

内存问题
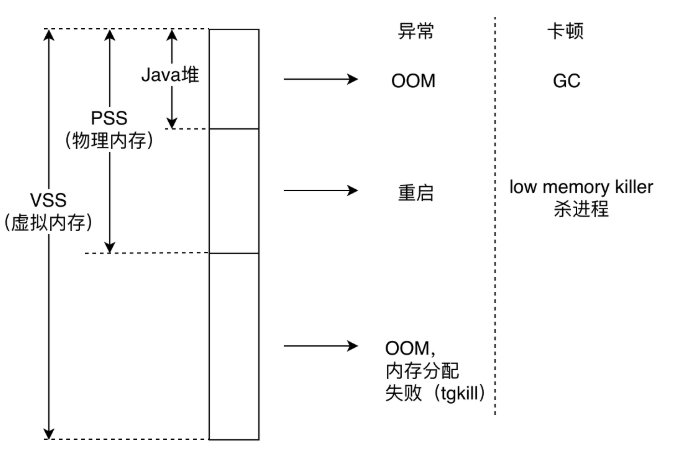
内存直接会影响两个问题:
- 异常。OOM、内存分配失败、应用被杀、设备重启等。
- 卡顿。频繁 GC,在 Dalvik 上尤为明显,虽然 ART 做了优化,但是依然会造成设备卡顿。另外,频繁的出发 LMK 也会造成卡顿。
ART 比 Dalvik 在内存分配和 GC 效率上,提升了 5~10 倍。
扩展问题:OOM 可以被 try-catch 住吗?分情况,如果在 try 语句中存在申请内存的操作,此时触发的 OOM 是可以被 catch 住的。但是并没有用,因为 OOM 的触发通常是压死骆驼最后一根稻草,此处 catch 住了,在别的地方可能也会崩溃。一个有效的方案,是在 catch 块中,释放内存,来保证当前运行环境的健康。
GC 的性能,可以通过发送 SIGQUIT 信号获取 ANR 日志,但是在高版本中,获取 traces.txt 文件需要 Root 权限,这里不推荐。
另外一个分析 GC 的工具是使用 systrace。systrace 在 Google IO 2017 被推荐,是分析 Android 设备性能的主要工具。它实际上是对 atrace 的主机端封装容器,用于控制用户空间和设置 ftrace 的设备端可执行文件。推荐阅读《了解 Systrace》、《手把手教你使用Systrace》、《systrace》
内存问题的两个误区:
- 内存占用越少越好。
- Native 内存不用管。
误区一:内存占用越少越好。
VSS、PSS、Java 堆内存不足都可能会引起异常和卡顿。
但是到底占用多少内存,这是由实际情况,例如:设备、系统、当时运行环境等多个因素影响的。所以不存在一个标准的数值。能够做到的就是“用时分配,及时释放”。
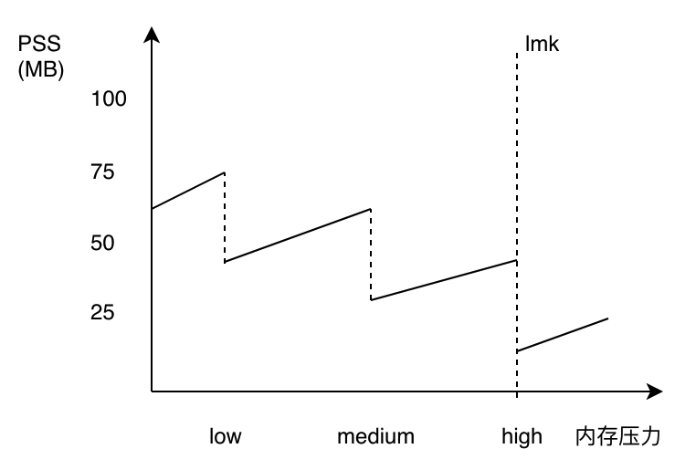
上图这样的就算是好的效果,在需要时,可以被释放,而不是一直涨。
"一张图,毁十优",在 Android 中,Bitmap 是内存占用的大户。
简单回顾 Bitmap 在不同 Android 版本中的区别:
Android 3.0 之前,Bitmap 对象放在 Java 堆,像素数据放在 Native 内存。如果不手动调用 recycle,Bitmap Native 内存的回收完全依赖 finalize 函数调用,这个时机是不可控的。
Android 3.0~7.0,Bitmap 对象和像素数据统一放在 Java 堆中。这样就算我们不调用 recycle,Bitmap 内存也会随着对象一起被回收。虽然这样方便回收,但是 Bitmap 放在 Java 堆中会引发大量的 GC。
Android 8.0,利用 NativeAllocationRegistry 来保证 Bitmap 的像素数据放在 Native 内存,但是依然可以和对象一起被快速释放。8.0 还新增了硬件位图 Hardware Bitmap,它可以减少图片内存并提升绘制效率。
误区二:Native 内存不用管
当内存不足的时候,LMK 就开始工作了,按照优先级,从后台、桌面、服务、前台、直到手机重启。
Fresco 会把 Bitmap 放在 Native 内存中,它的原理是利用 libandroid_runtime.so 在 Native 中创建一个 Bitmap 对象,再按正常流程将 Bitmap 加载到 Java 堆中,接下来再把它绘制入前面申请的空的 Native Bitmap 中,然后释放 Java 内存中的图片,实现转换的效果。
注意这样非常规的操作,会带来两个问题:
- 不同 Android 系统版本的兼容性问题。
- 频繁申请、释放 Java Bitmap 导致内存抖动。
测量方法
一、Java 内存分配
Java 内存分配分析工具,常用的有 Allocation Tracker 和 MAT。
Allocation Tracker 的三个缺点:
获取信息过于分散,数据中夹杂其他信息。 无法自动化分析。 停止时会把所有数据 dump 出来,此过程可能会造成手机完全卡死,甚至可能引发 ANR。 Allocation Tracker 的开启方式:
// dalvik
bool dvmEnableAllocTracker()
// art
void setAllocTrackingEnable()
二、Native 内存分配
Native 内存可以使用 AddressSanitizer(ASan),Android 之前的版本对 ASan 的支持不太好,需要 Root 和一些额外的操作,自 8.0 开始,就方便很多了,并且无需 Root。
ASan 是一种基于编译器的快速检测工具,用于检测原生代码中的内存错误。ASan 会检测堆栈和全局对象是否移除,但是不会检测未初始化的读取和内存泄露。ASan 在 Android 下的使用,参考指南。
调试 Native 内存,现在有两种方法:
Malloc 调试 Malloc 钩子 Malloc 调试可以去调试 Native 内存的一些使用问题,例如堆破坏、内存泄露、非法地址等。
但是 Mallock 调试时,App 会变卡,有产生 ANR 的风险。
Malloc 调试在 8.0 之前需要 Root 权限,最简单的方法是找一台 8.0 的设备进行调试。
adb shell setprop wrap.<APP> '"LIBC_DEBUG_MALLOC_OPTIONS=backtrace logwrapper"'
Malloc 钩子是在 Android P 之后才有的。Android 的 libc 支持拦截在程序执行期间发生的所有分配/释放调用,方便我们构建自定义的内存检测工具。
adb shell setprop wrap.<APP> '"LIBC_HOOKS_ENABLE=1"'
优化
内存优化,从三个维度入手:
- 设备分级
- Bitmap 优化
- 内存泄露
一、设备分级
内存优化首先需要根据设备环境来综合考虑。内存占用并非越少越好,而是应该在占用内存和设备内存之间取平衡。
资源加载在内存中,意味着下次使用的时候会更快。因此我们可以让高端设备使用更多的内存,做到针对设备性能的好坏使用不同的内存分配和回收策略。
1、设备分级
使用内存情况对设备分级,类似 device-year-class 的策略,对低端设备可以关闭复杂动画或某些功能;使用 565 格式的图片,使用更小的缓存内存等。
2、缓存管理
有一套统一的缓存管理机制,可以适当地使用内存,当内存不足时,可以有效的归还内存。可以使用 onTrimMemort 回调,根据不同状态决定释放多少内存。
3、进程模型
一个空的进程,也会占用 10MB 的内存,而有些应用启动就有十几个进程。可以通过减少应用启动的进程数、减少常驻进程。
4、安装包大小。
安装包中的代码、资源、图片以及 so 库的提及,和他们运行时占用的内存有关系。减少 APK 的大小,也可以优化低端机上的运行效果。例如各大 App 会推出 Xxx Lite 版本。
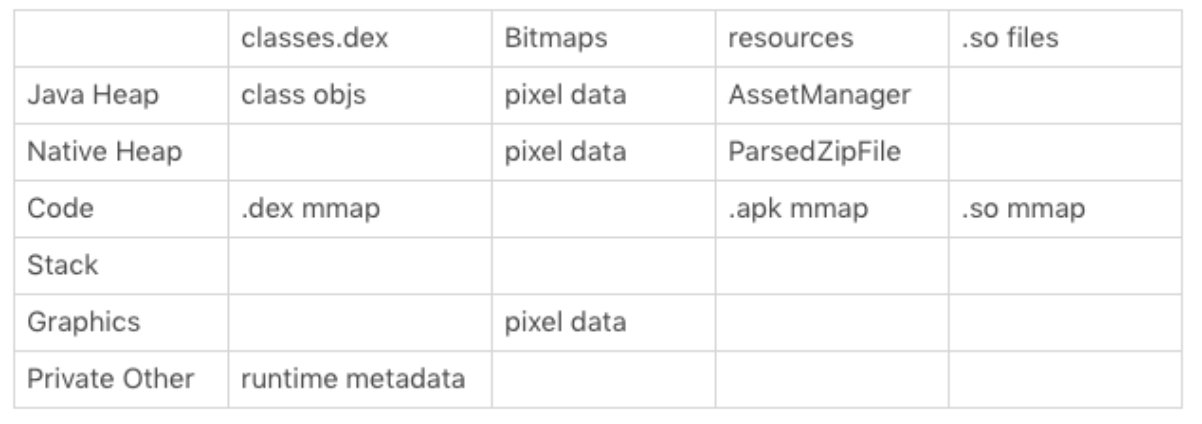
二、Bitmap优化
Bitmap 是内存优化的“永恒主题”。
方法一:统一图片库
图片内存优化的前提是收拢图片的调用,这样可以做整体的控制策略。
Glide、Fresco 或者是自研的图片库,无论用什么,要做到统一。否则各个库内部自己维护缓存,单看其实做的都很好,让内存保持在一个良好的环境下,但是加起来就可能导致内存爆表。
方法二:统一监控
要对一些特殊的场景,做好监控。
大图片监控。当知道显示图片控件的宽高时,是可以算出这个图片占用的合理内存的。如果大于此合理值,就应该通报出来,提醒开发者,例如弹窗。 重复图片监控。指的是 Bitmap 像素数据完全一致,但是有多个不同对象存在。 图片总内存。因为使用统一图片库,我们很容易统计应用所有图片占用的内存。在发生 OOM 时,也可以把图片占用的总内存,Top N 的图片写到 Log 中,帮助我们排查。
三、内存泄露
内存泄露简单来说,就是不再使用的内存,无法被回收。
内存泄露主要分两种情况:
- 同一对象泄露。
- 每次都泄露新的对象。
可以通过集中策略监控内存泄露:
- Java 内存泄露。使用类似 LeakCanary 自动化检测方案,至少做到在 Java 层不存在内存泄露。
- OOM 监控。OOM 时,记录信息或者内存快照,达到后期分析的目的。 Native 内存泄露监控。推荐《微信 Android 终端内存优化实践》
- 针对无法重编 so 的情况。使用 PLT Hook 拦截库的内存分配函数,就可以重定向到自己的实现后记录分配的内存地址、大小、来源 so 库等信息。
- 针对可重编的 so 情况。通过 GCC 的 "-finstrument-functions"参数给所有函数插装,庄中模拟调用栈,入栈出栈操作;通过 id 的 “--wrap”参数拦截内存分配和释放函数。

内存泄露监控,Android 下占时只有 Java 层的内存泄露有成熟的技术方案,剩下的都是实验室方案,可以在开发阶段使用,不建议在线上 App内集成发布。
内存监控
1、采集方式
