

简介
介绍可用于实现多种非配对图像翻译任务的CycleGAN模型,并完成性别转换任务
原理
和pix2pix不同,CycleGAN不需要严格配对的图片,只需要两类(domain)即可,例如一个文件夹都是苹果图片,另一个文件夹都是橘子图片
使用A和B两类图片,就可以实现A到B的翻译和B到A的翻译
论文官方网站上提供了详细的例子和介绍,junyanz.github.io/CycleGAN/,例如苹果和橘子、马和斑马、夏天和冬天、照片和艺术作品等

以及论文的官方Github项目,github.com/junyanz/Cyc…,使用PyTorch实现
CycleGAN由两个生成器G和F,以及两个判别器Dx和Dy组成
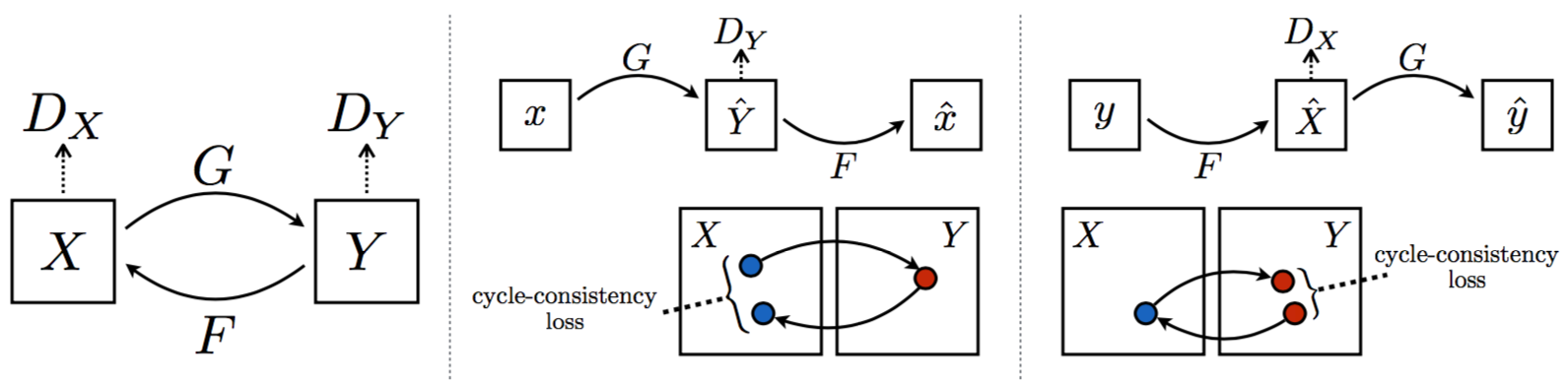
G接受真的X并输出假的Y,即完成X到Y的翻译;F接受真的Y并输出假的X,即完成Y到X的翻译;Dx接受真假X并进行判别,Dy接受真假Y并进行判别
CycleGAN的损失函数和标准GAN差不多,只是写两套而已
除此之外,为了避免mode collasp问题,CycleGAN还考虑了循环一致损失(Cycle Consistency Loss)
因此CycleGAN的总损失如下,G、F、Dx、Dy分别需要min、max其中的部分损失项
实现
在论文的具体实现中,使用了两个tricks
- 使用Least-Square Loss即最小平方误差代替标准的GAN损失
- 以G为例,维护一个历史假Y图片集合,例如50张。每次G生成假Y之后将其加到集合中,再从集合中随机地取出一张假Y,和一张真Y一起输入给判别器进行判别。这样一来,假Y集合代表了G根据X生成Y的平均能力,使得训练更加稳定
使用以下项目训练CycleGAN模型,github.com/vanhuyz/Cyc…,主要包括几个代码:
build_data.py:将图片数据整理为tfrecords文件ops.py:定义了一些小的网络模块generator.py:生成器的定义discriminator.py:判别器的定义model.py:使用生成器和判别器定义CycleGANtrain.py:训练模型的代码export_graph.py:将训练好的模型打包成.pd文件inference.py:使用打包好的.pb文件翻译图片,即使用模型进行推断
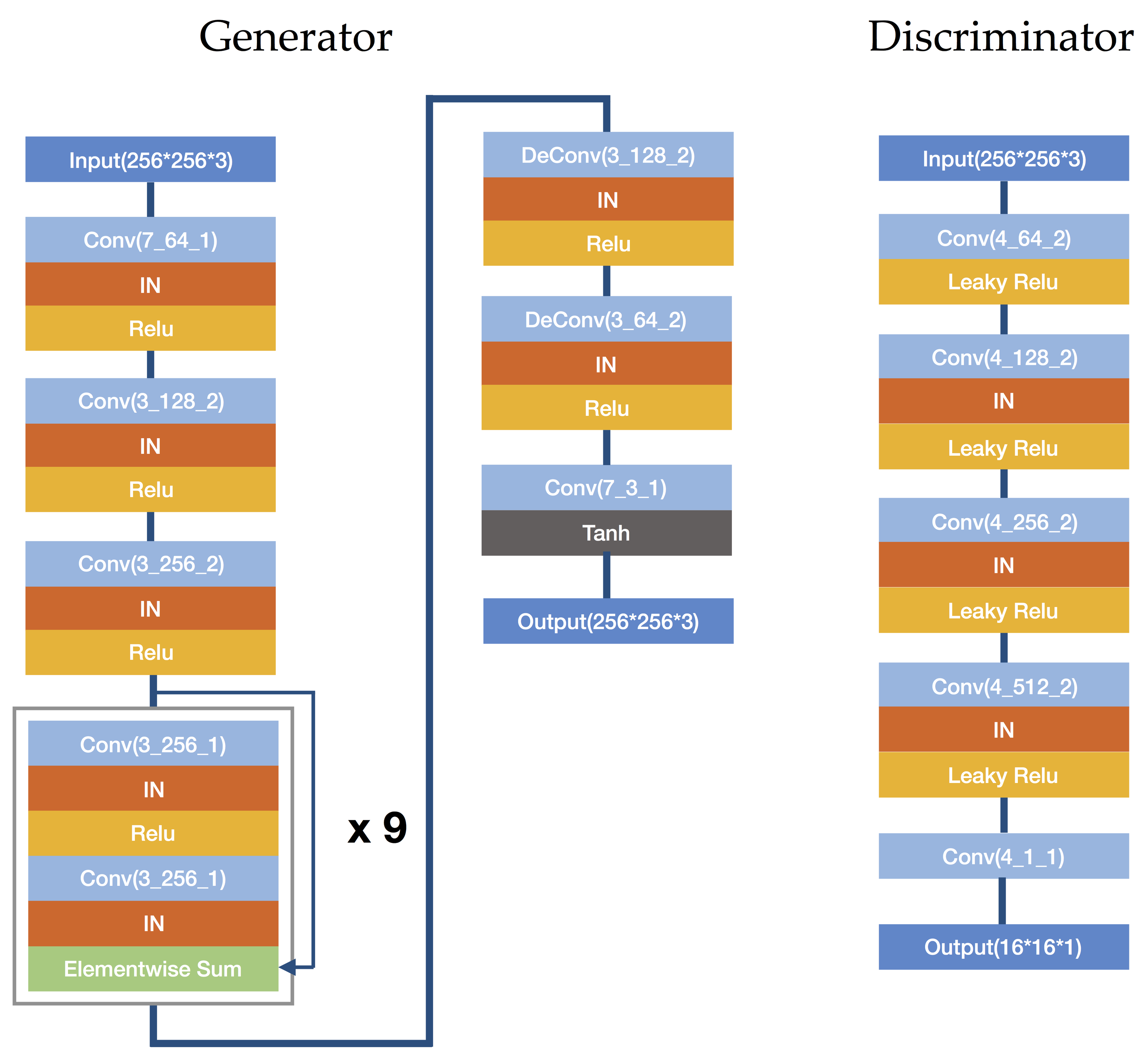
生成器和判别器结构如下,如果感兴趣可以进一步阅读项目源码
性别转换
使用CelebA中的男性图片和女性图片,训练一个实现性别转换的CycleGAN
将CelebA数据集中的图片处理成256*256大小,并按照性别保存至male和female两个文件夹,分别包含84434张男性图片和118165张女性图片
# -*- coding: utf-8 -*-
from imageio import imread, imsave
import cv2
import glob, os
from tqdm import tqdm
data_dir = 'data'
male_dir = 'data/male'
female_dir = 'data/female'
if not os.path.exists(data_dir):
os.mkdir(data_dir)
if not os.path.exists(male_dir):
os.mkdir(male_dir)
if not os.path.exists(female_dir):
os.mkdir(female_dir)
WIDTH = 256
HEIGHT = 256
def read_process_save(read_path, save_path):
image = imread(read_path)
h = image.shape[0]
w = image.shape[1]
if h > w:
image = image[h // 2 - w // 2: h // 2 + w // 2, :, :]
else:
image = image[:, w // 2 - h // 2: w // 2 + h // 2, :]
