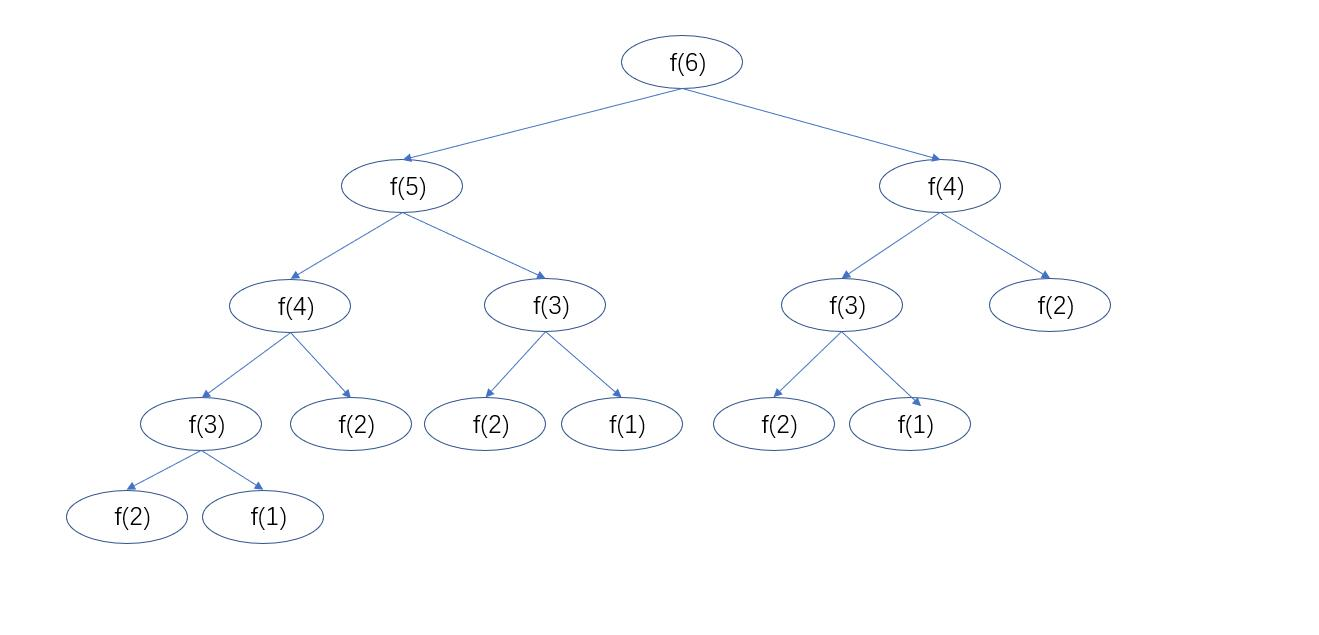
-
n=3时,栈的申请情况
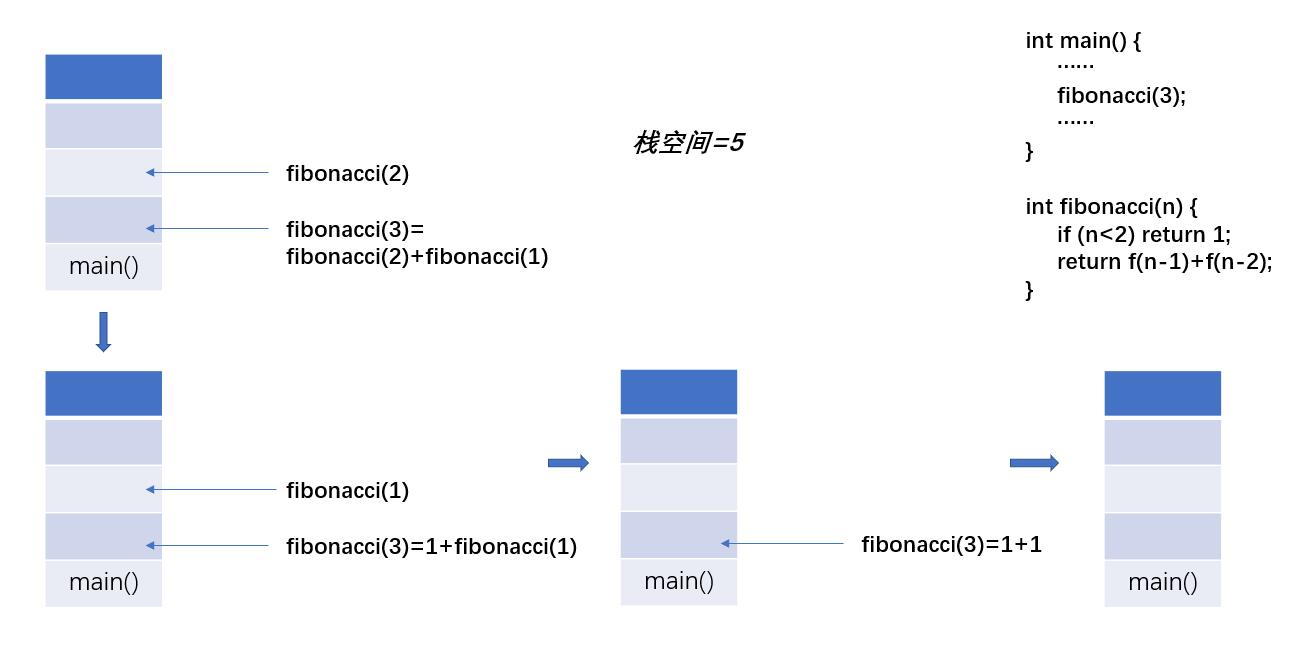
-
n=6时,栈的申请情况
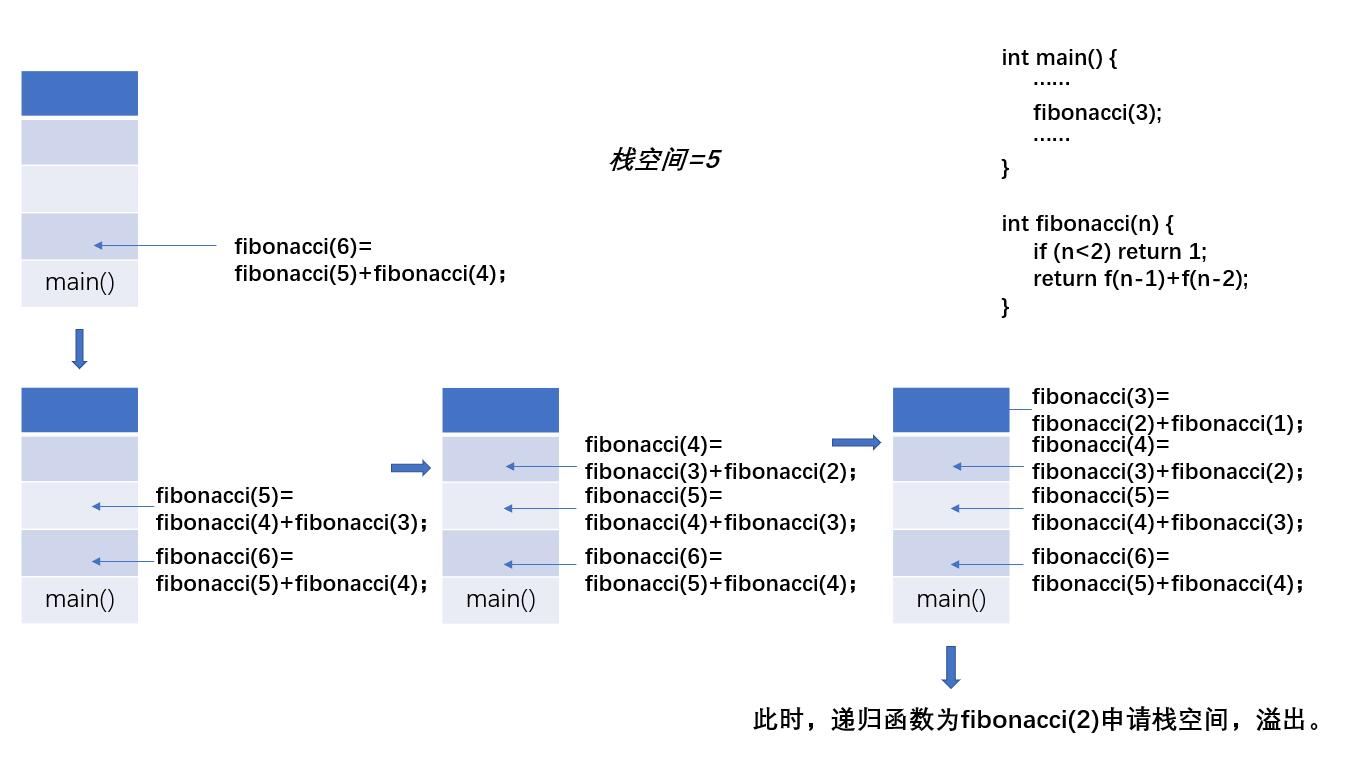
java中,异常java.lang.StackOverflowError就是一种堆栈溢出错误,不过,可以通过修改JVM参数来增大虚拟机栈空间,如-vm args-Xss128k;但这也只是权宜之计,治标不治本呐。
但是呢,一个递归程序并不一定非要用栈辅助改写成非递归程序(即消除递归),有时候,一个循环就够了。
int main() {
int n, i=j=1, tmp=0;
cin >> n;
while (n--) {
tmp = i+j;
i = j;
j = tmp;
}
}
暂时就说这么多,至于后面的,那就后面再说吧,毕竟这也只是(一)嘛。