针对部分用户,每 5 分钟采集一次 PSS、Java 堆、图片总内存。
PSS:实际使用物理内存。
2、计算指标
通过标准的计算指标,来分析内存是否良好。
所有的优化,都是针对某一个指标进行优化。内存优化也是如此。需要有一个标准的指标来辅助我们识别当前的情况,以及优化的效果。
内存异常率:
内存 UV 异常率 = PPS 超过 400MB 的 UV / 采集 UV
触顶率:
统计超过 85% 的内存占用情况。
内存 UV 触顶率 = Java 堆占用超过 85% 的 UV / 采集 UV
long javaMax = runtime.maxMemory();
long javaTotal = runtime.totalMemory();
long javaUsed = javaTotal - runtime.freeMemory();
// Java 内存使用超过最大限制的 85%
float proportion = (float) javaUsed / javaMax;
3、GC 监控
在开发阶段,可以通过 Debug.startAllocCounting 来监控 Java 内存分配和 GC 情况。
long allocCount = Debug.getGlobalAllocCount();
long allocSize = Debug.getGlobalAllocSize();
long gcCount = Debug.getGlobalGcInvocationCount();
Android 6.0 以上可以拿到更精准的数据。
// 运行的 GC 次数
Debug.getRuntimeStat("art.gc.gc-count");
// GC 使用的总耗时,单位是毫秒
Debug.getRuntimeStat("art.gc.gc-time");
// 阻塞式 GC 的次数
Debug.getRuntimeStat("art.gc.blocking-gc-count");
// 阻塞式 GC 的总耗时
Debug.getRuntimeStat("art.gc.blocking-gc-time");
阻塞式 GC 会暂停 App 线程,可能导致卡顿。
日志
Dalvik 日志消息
D/dalvikvm: <GC_Reason> <Amount_freed>, <Heap_stats>, <External_memory_stats>, <Pause_time>
D/dalvikvm( 9050): GC_CONCURRENT freed 2049K, 65% free 3571K/9991K, external 4703K/5261K, paused 2ms+2ms
垃圾回收原因
什么触发了垃圾回收以及是哪种回收。可能出现的原因包括:
- GC_CONCURRENT 在您的堆开始占用内存时可以释放内存的并发垃圾回收。
- GC_FOR_MALLOC 堆已满而系统不得不停止您的应用并回收内存时,您的应用尝试分配内存而引起的垃圾回收。
- GC_HPROF_DUMP_HEAP 当您请求创建 HPROF 文件来分析堆时出现的垃圾回收。
- GC_EXPLICIT 显式垃圾回收,例如当您调用 gc() 时(您应避免调用,而应信任垃圾回收会根据需要运行)。
- GC_EXTERNAL_ALLOC 这仅适用于 API 级别 10 及更低级别(更新版本会在 Dalvik 堆中分配任何内存)。外部分配内存的垃圾回收(例如存储在原生内存或 NIO 字节缓冲区中的像素数据)。
释放量
从此次垃圾回收中回收的内存量。
堆统计数据
堆的可用空间百分比与(活动对象数量)/(堆总大小)。
外部内存统计数据
API 级别 10 及更低级别的外部分配内存(已分配内存量)/(发生回收的限值)。
暂停时间
堆越大,暂停时间越长。并发暂停时间显示了两个暂停:一个出现在回收开始时,另一个出现在回收快要完成时。
在这些日志消息积聚时,请注意堆统计数据的增大(上面示例中的 3571K/9991K 值)。如果此值继续增大,可能会出现内存泄漏。
ART 日志消息
与 Dalvik 不同,ART 不会为未明确请求的垃圾回收记录消息。只有在认为垃圾回收速度较慢时才会打印垃圾回收。更确切地说,仅在垃圾回收暂停时间超过 5ms 或垃圾回收持续时间超过 100ms 时。如果应用未处于可察觉的暂停进程状态,那么其垃圾回收不会被视为较慢。始终会记录显式垃圾回收。
ART 会在其垃圾回收日志消息中包含以下信息:
I/art: <GC_Reason> <GC_Name> <Objects_freed>(<Size_freed>) AllocSpace Objects, <Large_objects_freed>(<Large_object_size_freed>) <Heap_stats> LOS objects, <Pause_time(s)>
I/art : Explicit concurrent mark sweep GC freed 104710(7MB) AllocSpace objects, 21(416KB) LOS objects, 33% free, 25MB/38MB, paused 1.230ms total 67.216ms
垃圾回收原因
什么触发了垃圾回收以及是哪种回收。可能出现的原因包括:
- Concurrent 不会暂停应用线程的并发垃圾回收。此垃圾回收在后台线程中运行,而且不会阻止分配。
- Alloc 您的应用在堆已满时尝试分配内存引起的垃圾回收。在这种情况下,分配线程中发生了垃圾回收。
- Explicit 由应用明确请求的垃圾回收,例如,通过调用 gc() 或 gc()。与 Dalvik 相同,在 ART 中,最佳做法是您应信任垃圾回收并避免请求显式垃圾回收(如果可能)。不建议使用显式垃圾回收,因为它们会阻止分配线程并不必要地浪费 CPU 周期。如果显式垃圾回收导致其他线程被抢占,那么它们也可能会导致卡顿(应用中出现间断、抖动或暂停)。
- NativeAlloc 原生分配(如位图或 RenderScript 分配对象)导致出现原生内存压力,进而引起的回收。
- CollectorTransition 由堆转换引起的回收;此回收由运行时切换垃圾回收引起。回收器转换包括将所有对象从空闲列表空间复制到碰撞指针空间(反之亦然)。当前,回收器转换仅在以下情况下出现:在 RAM 较小的设备上,应用将进程状态从可察觉的暂停状态变更为可察觉的非暂停状态(反之亦然)。
- HomogeneousSpaceCompact 齐性空间压缩是空闲列表空间到空闲列表空间压缩,通常在应用进入到可察觉的暂停进程状态时发生。这样做的主要原因是减少 RAM 使用量并对堆进行碎片整理。
- DisableMovingGc 这不是真正的垃圾回收原因,但请注意,发生并发堆压缩时,由于使用了 GetPrimitiveArrayCritical,回收遭到阻止。一般情况下,强烈建议不要使用 GetPrimitiveArrayCritical,因为它在移动回收器方面具有限制。
- HeapTrim 这不是垃圾回收原因,但请注意,堆修剪完成之前回收会一直受到阻止。
垃圾回收名称
ART 具有可以运行的多种不同的垃圾回收。
Concurrent mark sweep (CMS)
整个堆回收器,会释放和回收映像空间以外的所有其他空间。
Concurrent partial mark sweep
几乎整个堆回收器,会回收除了映像空间和 zygote 空间以外的所有其他空间。
Concurrent sticky mark sweep
生成回收器,只能释放自上次垃圾回收以来分配的对象。此垃圾回收比完整或部分标记清除运行得更频繁,因为它更快速且暂停时间更短。
Marksweep + semispace
非并发、复制垃圾回收,用于堆转换以及齐性空间压缩(对堆进行碎片整理)。
释放的对象
此次垃圾回收从非大型对象空间回收的对象数量。
释放的大小
此次垃圾回收从非大型对象空间回收的字节数量。
释放的大型对象
此次垃圾回收从大型对象空间回收的对象数量。
释放的大型对象大小
此次垃圾回收从大型对象空间回收的字节数量。
堆统计数据
空闲百分比与(活动对象数量)/(堆总大小)。
暂停时间
通常情况下,暂停时间与垃圾回收运行时修改的对象引用数量成正比。当前,ART CMS 垃圾回收仅在垃圾回收即将完成时暂停一次。移动的垃圾回收暂停时间较长,会在大部分垃圾回收期间持续出现。
如果您在 logcat 中看到大量的垃圾回收,请注意堆统计数据的增大(上面示例中的 25MB/38MB 值)。如果此值继续增大,且始终没有变小的趋势,则可能会出现内存泄漏。或者,如果您看到原因为“Alloc”的垃圾回收,那么您的操作已经快要达到堆容量,并且将很快出现 OOM 异常。
整体内存分配

使用下面的 adb 命令观察应用内存在不同类型的 RAM 分配之间的划分情况:
adb shell dumpsys meminfo <package_name|pid> [-d]
-d 标志会打印与 Dalvik 和 ART 内存使用情况相关的更多信息。
输出列出了应用的所有当前分配,单位为千字节。
