

这篇我们继续深入来看看在存储格式的演变之上有什么新的黑科技。华为公司在2016年开源了类parquet的列存格式:CarbonData,并且贡献给了Apache社区。CarbonData仅仅用了不到一年的时间就成功毕业,成为了Apache社区的顶级项目,CarbonData是首个由华人公司主导的Apache顶级项目,(来源自eBay的Kylin算是首个由华人主导的顶级开源项目)笔者这里还是要向华为的小伙伴们致敬,能够完成这样一个从0到1的突破。
本篇笔者尝试从技术细节来梳理CarbonData与其“前辈”到底有何不同之处,我们在实际应用与设计存储格式时有什么可以借鉴汲取之处。
首先我们来看看CarbonData本身的定位,如下图所示: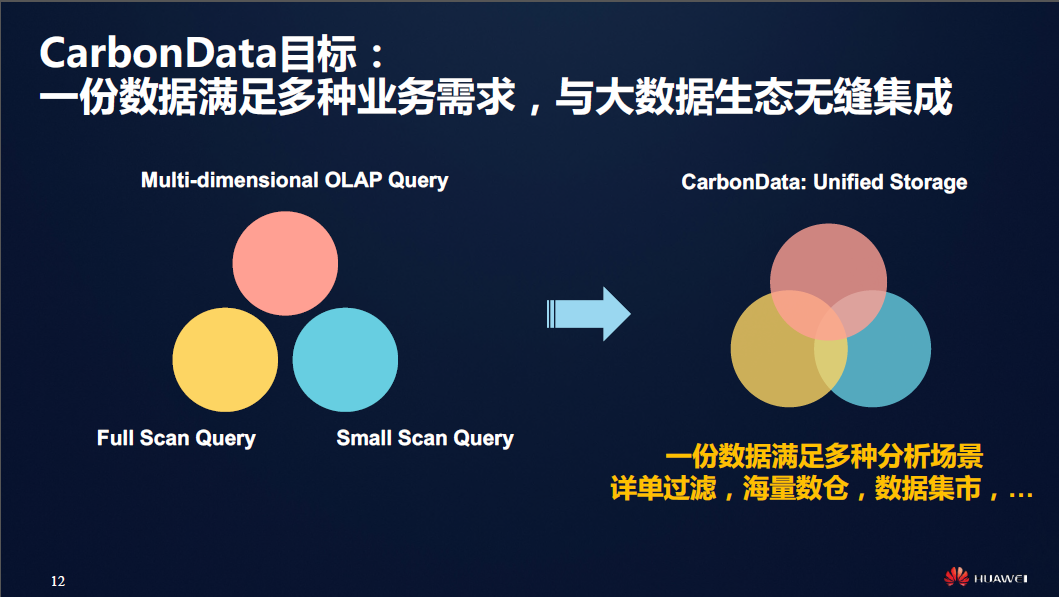
·1、支持海量数据扫描并取其中几列;
·2、支持根据主键进行查找,并在秒级响应;
·3、支持在海量数据进行类似于OLAP的交互式查询,并且查询中涉及到许多过滤条件,这种类型的workload应该在几秒钟内响应;
·4、支持快速地抽取单独的记录,并且从该记录中获取到所有列信息;
·5、支持HDFS,无缝对接Hadoop生态圈,天生带有分布式基因。
对于OLAP查询来说,存在多种不同类型的查询,存储结构的不同会影响到不同查询的数据表现。所以CarbonData的定位是作为一种通用的查询存储数据,通过Spark SQL来解决海量查询的问题,并且能够与Hadoop生态圈进行无缝对接。CarbonData最初的应用是与Spark SQL和Spark DataFrame深度结合,后续由携程团队将CarbonData引入了Presto,滴滴团队将CarbonData引入Hive。
其实无论是多维的OLAP查询,还是完整的扫描查询,还是部分范围查询。CarbonData的前辈ORCFile与Parquet都可以同样完成任务,那么作为新人,CarbonData有什么过人之处呢?