image = cv2.resize(image, (WIDTH, HEIGHT))
imsave(save_path, image)
target = 'Male'
with open('list_attr_celeba.txt', 'r') as fr:
lines = fr.readlines()
all_tags = lines[0].strip('\n').split()
for i in tqdm(range(1, len(lines))):
line = lines[i].strip('\n').split()
if int(line[all_tags.index(target) + 1]) == 1:
read_process_save(os.path.join('celeba', line[0]), os.path.join(male_dir, line[0])) # 男
else:
read_process_save(os.path.join('celeba', line[0]), os.path.join(female_dir, line[0])) # 女
使用build_data.py将图片转换成tfrecords格式
python CycleGAN-TensorFlow/build_data.py --X_input_dir data/male/ --Y_input_dir data/female/ --X_output_file data/male.tfrecords --Y_output_file data/female.tfrecords
使用train.py训练CycleGAN模型
python CycleGAN-TensorFlow/train.py --X data/male.tfrecords --Y data/female.tfrecords --image_size 256
训练开始后,会生成checkpoints文件夹,并根据当前日期和时间生成一个子文件夹,例如20180507-0231,其中包括用于显示tensorboard的events.out.tfevents文件,以及和模型相关的一些文件
使用tensorboard查看模型训练细节,运行以下命令后访问6006端口即可
tensorboard --logdir=checkpoints/20180507-0231
以下是迭代185870次之后,tensorboard的IMAGES页面
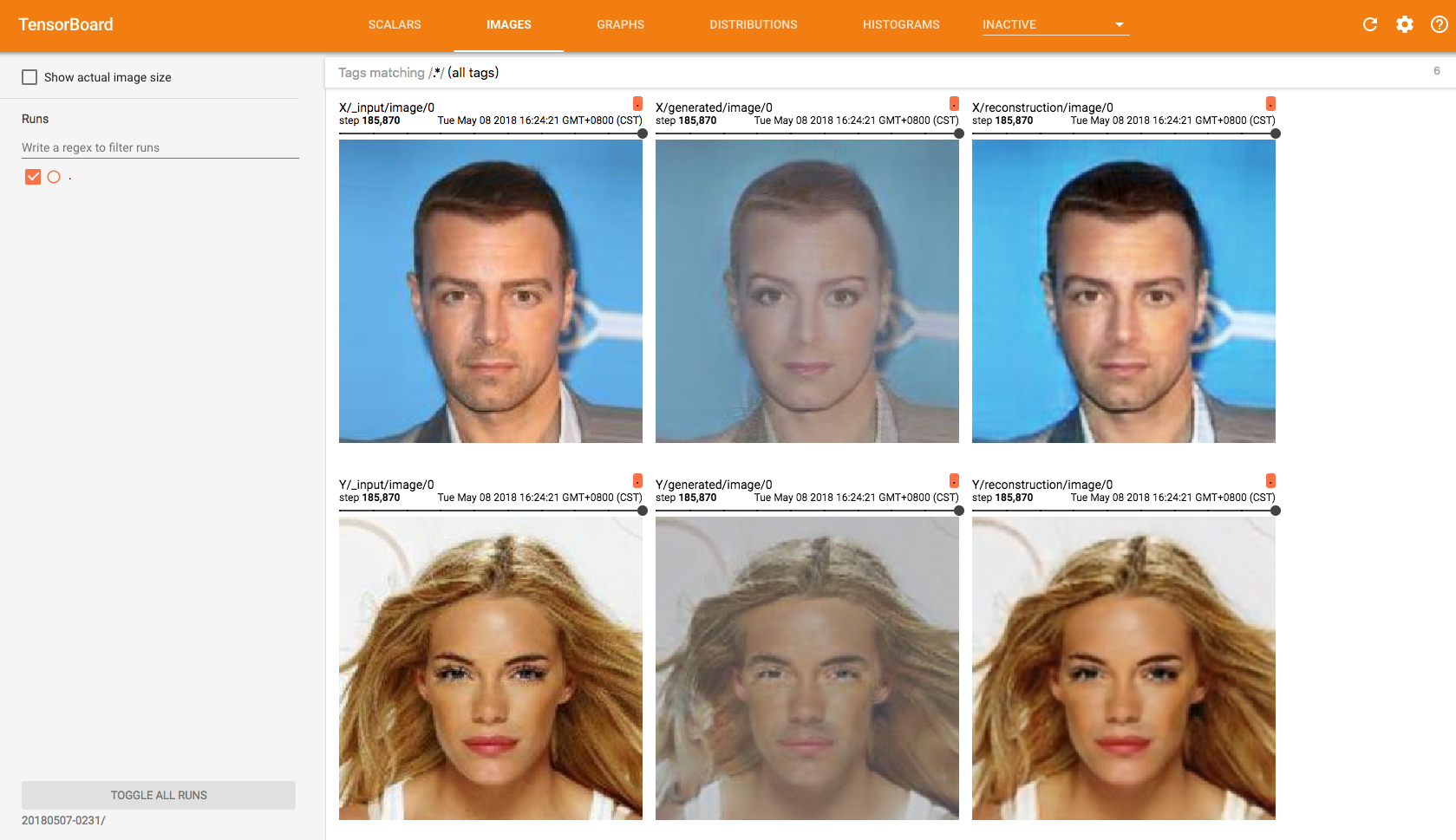
模型训练没有迭代次数限制,所以感觉效果不错或者迭代次数差不多了,便可以终止训练
使用export_graph.py将模型打包成.pb文件,生成的文件在pretrained文件夹中
python CycleGAN-TensorFlow/export_graph.py --checkpoint_dir checkpoints/20180507-0231/ --XtoY_model male2female.pb --YtoX_model female2male.pb --image_size 256
通过inference.py使用模型处理图片
python CycleGAN-TensorFlow/inference.py --model pretrained/male2female.pb --input Trump.jpg --output Trump_female.jpg --image_size 256
python CycleGAN-TensorFlow/inference.py --model pretrained/female2male.pb --input Hillary.jpg --output Hillary_male.jpg --image_size 256
在代码中使用模型处理多张图片
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
from model import CycleGAN
from imageio import imread, imsave
import glob