检查此信息时,您应熟悉下列类型的分配:
私有(干净和脏)RAM
这是仅由您的进程使用的内存。这是您的应用进程被破坏时系统可以回收的 RAM 量。通常情况下,最重要的部分是私有脏 RAM,它的开销最大,因为只有您的进程使用它,而且其内容仅存在于 RAM 中,所以无法被分页以进行存储(因为 Android 不使用交换)。所有的 Dalvik 和您进行的原生堆分配都将是私有脏 RAM;您与 Zygote 进程共享的 Dalvik 和原生分配是共享的脏 RAM。
按比例分配占用内存 (PSS)
这表示您的应用的 RAM 使用情况,考虑了在各进程之间共享 RAM 页的情况。您的进程独有的任何 RAM 页会直接影响其 PSS 值,而与其他进程共享的 RAM 页仅影响与共享量成比例的 PSS 值。例如,两个进程之间共享的 RAM 页会将其一半的大小贡献给每个进程的 PSS。
PSS 结果一个比较好的特性是,您可以将所有进程的 PSS 相加来确定所有进程正在使用的实际内存。这意味着 PSS 适合测定进程的实际 RAM 比重和比较其他进程的 RAM 使用情况与可用总 RAM。
例如,下面是 Nexus 5 设备上地图进程的输出。此处信息较多,但讨论的关键点如下所示。
adb shell dumpsys meminfo com.google.android.apps.maps -d
** MEMINFO in pid 18227 [com.google.android.apps.maps] **
Pss Private Private Swapped Heap Heap Heap
Total Dirty Clean Dirty Size Alloc Free
------ ------ ------ ------ ------ ------ ------
Native Heap 10468 10408 0 0 20480 14462 6017
Dalvik Heap 34340 33816 0 0 62436 53883 8553
Dalvik Other 972 972 0 0
Stack 1144 1144 0 0
Gfx dev 35300 35300 0 0
Other dev 5 0 4 0
.so mmap 1943 504 188 0
.apk mmap 598 0 136 0
.ttf mmap 134 0 68 0
.dex mmap 3908 0 3904 0
.oat mmap 1344 0 56 0
.art mmap 2037 1784 28 0
Other mmap 30 4 0 0
EGL mtrack 73072 73072 0 0
GL mtrack 51044 51044 0 0
Unknown 185 184 0 0
TOTAL 216524 208232 4384 0 82916 68345 14570
Dalvik Details
.Heap 6568 6568 0 0
.LOS 24771 24404 0 0
.GC 500 500 0 0
.JITCache 428 428 0 0
.Zygote 1093 936 0 0
.NonMoving 1908 1908 0 0
.IndirectRef 44 44 0 0
Objects
Views: 90 ViewRootImpl: 1
AppContexts: 4 Activities: 1
Assets: 2 AssetManagers: 2
Local Binders: 21 Proxy Binders: 28
Parcel memory: 18 Parcel count: 74
Death Recipients: 2 OpenSSL Sockets: 2
下面是 Gmail 应用的 Dalvik 上一个较旧版本的 dumpsys:
** MEMINFO in pid 9953 [com.google.android.gm] **
Pss Pss Shared Private Shared Private Heap Heap Heap
Total Clean Dirty Dirty Clean Clean Size Alloc Free
------ ------ ------ ------ ------ ------ ------ ------ ------
Native Heap 0 0 0 0 0 0 7800 7637(6) 126
Dalvik Heap 5110(3) 0 4136 4988(3) 0 0 9168 8958(6) 210
Dalvik Other 2850 0 2684 2772 0 0
Stack 36 0 8 36 0 0
Cursor 136 0 0 136 0 0
Ashmem 12 0 28 0 0 0
Other dev 380 0 24 376 0 4
.so mmap 5443(5) 1996 2584 2664(5) 5788 1996(5)
.apk mmap 235 32 0 0 1252 32
.ttf mmap 36 12 0 0 88 12
.dex mmap 3019(5) 2148 0 0 8936 2148(5)
Other mmap 107 0 8 8 324 68
Unknown 6994(4) 0 252 6992(4) 0 0
TOTAL 24358(1) 4188 9724 17972(2)16388 4260(2)16968 16595 336
Objects
Views: 426 ViewRootImpl: 3(8)
AppContexts: 6(7) Activities: 2(7)
Assets: 2 AssetManagers: 2
Local Binders: 64 Proxy Binders: 34
Death Recipients: 0
OpenSSL Sockets: 1
SQL
MEMORY_USED: 1739
PAGECACHE_OVERFLOW: 1164 MALLOC_SIZE: 62
通常情况下,仅需关注 Pss Total 和 Private Dirty 列。一些情况下,Private Clean 和 Heap Alloc 列提供的数据也需要关注。您需要关注的不同内存分配(各行)的详细信息如下:
Dalvik Heap
您的应用中 Dalvik 分配占用的 RAM。Pss Total 包括所有 Zygote 分配(如上述 PSS 定义所述,通过进程之间的共享内存量来衡量)。Private Dirty 数值是仅分配到您应用的堆的实际 RAM,由您自己的分配和任何 Zygote 分配页组成,这些分配页自从 Zygote 派生应用进程以来已被修改。 注:在包含 Dalvik Other 部分的更新的平台版本上,Dalvik 堆的 Pss Total 和 Private Dirty 数值不包括 Dalvik 开销(例如即时 (JIT) 编译和垃圾回收记录),而较旧的版本会在 Dalvik 中将其一并列出。
Heap Alloc 是 Dalvik 和原生堆分配器为您的应用跟踪的内存量。此值大于 Pss Total 和 Private Dirty,因为您的进程从 Zygote 派生,且包含您的进程与所有其他进程共享的分配。
.so mmap 和 .dex mmap
映射的 .so(原生)和 .dex(Dalvik 或 ART)代码占用的 RAM。Pss Total 数值包括应用之间共享的平台代码;Private Clean 是您的应用自己的代码。通常情况下,实际映射的内存更大 - 此处的 RAM 仅为应用执行的代码当前所需的 RAM。不过,.so mmap 具有较大的私有脏 RAM,因为在加载到其最终地址时对原生代码进行了修改。
.oat mmap
这是代码映像占用的 RAM 量,根据多个应用通常使用的预加载类计算。此映像在所有应用之间共享,不受特定应用影响。
.art mmap
这是堆映像占用的 RAM 量,根据多个应用通常使用的预加载类计算。此映像在所有应用之间共享,不受特定应用影响。尽管 ART 映像包含 Object 实例,它仍然不会计入您的堆大小。
.Heap(仅带有 -d 标志)
这是您的应用的堆内存量。不包括映像中的对象和大型对象空间,但包括 zygote 空间和非移动空间。
.LOS(仅带有 -d 标志)
这是由 ART 大型对象空间占用的 RAM 量。包括 zygote 大型对象。大型对象是所有大于 12KB 的原语数组分配。
.GC(仅带有 -d 标志)
这是内部垃圾回收量(考虑了应用开销)。真的没有任何办法减少这一开销。
.JITCache(仅带有 -d 标志)
这是 JIT 数据和代码缓存占用的内存量。通常情况下为 0,因为所有的应用都会在安装时编译。
.Zygote(仅带有 -d 标志)
这是 zygote 空间占用的内存量。zygote 空间在设备启动时创建且永远不会被分配。
.NonMoving(仅带有 -d 标志)
这是由 ART 非移动空间占用的 RAM 量。非移动空间包含特殊的不可移动对象,例如字段和方法。您可以通过在应用中使用更少的字段和方法来减少这一部分。