下图是华为提供进行实测的数据,在绝大多数的测试场景之中CarbonData的性能都略优于Parquet。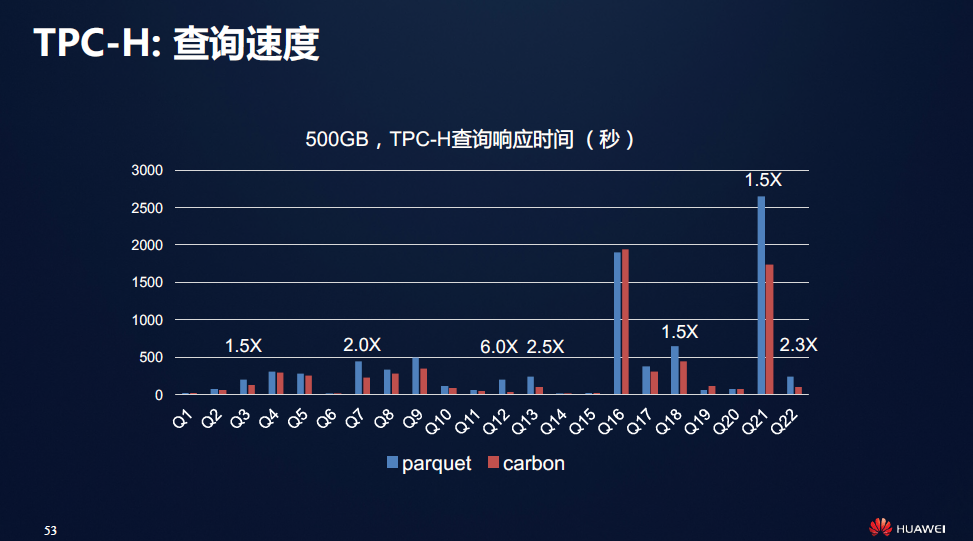
当然快速的查询是需要付出代价的,查询的快速所牺牲的是压缩率的减小与入库时间的延长。
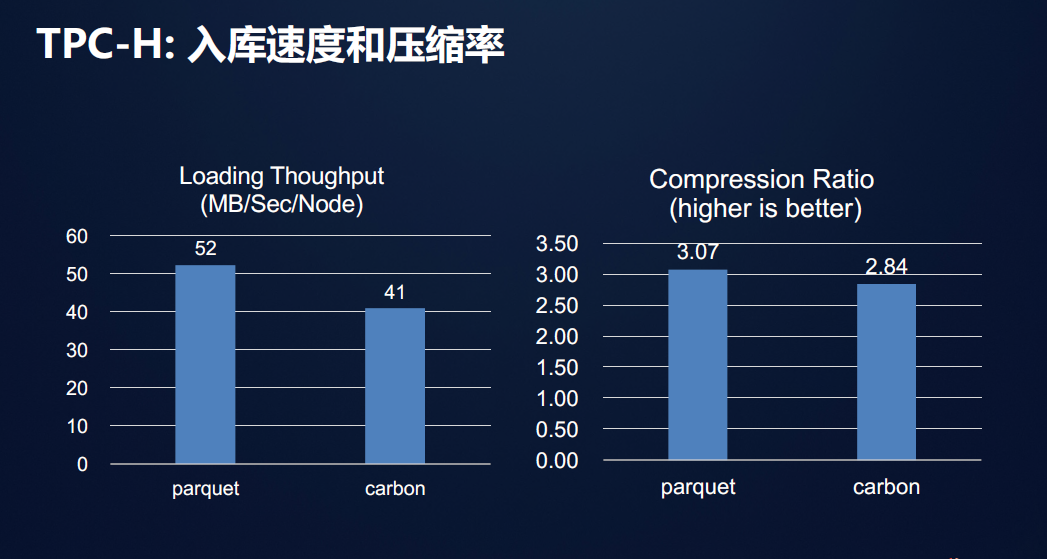
那我们接下来就是要详尽讨论CarbonData的性能表现与底层设计之间的逻辑关系。
下图展示了CarbonData的数据存储格式: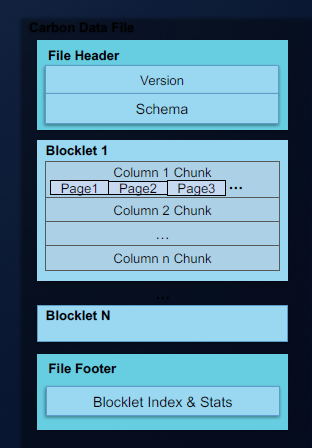
·File Header
文件头的格式比较简单,保存了存储格式的版本和模式信息。(这部分通常是稳定不可变的内容)
·Blocklet
单Blocklet最大的容量阀值为64M,也就是说单个HDFS的Block可以容纳多个Blocklet(视Block的大小而定)。这块内容与ORCFile与Parquet的设计一脉相承,都是利用Pax的存储模型来优化数据查询时的性能表现。
·File Footer
在文件尾部保存了存储数据的索引和摘要,索引是CarbonData最为核心的关键实现,正是由于索引的存在,大大提高了CarbonData在不同查询场景之下的性能表现。