import os
image_file = 'face.jpg'
W = 256
result = np.zeros((4 * W, 5 * W, 3))
for gender in ['male', 'female']:
if gender == 'male':
images = glob.glob('../faces/male/*.jpg')
model = '../pretrained/male2female.pb'
r = 0
else:
images = glob.glob('../faces/female/*.jpg')
model = '../pretrained/female2male.pb'
r = 2
graph = tf.Graph()
with graph.as_default():
graph_def = tf.GraphDef()
with tf.gfile.FastGFile(model, 'rb') as model_file:
graph_def.ParseFromString(model_file.read())
tf.import_graph_def(graph_def, name='')
with tf.Session(graph=graph) as sess:
input_tensor = graph.get_tensor_by_name('input_image:0')
output_tensor = graph.get_tensor_by_name('output_image:0')
for i, image in enumerate(images):
image = imread(image)
output = sess.run(output_tensor, feed_dict={input_tensor: image})
with open(image_file, 'wb') as f:
f.write(output)
output = imread(image_file)
maxv = np.max(output)
minv = np.min(output)
output = ((output - minv) / (maxv - minv) * 255).astype(np.uint8)
result[r * W: (r + 1) * W, i * W: (i + 1) * W, :] = image
result[(r + 1) * W: (r + 2) * W, i * W: (i + 1) * W, :] = output
os.remove(image_file)
imsave('CycleGAN性别转换结果.jpg', result)

视频性别转换
对一段视频,识别每一帧可能包含的人脸,检测人脸对应的性别,并使用CycleGAN完成性别的双向转换
使用以下项目实现性别的检测,github.com/yu4u/age-ge…,通过Keras训练模型,可以检测出人脸的性别和年龄
举个例子,使用OpenCV获取摄像头图片,通过dlib检测人脸,并得到每一个检测结果对应的年龄和性别
# -*- coding: utf-8 -*-
from wide_resnet import WideResNet
import numpy as np
import cv2
import dlib
depth = 16
width = 8
img_size = 64
model = WideResNet(img_size, depth=depth, k=width)()
model.load_weights('weights.hdf5')
def draw_label(image, point, label, font=cv2.FONT_HERSHEY_SIMPLEX, font_scale=1, thickness=2):
size = cv2.getTextSize(label, font, font_scale, thickness)[0]
x, y = point
cv2.rectangle(image, (x, y - size[1]), (x + size[0], y), (255, 0, 0), cv2.FILLED)