.IndirectRef(仅带有 -d 标志)
这是由 ART 间接引用表占用的 RAM 量。通常情况下,此量较小,但如果很高,可以通过减少使用的本地和全局 JNI 引用数量来减少此 RAM 量。
Unknown
系统无法将其分类到其他更具体的一个项中的任何 RAM 页。当前,此类 RAM 页主要包含原生分配,由于地址空间布局随机化 (ASLR) 而无法在收集此数据时通过工具识别。与 Dalvik 堆相同,Unknown 的 Pss Total 考虑了与 Zygote 的共享,且 Private Dirty 是仅由您的应用占有的未知 RAM。
TOTAL
您的进程占用的按比例分配占用内存 (PSS) 总量。等于上方所有 PSS 字段的总和。表示您的进程占用的内存量占整体内存的比重,可以直接与其他进程和可用总 RAM 比较。 Private Dirty 和 Private Clean 是您的进程中的总分配,未与其他进程共享。它们(尤其是 Private Dirty)等于您的进程被破坏后将释放回系统中的 RAM 量。脏 RAM 是因为已被修改而必须保持在 RAM 中的 RAM 页(因为没有交换);干净 RAM 是已从某个持久性文件(例如正在执行的代码)映射的 RAM 页,如果一段时间不用,可以移出分页。
ViewRootImpl
您的进程中当前活动的根视图数量。每个根视图都与一个窗口关联,因此有助于您确定涉及对话框或其他窗口的内存泄漏。
AppContexts 和 Activities
您的进程中当前活动的应用 Context 和 Activity 对象数量。这可以帮助您快速确定由于存在静态引用(比较常见)而无法进行垃圾回收的已泄漏 Activity 对象。这些对象经常拥有很多关联的其他分配,因此成为跟踪大型内存泄漏的一种不错的方式。
注:View 或 Drawable 对象也会保持对其源 Activity 的引用,因此保持 View 或 Drawable 对象也会导致您的应用泄漏 Activity。
Memory Profiler
Memory Profiler 是 Android Profiler 中的一个组件,可帮助您识别导致应用卡顿、冻结甚至崩溃的内存泄漏和流失[memory leaks and memory churn]。它显示一个应用内存使用量的实时图表[It shows a realtime graph of your app's memory use],让您可以捕获堆转储[capture a heap dump]、强制执行垃圾回收[force garbage collections]以及跟踪内存分配[track memory allocations]。
要打开 Memory Profiler,请按以下步骤操作:
点击 View > Tool Windows > Android Profiler(也可以点击工具栏中的 Android Profiler )。 从 Android Profiler 工具栏中选择您想要分析的设备和应用进程。 点击 MEMORY 时间线中的任意位置可打开 Memory Profiler。
Android 提供一个 托管内存环境(managed memory environment) —当它确定您的应用不再使用某些对象时,垃圾回收器会将未使用的内存释放回堆中。 虽然 Android 查找未使用内存的方式在不断改进,但对于所有 Android 版本,系统都必须在某个时间点短暂地暂停您的代码。 大多数情况下,这些暂停难以察觉。 不过,如果您的应用分配内存的速度比系统回收内存的速度快,则当收集器释放足够的内存以满足您的分配需要时,您的应用可能会延迟。 此延迟可能会导致您的应用跳帧[skip frames],并使系统明显变慢。
尽管您的应用不会表现出变慢,但如果存在内存泄漏,则即使应用在后台运行也会保留该内存。 此行为会强制执行不必要的垃圾回收 Event,因而拖慢系统的内存性能。 最后,系统被迫终止您的应用进程以回收内存。 然后,当用户返回您的应用时,它必须完全重启。
为帮助防止这些问题,您应使用 Memory Profiler 执行以下操作:
在时间线[timeline]中查找可能会导致性能问题的不理想的内存分配模式[undesirable memory allocation patterns]。 转储 Java 堆以查看在任何给定时间哪些对象耗尽了使用内存。 长时间进行多个堆转储可帮助识别内存泄漏。 记录正常用户交互和极端用户交互期间的内存分配以准确识别您的代码在何处短时间分配了过多对象,或分配了泄漏的对象[allocating objects that become leaked]。
Memory Profiler 概览
当您首次打开 Memory Profiler 时,您将看到一条表示应用内存使用量的详细时间线,并可访问用于强制执行垃圾回收、捕捉堆转储和记录内存分配的各种工具。
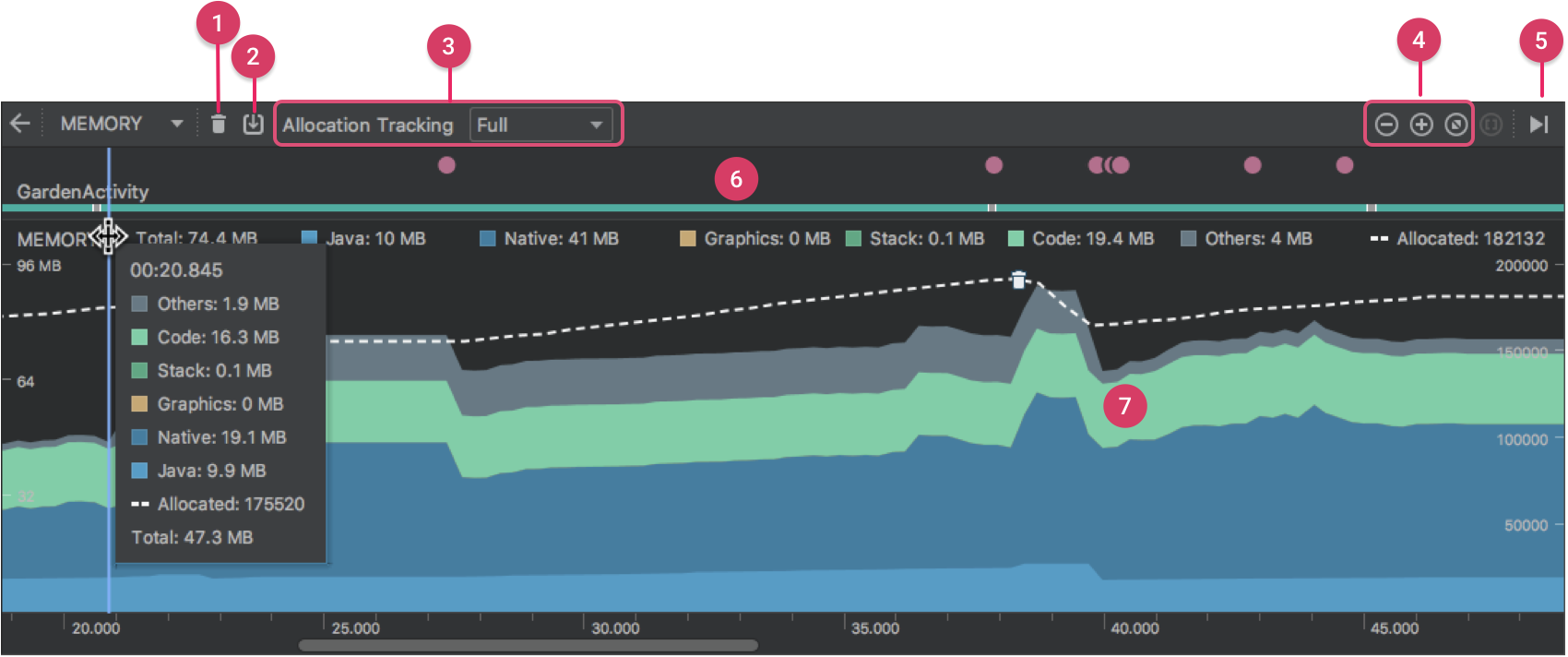
如图 1 所示,Memory Profiler 的默认视图包括以下各项:
- 用于强制执行垃圾回收 Event 的按钮。
- 用于捕获堆转储的按钮。
- 用于记录内存分配情况的按钮。 此按钮仅在连接至运行 Android 7.1 或更低版本的设备时才会显示。
- 用于放大/缩小时间线的按钮。
- 用于跳转至实时内存数据的按钮。
- Event 时间线,其显示 Activity 状态、用户输入 Event 和屏幕旋转 Event。
- 内存使用量时间线,其包含以下内容:
- 一个显示每个内存类别使用多少内存的堆叠图表[stacked graph],如左侧的 y 轴以及顶部的彩色键所示。
- 虚线表示分配的对象数,如右侧的 y 轴所示。
- 用于表示每个垃圾回收 Event 的图标。
不过,如果您使用的是运行 Android 7.1 或更低版本的设备,则默认情况下,并不是所有分析数据均可见。 如果您看到一条消息,其显示“Advanced profiling is unavailable for the selected process”,则需要 启用高级分析 以查看下列内容:
- Event 时间线
- 分配的对象数
- 垃圾回收 Event
在 Android 8.0 及更高版本上,始终为可调试应用启用高级分析。
如何计算内存
您在 Memory Profiler(图 2)顶部看到的数字取决于您的应用根据 Android 系统机制所提交的所有私有内存页面数[private memory pages]。 此计数不包含与系统或其他应用共享的页面。

内存计数中的类别如下所示:
- Java:从 Java 或 Kotlin 代码分配的对象内存。
- Native:从 C 或 C++ 代码分配的对象内存。 即使您的应用中不使用 C++,您也可能会看到此处使用的一些原生内存,因为 Android 框架使用原生内存代表您处理各种任务[handle various tasks on your behalf],如处理图像资源和其他图形时,即使您编写的代码采用 Java 或 Kotlin 语言。
- Graphics:图形缓冲区队列向屏幕显示像素(包括 GL 表面、GL 纹理等等)所使用的内存。 (请注意,这是与 CPU 共享的内存,不是 GPU 专用内存。)
- Stack: 您的应用中的原生堆栈和 Java 堆栈使用的内存。 这通常与您的应用运行多少线程有关。
- Code:您的应用用于处理代码和资源(如 dex 字节码、已优化或已编译的 dex 码、.so 库和字体)的内存。
- Other:您的应用使用的系统不确定如何分类的内存。
- Allocated:您的应用分配的 Java/Kotlin 对象数。 它没有计入 C 或 C++ 中分配的对象。 (当连接至运行 Android 7.1 及更低版本的设备时,此分配仅在 Memory Profiler 连接至您运行的应用时才开始计数。 因此,您开始分析之前分配的任何对象都不会被计入。 不过,Android 8.0 附带一个设备内置分析工具,该工具可记录所有分配,因此,在 Android 8.0 及更高版本上,此数字始终表示您的应用中待处理的 Java 对象总数。)
与以前的 Android Monitor 工具中的内存计数相比,新的 Memory Profiler 以不同的方式记录您的内存,因此,您的内存使用量现在看上去可能会更高些。 Memory Profiler 监控的类别更多,这会增加总的内存使用量,但如果您仅关心 Java 堆内存,则“Java”项的数字应与以前工具中的数值相似。
然而,Java 数字可能与您在 Android Monitor 中看到的数字并非完全相同,这是因为应用的 Java 堆是从 Zygote 启动的,而新数字则计入了为它分配的所有物理内存页面。 因此,它可以准确反映您的应用实际使用了多少物理内存。
注:目前,Memory Profiler 还会显示应用中的一些误报的原生内存使用量,而这些内存实际上是分析工具使用的。 对于大约 100000 个对象,最多会使报告的内存使用量增加 10MB。 在这些工具的未来版本中,这些数字将从您的数据中过滤掉。