CarbonData通过支持了二级索引,大大的提高了CarbonData数据查询的性能表现。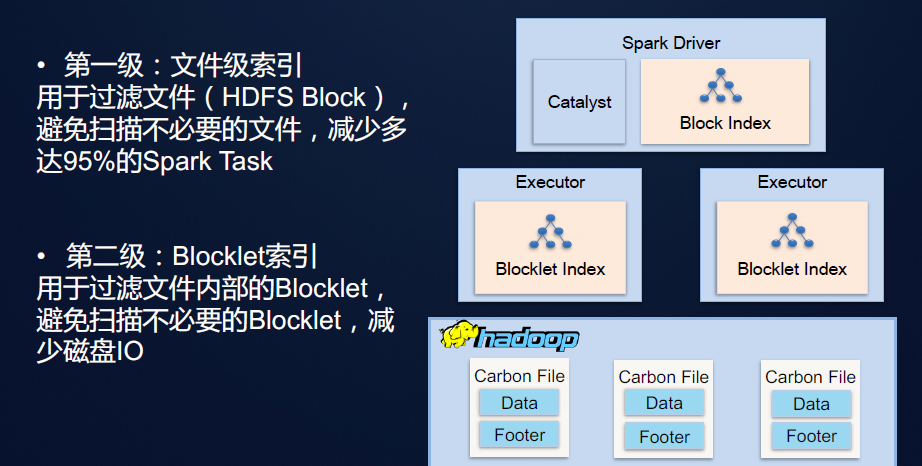
由上图所示CarbonData在HDFS Block级别与内部的Blocklet级别都分别建立起索引,这样可以大大减少非必要的任务启动与非必要的磁盘IO操作。众所周知,引入索引的的确确能够加快数据的查询速率,但是天下没有免费的午餐。我想CarbonData压缩率缩减与数据导入时间的延长的原因,想必读者心中也有了答案。
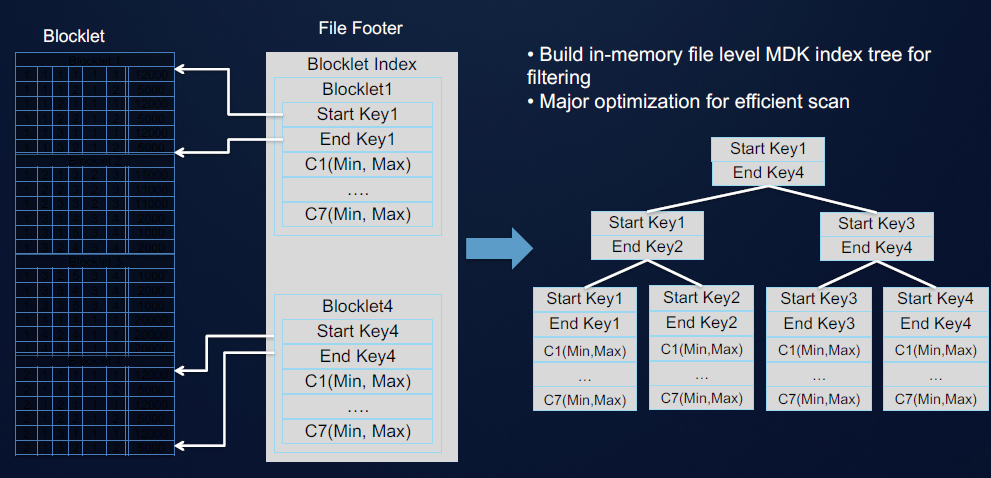
我们可以看到在CarbonData的文件尾部,通过B+树的方式来实现索引。由于HDFS追加写的特性,所以我想读者应该也能明白为何这些索引数据与统计数据需要存放在CarbonData的末尾。
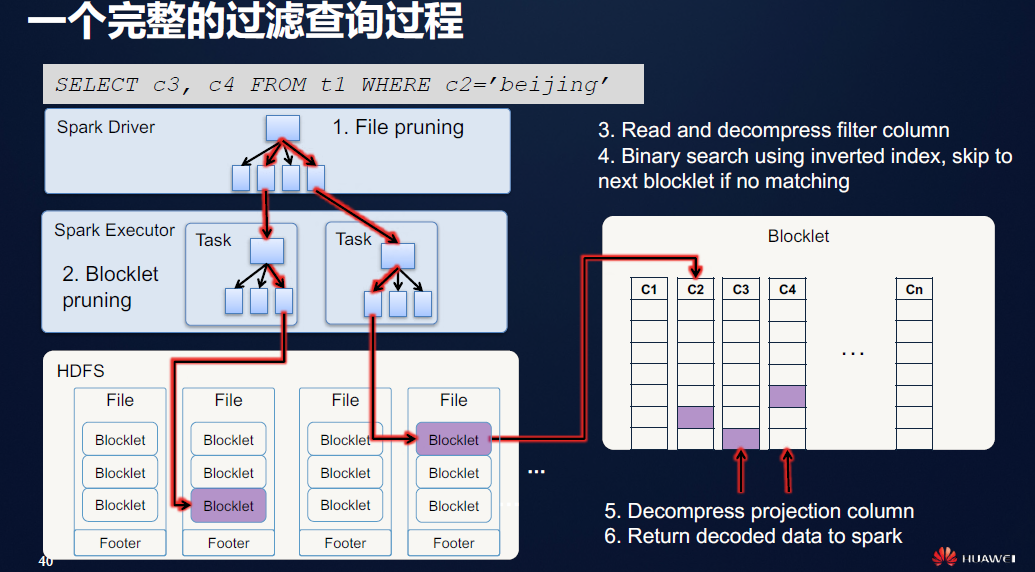
上图完整的展现了一次过滤查询的流程,这个过程在二级索引的作用之下,规避了大量非必要的查询交互,由此带来的性能优化是十分明显的。
相对于ORCFile与Parquet相对简要的摘要索引,CarbonData在索引层面颇费心思。通过这样的方式来超越前辈,当然这样的选择设计同样也要付出额外的代价。