cv2.putText(image, label, point, font, font_scale, (255, 255, 255), thickness)
detector = dlib.get_frontal_face_detector()
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
while True:
ret, image_np = cap.read()
image_np = cv2.cvtColor(image_np, cv2.COLOR_BGR2RGB)
img_h = image_np.shape[0]
img_w = image_np.shape[1]
detected = detector(image_np, 1)
faces = []
if len(detected) > 0:
for i, d in enumerate(detected):
x0, y0, x1, y1, w, h = d.left(), d.top(), d.right(), d.bottom(), d.width(), d.height()
cv2.rectangle(image_np, (x0, y0), (x1, y1), (255, 0, 0), 2)
x0 = max(int(x0 - 0.25 * w), 0)
y0 = max(int(y0 - 0.45 * h), 0)
x1 = min(int(x1 + 0.25 * w), img_w - 1)
y1 = min(int(y1 + 0.05 * h), img_h - 1)
w = x1 - x0
h = y1 - y0
if w > h:
x0 = x0 + w // 2 - h // 2
w = h
x1 = x0 + w
else:
y0 = y0 + h // 2 - w // 2
h = w
y1 = y0 + h
faces.append(cv2.resize(image_np[y0: y1, x0: x1, :], (img_size, img_size)))
faces = np.array(faces)
results = model.predict(faces)
predicted_genders = results[0]
ages = np.arange(0, 101).reshape(101, 1)
predicted_ages = results[1].dot(ages).flatten()
for i, d in enumerate(detected):
label = '{}, {}'.format(int(predicted_ages[i]), 'F' if predicted_genders[i][0] > 0.5 else 'M')
draw_label(image_np, (d.left(), d.top()), label)
cv2.imshow('gender and age', cv2.cvtColor(image_np, cv2.COLOR_RGB2BGR))
if cv2.waitKey(25) & 0xFF == ord('q'):
cap.release()
cv2.destroyAllWindows()
break
将以上项目和CycleGAN应用于视频的双向性别转换,首先提取出视频中的人脸,记录人脸出现的帧数、位置以及对应的性别,视频共830帧,检测出721张人脸
# -*- coding: utf-8 -*-
from wide_resnet import WideResNet
import numpy as np
import cv2
import dlib
import pickle
depth = 16
width = 8
img_size = 64
model = WideResNet(img_size, depth=depth, k=width)()
model.load_weights('weights.hdf5')