查看内存分配
内存分配显示内存中每个对象是_如何_分配的。 具体而言,Memory Profiler 可为您显示有关对象分配的以下信息:
- 分配哪些类型的对象以及它们使用多少空间。
- 每个分配的堆叠追踪[stack trace],包括在哪个线程中。
- 对象在何时_被取消分配_(仅当使用运行 Android 8.0 或更高版本的设备时)。
如果您的设备运行 Android 8.0 或更高版本,您可以随时按照下述方法查看您的对象分配: 只需点击并按住时间线,并拖动选择您想要查看分配的区域(如视频 1 中所示)。 不需要开始记录会话,因为 Android 8.0 及更高版本附带设备内置分析工具,可持续跟踪您的应用分配。
如果您的设备运行 Android 7.1 或更低版本,则在 Memory Profiler 工具栏中点击 Record memory allocations 。 记录时,Android Monitor 将跟踪您的应用中进行的所有分配。 操作完成后,点击 Stop recording (同一个按钮;请参阅视频 2)以查看分配。
在选择一个时间线区域后(或当您使用运行 Android 7.1 或更低版本的设备完成记录会话时),已分配对象的列表将显示在时间线下方,按类名称[class name]进行分组,并按其堆计数[heap count]排序。
注:在 Android 7.1 及更低版本上,您最多可以记录 65535 个分配。 如果您的记录会话超出此限值,则记录中仅保存最新的 65535 个分配。 (在 Android 8.0 及更高版本中,则没有实际的限制。)
要检查分配记录,请按以下步骤操作:
- 浏览列表以查找堆计数异常大且可能存在泄漏的对象。 - 为帮助查找已知类,点击 Class Name 列标题以按字母顺序排序。 然后点击一个类名称。 此时在右侧将出现 Instance View 窗格,显示该类的每个实例,如图 3 中所示。
- 在 Instance View 窗格中,点击一个实例。 此时下方将出现 Call Stack 标签,显示该实例被分配到何处以及哪个线程中。
- 在 Call Stack 标签中,点击任意行以在编辑器中跳转到该代码。
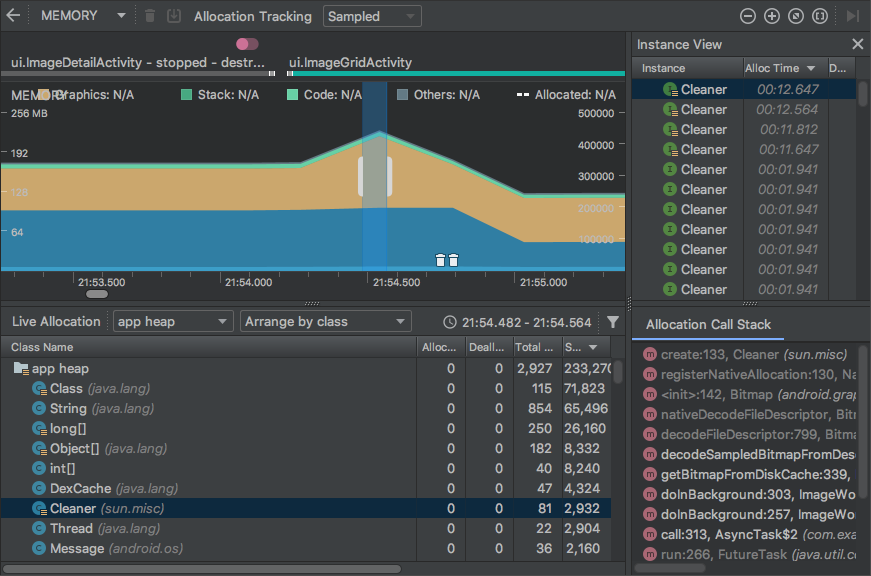
默认情况下,左侧的分配列表按类名称排列。 在列表顶部,您可以使用右侧的下拉列表在以下排列方式之间进行切换:
- Arrange by class:基于类名称对所有分配进行分组。
- Arrange by package:基于软件包名称对所有分配进行分组。
- Arrange by callstack:将所有分配分组到其对应的调用堆栈[Groups all allocations into their corresponding call stack]。
在分析时提高应用程序性能
为了在分析时提高应用程序性能,内存分析器默认情况下会定期对内存分配进行采样[samples ]。 在运行API级别26或更高级别的设备上进行测试时,可以使用“Allocation Tracking”下拉列表更改此行为。

可用选项如下:
- Full:捕获内存中的所有对象分配。 这是Android Studio 3.2及更早版本中的默认行为。 如果您有一个分配了大量对象的应用程序,您可能会在分析时观察到应用程序的可见速度下降[observe visible slowdowns]。
- Sampled:定期在内存中采样对象分配。 这是默认选项,在分析时对应用程序性能的影响较小。 在很短的时间内分配大量对象的应用程序仍然可能会出现明显的减速。
- Off:停止跟踪应用的内存分配。
注意:默认情况下,Android Studio会在执行CPU录制时停止跟踪实时分配,并在CPU录制完成后重新打开。 您可以在CPU录制配置对话框中更改此行为。
查看全局JNI引用
Java Native Interface(JNI)是一个允许Java代码和 native code 相互调用的框架。
JNI引用由 native code 手动管理,因此 native code 使用的Java对象可能会保持活动太长时间。如果在没有先明确删除[first being explicitly deleted]的情况下丢弃JNI引用,Java堆上的某些对象可能无法访问。此外,可能耗尽[exhaust]全局JNI引用限制。
要解决此类问题,请使用Memory Profiler中的 JNI heap 视图浏览所有全局JNI引用,并按Java类型和本机调用堆栈对其进行过滤。通过此信息,您可以找到创建和删除全局JNI引用的时间和位置。
在您的应用程序运行时,选择要检查的时间轴的一部分,然后从 class list 上方的下拉菜单中选择JNI堆。然后,您可以像往常一样检查堆中的对象,然后双击 Allocation Call Stack 选项卡中的对象,以查看在代码中分配和释放JNI引用的位置,如图4所示。
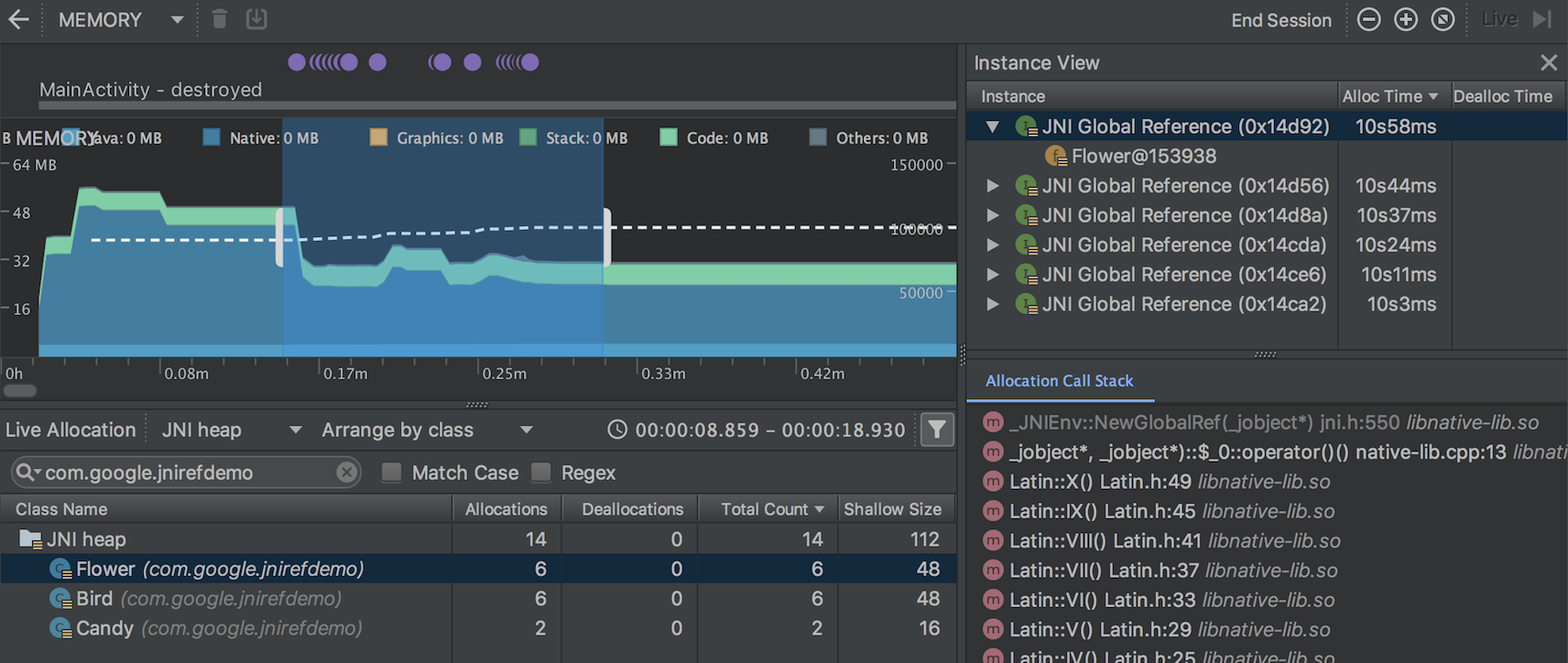
要检查应用程序的JNI代码的内存分配,您必须将应用程序部署到运行Android 8.0或更高版本的设备。
捕获堆转储
堆转储显示在您捕获堆转储时您的应用中哪些对象正在使用内存。 特别是在长时间的用户会话后,堆转储会显示您认为不应再位于内存中却仍在内存中的对象,从而帮助识别内存泄漏。 在捕获堆转储后,您可以查看以下信息:
您的应用已分配哪些类型的对象,以及每个类型分配多少。 每个对象正在使用多少内存。 在代码中的何处仍在引用每个对象。 对象所分配到的调用堆栈。(目前,如果您在记录分配时捕获堆转储,则只有在 Android 7.1 及更低版本中,堆转储才能使用调用堆栈。)
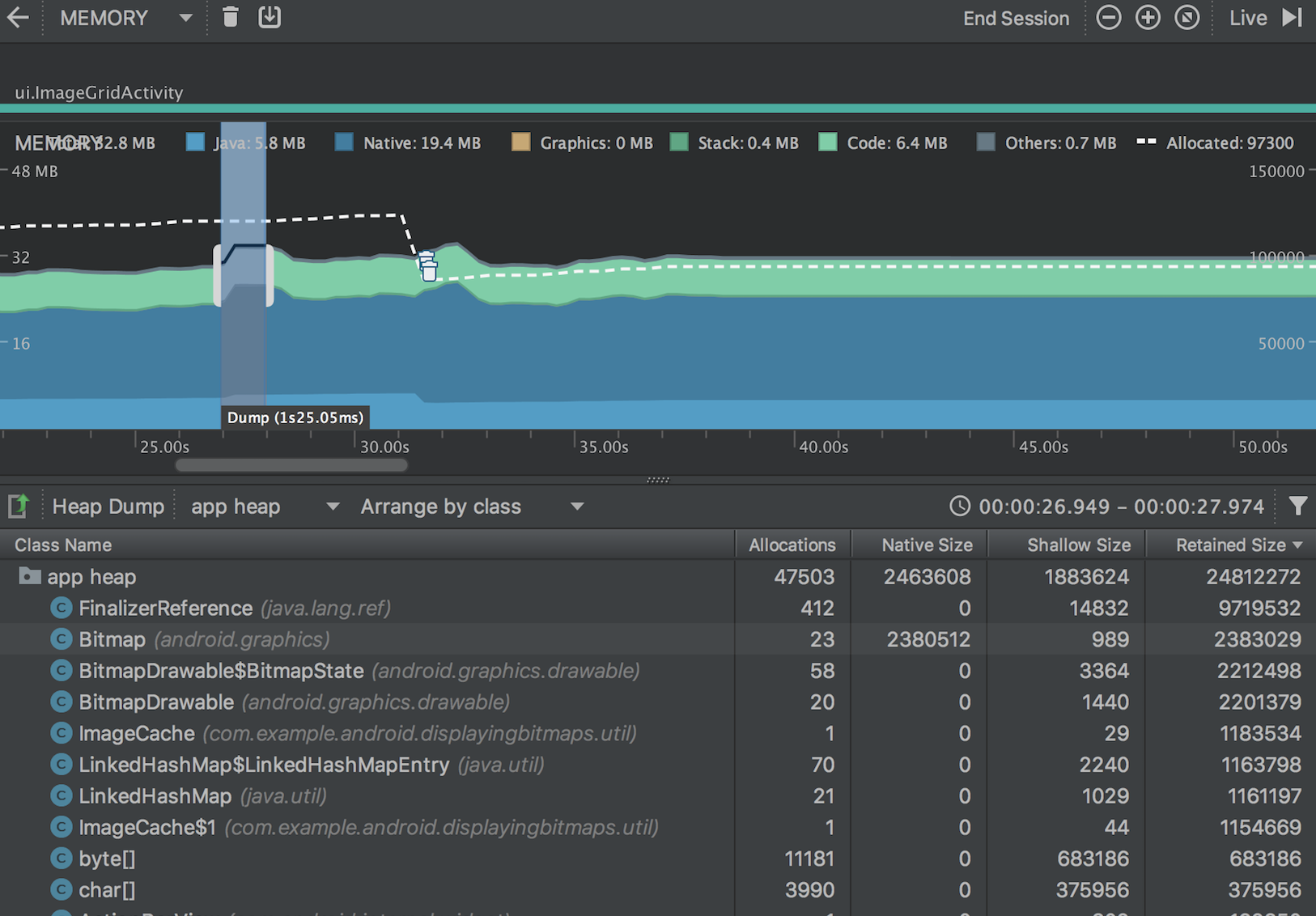
在类列表中,您可以查看以下信息:
Allocations: 堆中分配数 Native Size: 此对象类型使用的native内存总量。 此列仅适用于Android 7.0及更高版本。您将在这里看到一些用Java分配内存的对象,因为Android使用native内存来处理某些框架类,例如Bitmap。 Shallow Size: 此对象类型使用的Java内存总量 Retained Size: 因此类的所有实例而保留的内存总大小
您可以使用已分配对象列表上方的两个菜单来选择要检查的堆转储以及如何组织数据。
从左侧的菜单中,选择要检查的堆:
Default heap:系统未指定堆时。 App heap:您的应用在其中分配内存的主堆[primary heap]。 Image heap:系统启动映像[system boot image],包含启动期间预加载[preloaded]的类。 此处的分配保证绝不会移动或消失。 Zygote heap:copy-on-write heap,其中的应用进程是从 Android 系统中派生[forked]的。 从右侧菜单中选择如何排列分配:
Arrange by class:基于类名称对所有分配进行分组。 Arrange by package:基于软件包名称对所有分配进行分组。 Arrange by callstack:将所有分配分组到其对应的调用堆栈。此选项仅在记录分配[recording allocations]期间捕获堆转储[capture the heap dump]时才有效。即使如此,堆中的对象也很可能是在您开始记录之前分配的,因此这些分配会首先显示,且只按类名称列出。 默认情况下,此列表按 Retained Size 列排序。 您可以点击任意列标题以更改列表的排序方式。
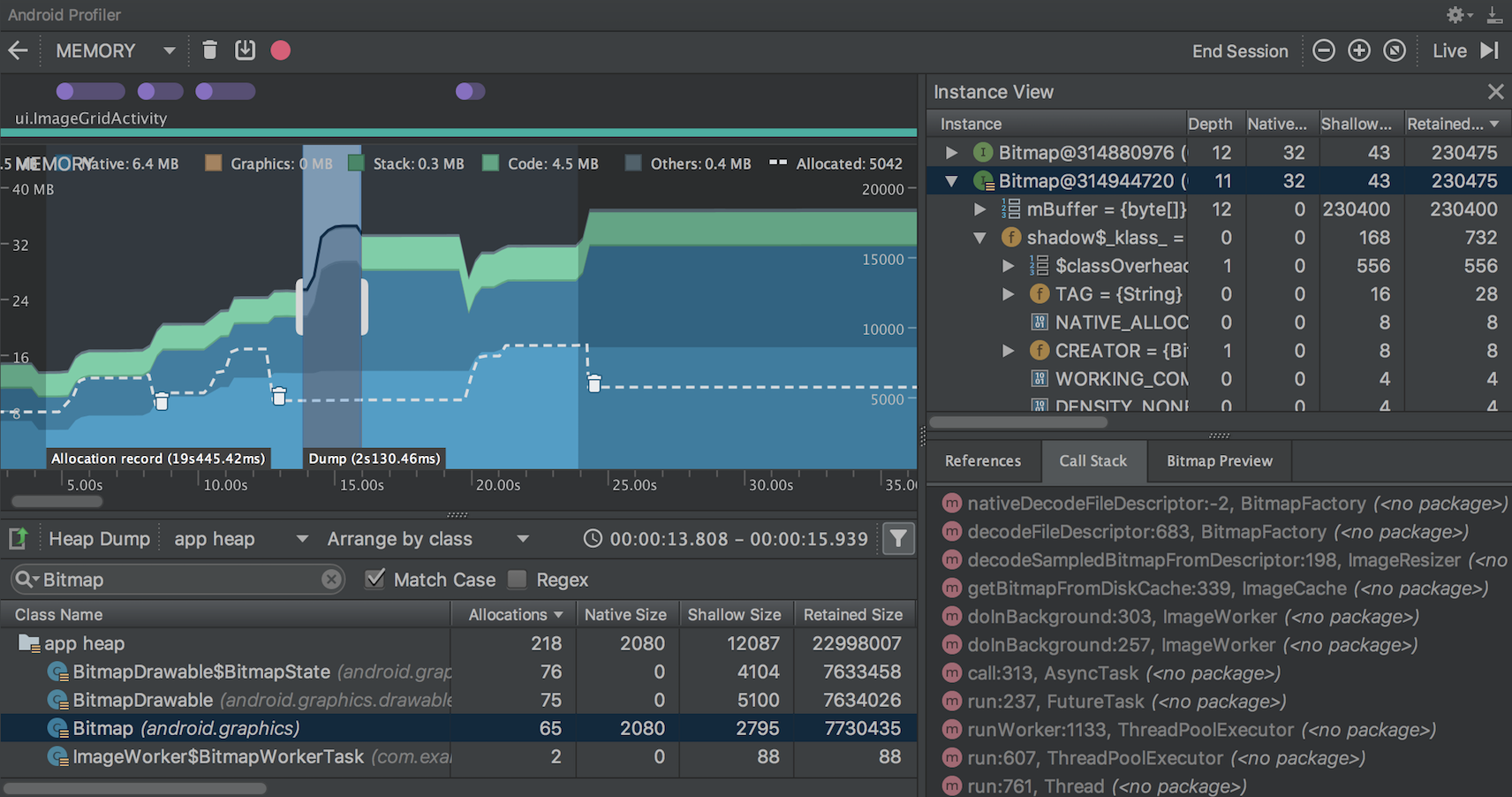
在 Instance View 中,每个实例都包含以下信息:
Depth:从任意 GC root 到所选实例的最短 hops 数。 Native Size: native内存中此实例的大小。此列仅适用于Android 7.0及更高版本。 Shallow Size:此实例Java内存的大小。 Retained Size:此实例支配[dominator]的内存大小(根据 [dominator 树](en.wikipedia.org/wiki/Domina…
要检查您的堆,请按以下步骤操作:
1、浏览列表以查找堆计数[heap counts]异常大且可能存在泄漏的对象。 为帮助查找已知类,点击 Class Name 列标题以按字母顺序排序。 然后点击一个类名称。 此时在右侧将出现 Instance View 窗格,显示该类的每个实例,如图 5 中所示。
或者,您可以通过单击 Filter 或按 Control + F 并在搜索字段中输入类名或包名来快速定位对象。 也可以从下拉菜单中选择 Arrange by callstack 来按方法名称搜索。如果要使用正则表达式,请选中Regex旁边的框。如果您的搜索查询区分大小写,请选中匹配大小写旁边的框。
2、在 Instance View 窗格中,点击一个实例。此时下方将出现 References,显示该对象的每个引用。或者,点击实例名称旁的箭头以查看其所有字段,然后点击一个字段名称查看其所有引用。 如果您要查看某个字段的实例详情,右键点击该字段并选择 Go to Instance。