这是CarbonData之中颇具争议的功能,在CarbonData之前的版本是默认添加的内容,目前在1.3版本之中是作为可选项加入其中的。(笔者在华为高斯部门工作的师兄也曾经和笔者吐槽过在生产环境之中,全局字典编码的似乎还存在一些'坑')所以看起来能够运用好字典编码的确是个值得探讨的问题,笔者在此也简单聊一聊:

如上图所示,全局字典编码的方式很简单,就是通过数字和字典来替换表格之中重复出现的数据。这样的好处很明显:
·大大减少了表格数据所需要存储的数据量
·某些需要进行group by的字段进行全局字典编码,可以大量减少计算时的shuffle的数据量。以达到性能提升的目的。
但是在将数据导入CarbonData的过程之中,对与重复率较低的列,一旦建立起全局字典,显然会大大拖慢数据的导入速度,并且影响数据的压缩程度。而如果对于数据重复率较高的数据,例如性别,年龄等高重复数据,通过建立全局字典能够大大提升CarbonData的压缩程度,并且对数据导入的速率影响不大。
笔者建议:对于字典编码的使用,还是要根据具体也业务场景进行分析压测,给出较为合适的使用方式,盲目使用字典编码反而会对性能带来负优化。
到此为止,笔者也大致聊完了对CarbonData存储结构的理解以及笔者在简单实践之中所引发的思考。作为华人圈子之中首个由华人公司主导的Apache的顶级项目,笔者也会继续对CarbonData进行关注与学习,也希望将来华人程序员能够在开源圈之中继续扩大影响力。