detector = dlib.get_frontal_face_detector()
cap = cv2.VideoCapture('../friends.mp4')
pos = []
frame_id = -1
while cap.isOpened():
ret, image_np = cap.read()
frame_id += 1
if len((np.array(image_np)).shape) == 0:
break
image_np = cv2.cvtColor(image_np, cv2.COLOR_BGR2RGB)
img_h = image_np.shape[0]
img_w = image_np.shape[1]
detected = detector(image_np, 1)
if len(detected) > 0:
for d in detected:
x0, y0, x1, y1, w, h = d.left(), d.top(), d.right(), d.bottom(), d.width(), d.height()
x0 = max(int(x0 - 0.25 * w), 0)
y0 = max(int(y0 - 0.45 * h), 0)
x1 = min(int(x1 + 0.25 * w), img_w - 1)
y1 = min(int(y1 + 0.05 * h), img_h - 1)
w = x1 - x0
h = y1 - y0
if w > h:
x0 = x0 + w // 2 - h // 2
w = h
x1 = x0 + w
else:
y0 = y0 + h // 2 - w // 2
h = w
y1 = y0 + h
face = cv2.resize(image_np[y0: y1, x0: x1, :], (img_size, img_size))
result = model.predict(np.array([face]))
pred_gender = result[0][0][0]
if pred_gender > 0.5:
pos.append([frame_id, y0, y1, x0, x1, h, w, 'F'])
else:
pos.append([frame_id, y0, y1, x0, x1, h, w, 'M'])
print(frame_id + 1, len(pos))
with open('../pos.pkl', 'wb') as fw:
pickle.dump(pos, fw)
cap.release()
cv2.destroyAllWindows()
再使用CycleGAN,将原视频中出现的人脸转换成相反的性别,并写入新的视频文件
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
from model import CycleGAN
from imageio import imread
import os
import cv2
import pickle
from tqdm import tqdm
with open('../pos.pkl', 'rb') as fr:
pos = pickle.load(fr)
cap = cv2.VideoCapture('../friends.mp4')
ret, image_np = cap.read()
out = cv2.VideoWriter('../output.mp4', -1, cap.get(cv2.CAP_PROP_FPS), (image_np.shape[1], image_np.shape[0]))
frames = []
while cap.isOpened():
ret, image_np = cap.read()
if len((np.array(image_np)).shape) == 0:
break
frames.append(cv2.cvtColor(image_np, cv2.COLOR_BGR2RGB))
image_size = 256
image_file = 'face.jpg'