3、在 References 标签中,如果您发现某个引用可能在泄漏内存,则右键点击它并选择 Go to Instance。 这将从堆转储中选择对应的实例,显示您自己的实例数据。
在您的堆转储中,请注意由下列任意情况引起的内存泄漏:
长时间引用 Activity、Context、View、Drawable 和其他对象,可能会保持对 Activity 或 Context容器的引用。 可以保持 Activity 实例的非静态内部类,如 Runnable。 对象保持时间超出所需时间的缓存。
将堆转储另存为 HPROF
在捕获堆转储后,仅当分析器运行时才能在 Memory Profiler 中查看数据。 当您退出分析会话时,您将丢失堆转储。 因此,如果您要保存堆转储以供日后查看,可通过点击时间线下方工具栏中的 Export heap dump as HPROF file,将堆转储导出到一个 HPROF 文件中。 在显示的对话框中,确保使用 .hprof 后缀保存文件。
然后,通过将此文件拖到一个空的编辑器窗口(或将其拖到文件标签栏中),您可以在 Android Studio 中重新打开该文件。
要使用其他 HPROF 分析器(如 jhat),您需要将 HPROF 文件从 Android 格式转换为 Java SE HPROF 格式。 您可以使用 android_sdk/platform-tools/ 目录中提供的 hprof-conv 工具执行此操作。 运行包括以下两个参数的 hprof-conv 命令:原始 HPROF 文件和转换后 HPROF 文件的写入位置。 例如:
hprof-conv heap-original.hprof heap-converted.hprof
导入堆转储文件 要导入HPROF(.hprof)文件,请单击 Sessions 窗格中 Load from file,然后从文件浏览器中选择该文件。

您还可以通过将 HPROF 文件从文件浏览器拖到编辑器窗口中来导入HPROF文件。
分析内存的技巧
使用 Memory Profiler 时,您应对应用代码施加压力[stress your app code]并尝试强制内存泄漏。在应用中引发内存泄漏的一种方式是,先让其运行一段时间,然后再检查堆。泄漏在堆中可能逐渐汇聚到分配顶部[Leaks might trickle up to the top of the allocations in the heap]。不过,泄漏越小,您越需要运行更长时间才能看到泄漏。
您还可以通过以下方式之一触发内存泄漏:
将设备从纵向旋转为横向,然后在不同的 Activity 状态下反复操作多次。 旋转设备经常会导致应用泄漏 Activity、Context、View 对象,因为系统会重新创建 Activity,而如果您的应用在其他地方保持对这些对象之一的引用,系统将无法对其进行垃圾回收。 处于不同的 Activity 状态时,在您的应用与另一个应用之间切换(导航到主屏幕,然后返回到您的应用)。
MAT
MAT,Memory Analyzer Tool,它可以帮助我们查找内存泄漏和查看内存消耗情况。使用内存分析工具从众多的对象中进行分析,快速的计算出在内存中对象的占用大小,看看是谁阻止了垃圾收集器的回收工作,并可以通过报表直观的查看到可能造成这种结果的对象。
可以在应用内使用 android.os.Debug.dumpHprofData(String fileName) 接口主动抓取应用的内存堆栈。只需要在程序运行时调用 dumpHprofData(String fileName) 静态接口即可将应用内存导出到文件。如下是一段在应用异常退出时抓取内存的示例代码仅供参考:
public class CaptureHeapDumpsApplication extends Application {
private static final String FILE_NAME = "/data/local/tmp/heap-dump.hprof";
@Override
public void onCreate() {
super.onCreate();
Thread.currentThread().setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
String absolutePath = new File(FILE_NAME).getAbsolutePath();
try {
Debug.dumpHprofData(absolutePath);
} catch (IOException e1) {
e1.printStackTrace();
}
}
});
}
}
获取及打开 .hprof 文件
使用MAT既可以打开一个已有的堆快照,也可以通过MAT直接从活动Java程序中导出堆快照。
HPROF文件是MAT能识别的文件,HPROF文件存储的是特定时间点,java进程的内存快照。有不同的格式来存储这些数据,总的来说包含了快照被触发时java对象和类在heap中的情况。由于快照只是一瞬间的事情,所以heap dump中无法包含一个对象在何时、何地(哪个方法中)被分配这样的信息。
如果HPROF文件是通过AndroidStudio的profile工具导出的,由于这个不是 mat 工具用到的标准文件,我们需要使用 sdk 自带的platform-tools/hprof-conv.exe工具进行转换,命令为:
hprof-conv -z 1.hprof 1_mat.hprof
注意:最好将.hprof文件放在一个单独的文件夹内打开,因为你在操作过程中,会生成大量的临时文件。
工具栏

Overview:主界面
Histogram:直方图
Dominator Tree:支配树
OQL:Object Query Language studio
Thread OvewView:查看这个应用所有的Thread信息
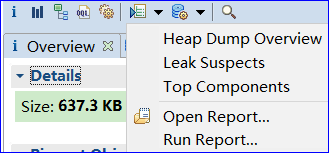
Run Expert System Test:运行专家系统测试
Query Browser:查询浏览器
Find Object By Address
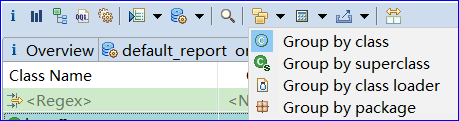
Group:在Histogram和Domiantor Tree界面,可以选择将结果用另一种Group的方式显示(默认是Group by Object),切换到Group by package可以更好地查看具体是哪个包里的类占用内存大,也很容易定位到自己的应用程序。

Calculate Retained Size:点击后,会出现Retained Size这一列
主界面 Overview
我们需要关注的是下面Actions区域,介绍4种分析方法:
Histogram: Lists number of instances per class 列出内存中的对象,对象的个数以及大小
Dominator Tree: List the biggest objects and what they keep alive. 列出最大的对象以及其依赖存活的Object,大小是以Retained Heap为标准排序的
Top Consumers: Print the most expensive objects grouped by class and by package. 通过图形列出最大的object
Duplicate Classes: Detect classes loaded by multiple class loaders. 通过MAT自动分析泄漏的原因
default_report 窗口
该窗口列出了可能有问题的代码片段。点击每个问题中的Details可以查看相关的详情。
详情页面包含如下内容
Description:问题简要描述 Shortest Paths To the Accumulation Point:在此列表中,我们可以追溯到问题代码的类树的结构,并找到自己代码中的类。 Accumulated Objects in Dominator Tree:在此列表中,我们可以看见创建的大量的对象 Accumulated Objects by Class in Dominator Tree:在此列表中,我们能看见创建大量对象相关的类。 All Accumulated Objects by Class:在此列表中,会按类别划分的所有累计对象。
两个重要概念
Shallow heap:本身占用内存 Shallow size就是对象本身占用内存的大小,不包含其引用的对象。
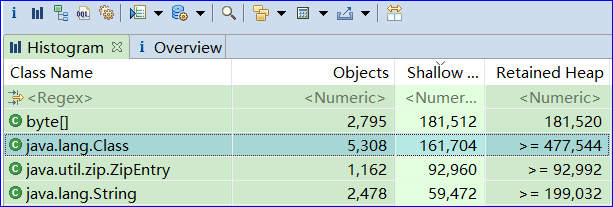
常规对象(非数组)的Shallow size由其成员变量的数量和类型决定 数组类型的对象的shallow size由数组元素的类型(对象类型、基本类型)和数组长度决定 注意:因为不像c++的对象本身可以存放大量内存,java的对象成员都是些引用。真正的内存都在堆上,看起来是一堆原生的byte[]、char[]、int[],所以我们如果只看对象本身的内存,那么数量都很小。所以我们看到 Histogram 图是以Shallow size进行排序的,排在第一位的一般都是byte[]。
Retained Heap:引用占用内存 Retained Heap的概念,它表示如果一个对象被释放掉,那么该对象引用的所有对象,包括被递归引用的对象,被释放的内存。
例如,如果一个对象的某个成员new了一大块int数组,那这个int数组也可以计算到这个对象中。与shallow heap比较,Retained heap可以更精确的反映一个对象实际占用的大小,因为如果该对象释放,retained heap都可以被释放。
但是,Retained Heap并不总是那么有效。 例如,我在A里new了一块内存,赋值给A的一个成员变量,同时我让B也指向这块内存。此时,因为A和B都引用到这块内存,所以A释放时,该内存不会被释放。所以这块内存不会被计算到A或者B的Retained Heap中。
为了纠正这点,MAT中的 Leading Object(例如A或者B)不一定只是一个对象,也可以是多个对象。此时,(A,B)这个组合的Retained Set就包含那块大内存了。对应到MAT的UI中,在Histogram中,可以选择 Group By class, superclass or package来选择这个组。
为了计算Retained Memory,MAT引入了Dominator Tree。
例如,对象A引用B和C,B和C又都引用到D,计算Retained Memory时:
A的包括A本身和B,C,D。 B和C因为共同引用D,所以B,C 的Retained Memory都只是他们本身。 D当然也只是自己。 在这里例子中,树根是A,而B,C,D是他的三个儿子,B,C,D不再有相互关系。
我觉得是为了加快计算的速度,MAT将对象引用图转换成对象引用树。把引用图变成引用树后,计算Retained Heap就会非常方便,显示也非常方便。对应到 MAT UI 上,在 dominator tree 这个view中,显示了每个对象的 shallow heap 和 retained heap。然后可以以该节点为树根,一步步的细化看看 retained heap 到底是用在什么地方了。
这种从图到树的转换确实方便了内存分析,但有时候会让人有些疑惑。本来对象B是对象A的一个成员,但因为B还被C引用,所以B在树中并不在A下面,而很可能是平级。
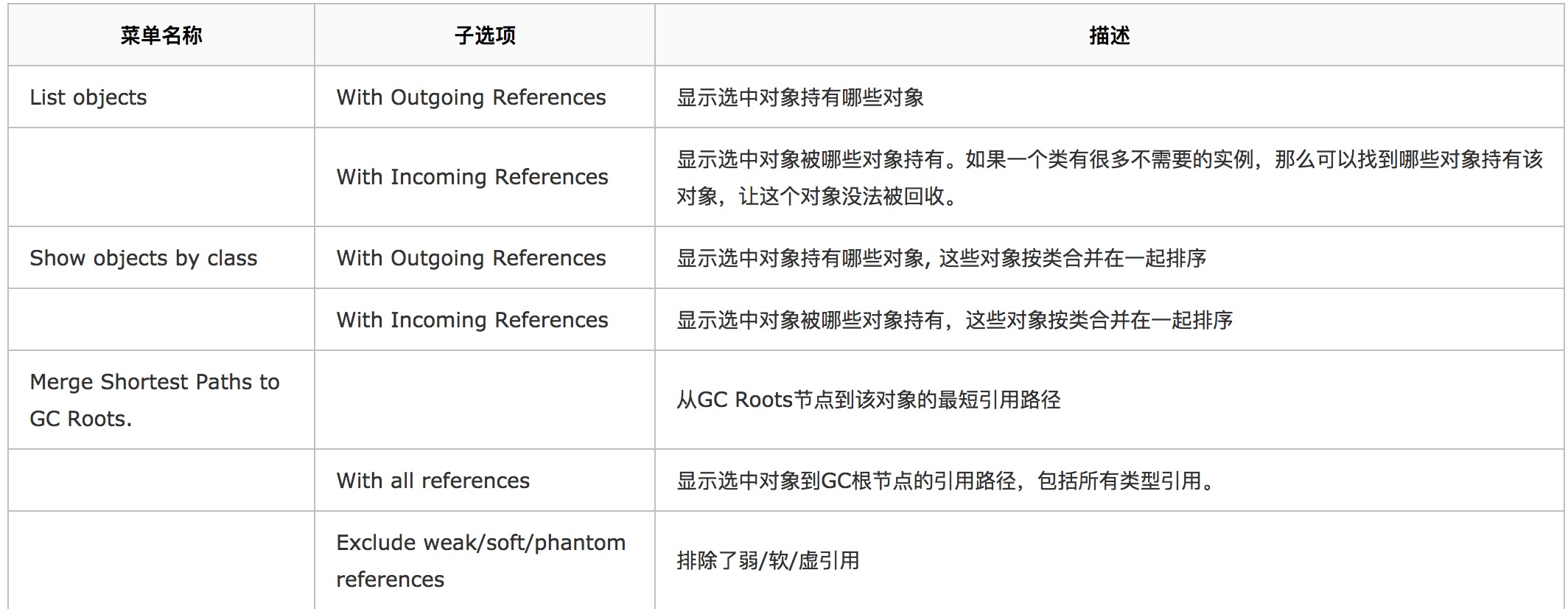
为了纠正这点,MAT中点击右键,可以 List objects 中选择 with outgoing references 和 with incoming references。这是个真正的引用图的概念,
outgoing references :表示该对象的出节点(被该对象引用的对象) incoming references :表示该对象的入节点(引用到该对象的对象) 为了更好地理解 Retained Heap,下面引用一个例子来说明:
把内存中的对象看成下图中的节点,并且对象和对象之间互相引用。这里有一个特殊的节点GC Roots,这就是reference chain(引用链)的起点:
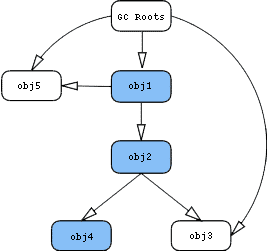
上图中蓝色节点代表仅仅只有通过obj1才能直接或间接访问的对象。因为可以通过GC Roots访问,所以上图的obj3不是蓝色节点。因此上图中obj1的retained size是obj1、obj2、obj4的shallow size总和。
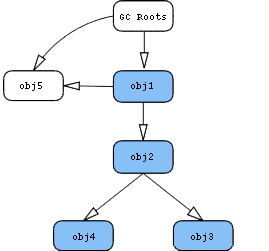
上图obj1的retained size是obj1、obj2、obj3、obj4的shallow size总和。而obj2的retained size是obj3、obj4的shallow size总和。
Histogram 和 Dominator Tree
Histogram的主要作用是查看一个instance的数量,一般用来查看自己创建的类的实例的个数。
可以很容易的找出占用内存最多的几个对象,根据百分比(Percentage)来排序。
可以分不同维度来查看对象的Dominator Tree视图,Group by class、Group by class loader、Group by package
Dominator Tree和Histogram的区别是站的角度不一样,Histogram是站在类的角度上去看,Dominator Tree是站的对象实例的角度上看,Dominator Tree可以更方便的看出其引用关系。
通过查看Object的个数,结合代码就可以找出存在内存泄露的类(即可达但是无用的对象,或者是可以重用但是重新创建的对象)
Histogram中还可以对对象进行Group,更方便查看自己Package中的对象信息。
右键菜单:Query Browser

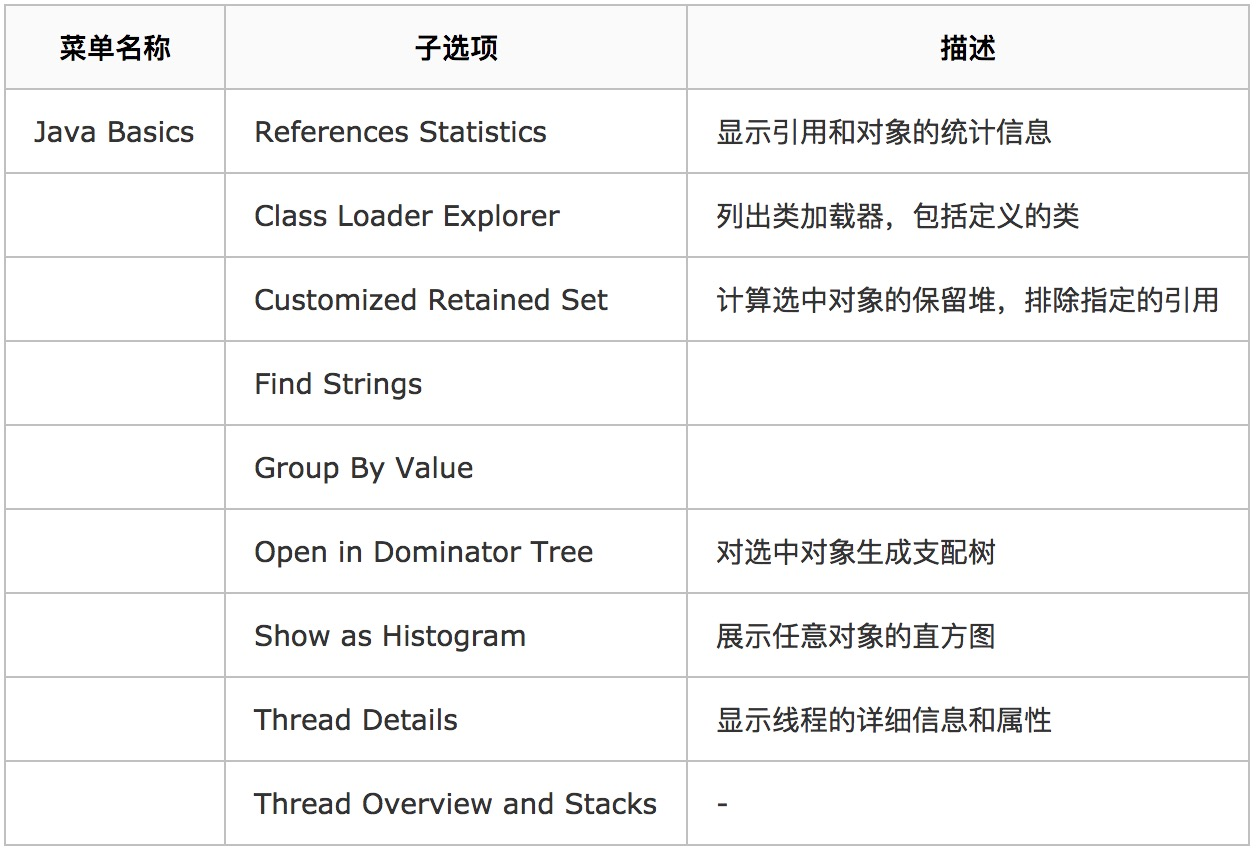
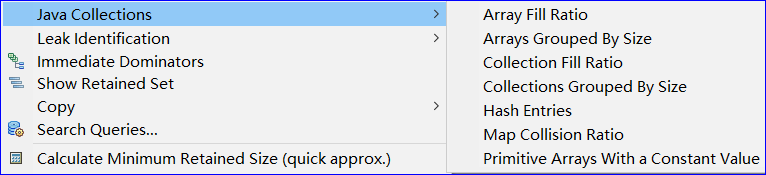

Search Queries:搜索列出所有Queries选项的具体含义,包含搜索区、输入关键字后匹配的Queries选项列表区,点击选项后的具体含义解释区。
可以看到,所有的命令其实就是配置不同的SQL查询语句,比如我们最常用的:
List objects -> with incoming references:查看这个对象持有的外部对象引用 List objects -> with outcoming references:查看这个对象被哪些外部对象引用 Path To GC Roots -> exclude all phantim/weak/soft etc. references:查看这个对象的GC Root,不包含虚、弱引用、软引用,剩下的就是强引用。从GC上说,除了强引用外,其他的引用在JVM需要的情况下是都可以 被GC掉的,如果一个对象始终无法被GC,就是因为强引用的存在,从而导致在GC的过程中一直得不到回收,因此就内存溢出了。 Merge Shortest path to GC root:找到从GC根节点到一个对象或一组对象的共同路径
systrace
systrace 命令可以允许我们在系统层面上,对设备里所有进程的耗时信息进行收集和调研。systrace 结合的分析数据来源于 Android 内核,如 CPU 调度器、磁盘活动和 App 的线程等,会生成一份网页报告如下所示:
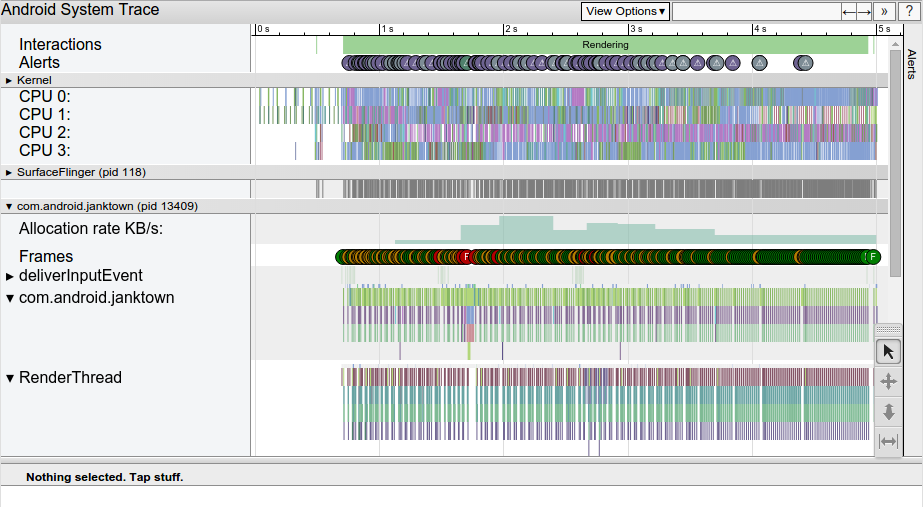
这是一份简单的 systrace 网页报告,显示了和 App 5 秒钟的交互,报告中高亮的帧是 systrace 认为没有合理渲染的地方。
事实上,生成的报告在给定的时间区间,描述了 Android 设备系统进程的全局图。同时,报告检查了抓到的 tracing 信息,并高亮化其观察到的问题,如展示动作或动画时的 UI 卡顿,会提供一些如何修复的建议。此外,systrace 也有它自身的局限性,其无法收集到 App 进程内的代码执行信息。为了获取更多的详细信息,如 App 运行时正在执行的方法、App 使用的 CPU 资源等,使用 Android Studio 内置的 CPU profiler,或生成的 trace 日志,然后使用 Traceview 查看。
具体使用
用户界面调用
打开Android studio,Tools -- Android -- Android Device Monitor,或则直接在sdk中的tools中找到Android Device Monitor打开
在弹出的Android Device Monitor中,左侧Devices选项卡的下面一排,点击下图中圈出的位置
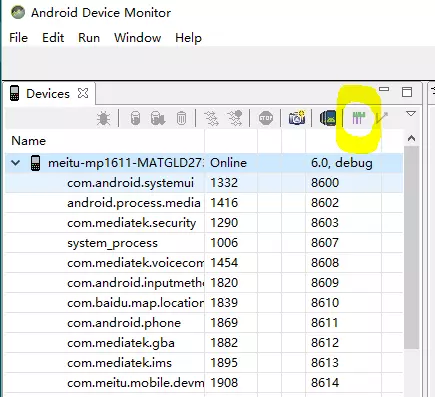
配置trace信息,点击OK后,会在对应目录下生成html文件
命令
为了生成所需要的网页报告,需要在命令行使用下面的命令运行 systrace,即进入android-sdk/platform-tools/systrace/后,执行:
python systrace.py [options] [categories]
举个例子,下面运行 systrace 来记录 10 秒期间设备的进程,包括图像进程,然后生成一份命名为 mynewtrace 的网页报告,执行:
python systrace.py --time=10 -o mynewtrace.html gfx
若没指定任何类别或者选项,systrace 会生成一份报告,包括所有可用的种类,同时使用默认的设置。
通用的选项

命令和命令选项

-e <DEVICE_SERIAL> 或 --serial=<DEVICE_SERIAL> 指定设备的序列号
-d 或 --disk 追踪activity disk的输入和输出,需要root设备