for gender in ['M', 'F']:
if gender == 'M':
model = '../pretrained/male2female.pb'
else:
model = '../pretrained/female2male.pb'
graph = tf.Graph()
with graph.as_default():
graph_def = tf.GraphDef()
with tf.gfile.FastGFile(model, 'rb') as model_file:
graph_def.ParseFromString(model_file.read())
tf.import_graph_def(graph_def, name='')
with tf.Session(graph=graph) as sess:
input_tensor = graph.get_tensor_by_name('input_image:0')
output_tensor = graph.get_tensor_by_name('output_image:0')
for i in tqdm(range(len(pos))):
fid, y0, y1, x0, x1, h, w, g = pos[i]
if g == gender:
face = cv2.resize(frames[fid - 1][y0: y1, x0: x1, :], (image_size, image_size))
output_face = sess.run(output_tensor, feed_dict={input_tensor: face})
with open(image_file, 'wb') as f:
f.write(output_face)
output_face = imread(image_file)
maxv = np.max(output_face)
minv = np.min(output_face)
output_face = ((output_face - minv) / (maxv - minv) * 255).astype(np.uint8)
output_face = cv2.resize(output_face, (w, h))
frames[fid - 1][y0: y1, x0: x1, :] = output_face
for frame in frames:
out.write(cv2.cvtColor(frame, cv2.COLOR_RGB2BGR))
os.remove(image_file)
cap.release()
out.release()
cv2.destroyAllWindows()
生成的视频文件只有图像、没有声音,可以使用ffmpeg进一步处理
如果没有ffmpeg则下载并安装,www.ffmpeg.org/download.ht…
进入命令行,从原始视频中提取音频
ffmpeg -i friends.mp4 -f mp3 -vn sound.mp3
将提取的音频和生成的视频合成在一起
ffmpeg -i output.mp4 -i sound.mp3 combine.mp4
其他
项目还提供了四个训练好的模型,github.com/vanhuyz/Cyc…,包括苹果到橘子、橘子到苹果、马到斑马、斑马到马,如果感兴趣可以尝试一下
用CycleGAN不仅可以完成两类图片之间的转换,也可以实现两个物体之间的转换,例如将一个人翻译成另一个人
可以考虑从一部电影中提取出两个角色对应的图片,训练CycleGAN之后,即可将一个人翻译成另一个人
还有一些比较大胆的尝试,提高驾驶技术:用GAN去除(爱情)动作片中的马赛克和衣服
参考
- CycleGAN:junyanz.github.io/CycleGAN/
- CycleGAN-TensorFlow:github.com/vanhuyz/Cyc…
- Keras implementation of a CNN network for age and gender estimation:github.com/yu4u/age-ge…