-i 或 --cpu-idle 追踪CPU的idel事件
-l 或 --cpu-load 追踪CPU的加载
-s或--no-cpu-sched 防止CPU调度的追踪,通过降低trace buffer的速率达到加长的trace时长的目的
-u 或 --bus-utilization 追踪bus的使用,需要root设备
-w 或 --workqueue 追踪work queue,需要root设备
对于上面的--set-tags配置,可选项如下:
gfx 图形图像
input 输入
view 视图
webview
wm Window Manager
am Activity Manager
sync Synchronization Manager
audio
video
camera
注意:设置tag后,需要重启framework(’adb shell stop;adb shell start‘)暴躁配置生效。
调研 UI 的性能问题
systrace 尤其在调研 App 的 UI 性能上表现突出,因为其可以分析代码和帧率,来判定问题出现的区域,并给出可能的建议。大致步骤如下:
连上设备,运行 App
在android-sdk/platform-tools/systrace/路径下,执行跑 systrace 的命令如:
python systrace.py view --time=10
手动与 App 交互,如滑动等。10 秒后,systrace 会生成一份网页报告
使用浏览器打开生成的网页报告
可以点击报告,来查看记录期间设备 CPU 的使用。下面给出怎样在报告中调研信息,来找到并修复 UI 的性能问题。
审查帧和警告
如下图所示,报告中列出了渲染 UI 帧的每个进程,显示了时间线里每幅渲染的帧。绿色帧圈的表明,在要求的 16.6 毫秒内保持稳定的 60 帧/秒渲染帧像;黄色或红色帧圈的表明,渲染帧像时花费了超过 16.6 毫秒。
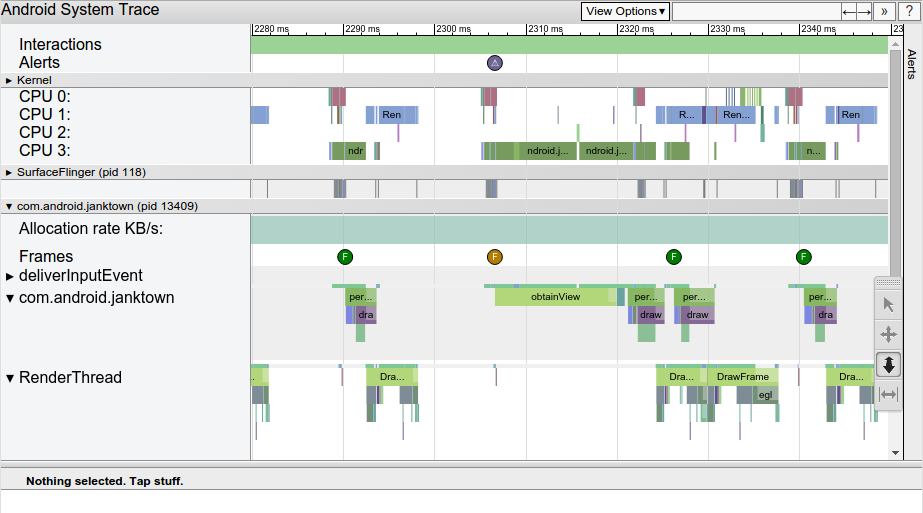
注意,在 Android 5.0 (API level 21) 及更高的设备上,渲染帧像的工作被分隔于 UI 主线程和渲染线程。以前的版本,创建帧像的工作都在 UI 主线程完成。
点击帧圈可以高亮化,提供系统完成渲染帧像额外的信息,包括警告。它也展示渲染帧像时系统正在执行的方法,因此可以根据这些方法来找出 UI 卡顿的原因。选择有问题的帧,trace 报告下面会展示问题详情的一个 alert。
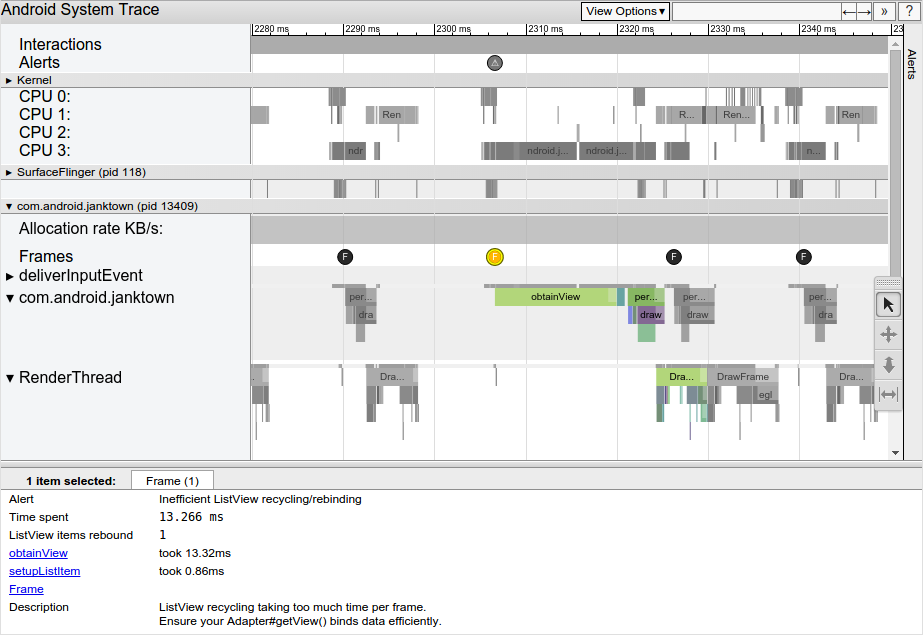
一目了然,trace 中会给出相关事件的链接,来解释在此期间系统运行的详情。
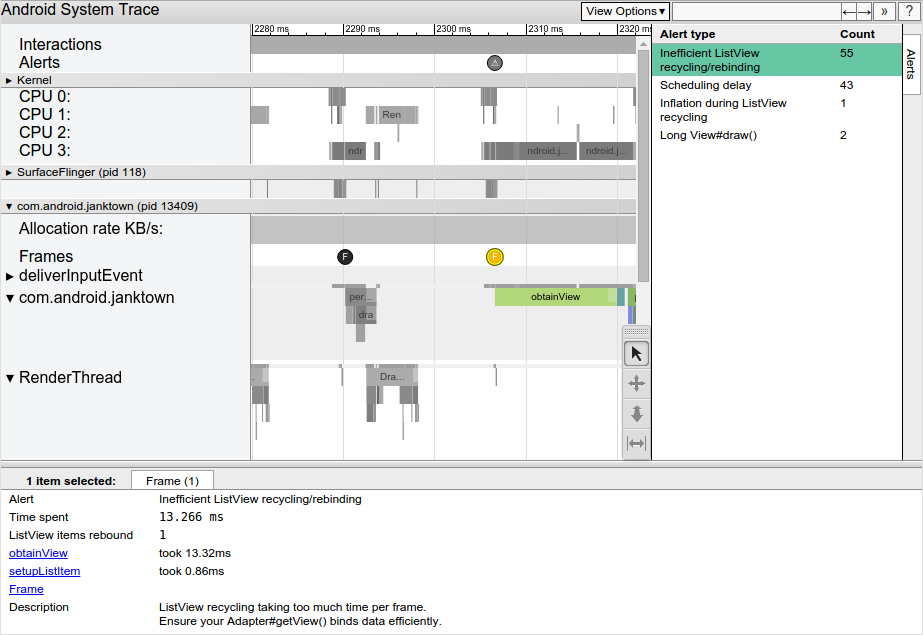
要看 trace 中工具发现的 alert,以及设备触发每个警告的次数,可以点击右上边上的 Alerts tab。Alerts 栏可以显示 trace 里发生的每一个问题和它们导致卡顿的频次。考虑到栏目里一系列待修复的 bugs,一片区域里,一个微小的变化或改进,可以忽略 App 中整个类的警告。
若看到 UI 主线程中做了太多的工作,需要我们自己找出消耗 CPU 时间的那些方法,方法之一是在认为导致性能瓶颈的地方,添加 trace 标记,来查看 trace 中出现的调用方法。若不确定哪些方法或许导致 UI 主线程的瓶颈,使用 Android Studio 内置的 CPU profiler,或生成的 trace 日志,然后使用 Traceview 查看。
植入你 App 的代码
由于 systrace 只在系统层级显示进程的信息,因此很难通过网页报告知道给定的时间内,App 究竟执行了哪些方法。在 Android 4.3 (API level 18) 及以上,可以在代码中使用 Trace 类来在网页报告中标记执行的事件。事实上,不需要植入代码中,用 systrace 记录 traces,这样做能帮助我们定位,代码的哪一块也许是造成线程阻塞或 UI 卡顿的原因。这个方法和 Debug 类不同,Trace 类只是简单地在 systrace 报告中添加标记,而 Debug 类通过生成 .trace 文件帮助我们审查使用 App 时 CPU 详细的使用信息。
注意,为了生成包括 trace 事件的 systrace 网页报告,需要指定 -a 或 - -app 的命令来运行 systrace,这样来指定 App 的包名。
下面给出如何使用 Trace 类来标记执行方法的示例,包括两个嵌套的代码块:
public class MyAdapter extends RecyclerView.Adapter<MyViewHolder> {
...
@Override
public MyViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {
Trace.beginSection("MyAdapter.onCreateViewHolder");
MyViewHolder myViewHolder;
try {
myViewHolder = MyViewHolder.newInstance(parent);
} finally {
// try...catch 语句中, 总是要调用 endSection(), 在 finally 语句
// 中调用以确保即使抛出异常时 endSection() 也能执行
Trace.endSection();
}
return myViewHolder;
}
@Override
public void onBindViewHolder(MyViewHolder holder, int position) {
Trace.beginSection("MyAdapter.onBindViewHolder");
try {
try {
Trace.beginSection("MyAdapter.queryDatabase");
RowItem rowItem = queryDatabase(position);
mDataset.add(rowItem);
} finally {
Trace.endSection();
}
holder.bind(mDataset.get(position));
} finally {
Trace.endSection();
}
}
...
}
注意,当多次调用 beginSection() 时,调用 endSection() 只终止最近一次调用的 beginSection() 方法。因此,对于嵌套调用,如上面的代码所示,确保每次调用 beginSection(),同样恰当地调用到 endSection()。此外,不能在一个线程调用 beginSection(),然后从另一个线程终止,而应该在相同的线程调用到 endSection() 方法。
了解 systrace
在开发应用时,通常使用60fps的帧率来检测交互是否流畅,如果中途出错了,或者发生了掉帧,解决这个问题的第一步应当是搞清楚当前系统在做什么。
systrace工具可以在程序运行的时候收集实时的信息,记录时间以及CPU的分配情况,记录每个线程和进程在任意时间的运行情况,可以自动分析出一些重要的原因,并且给出建议。
预览
Systrace可以帮助你分析应用是如何设备上运行起来的,它将系统和应用程序线程集中在一个共同的时间轴上,分析systrace的第一步需要在程序运行的时间段中抓取trace log,在抓取到的trace文件中,包含了这段时间中你想要的关键信息,交互情况。
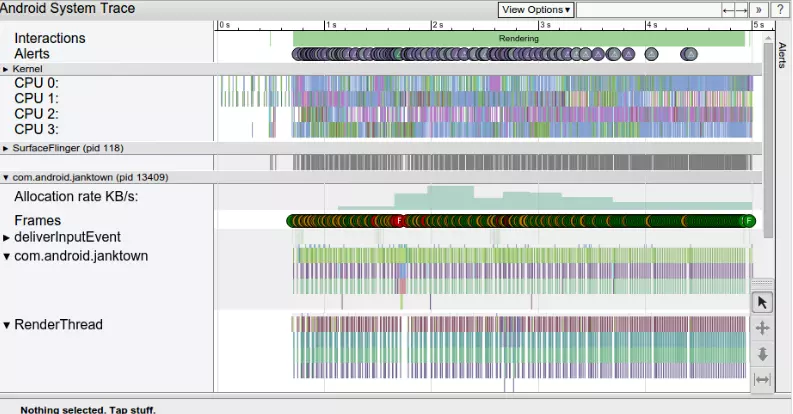
从上到下的信息分别为Kernel,SurfaceFlinger,应用包名。通过配置trace的分类,可以根据配置情况记录每个应用程序的所有线程信息以及trace event的层次结构信息。
systrace 的工作原理
systrace是一个分析android性能问题的基础工具,但本质上是其他某些工具的封装,包括:PC端的atrace,设备端的可执行文件(用于控制用户控件的追踪以及配置ftrace,即Linux内核中的主要跟踪机制)。Systrace使用atrace开启追踪,然后读取ftrace的缓存,并且把它重新转换成HTML格式。
ftrace相比与systrace和atrace具有更多的功能,并且包含一些对调试性能问题至关重要的高级功能。 (这些功能需要root权限)
运行systrace
./systrace.py sched freq idle am wm gfx view sync binder_driver irq workq input -b 96000
当systrace与GPU和显示管道活动所需的附加跟踪点结合使用时,您可以跟踪所有从用户输入到屏幕显示的帧。设置大的缓冲区可以避免事件的丢失(通常表现为某些CPU在跟踪中的某个点之后没有任何事件)。
当使用systrace时,注意每个事件都是在CPU上触发的。
注意:硬件中断不受CPU控制也不会在ftrace中触发事件,实际提交到跟踪日志是由中断处理程序完成的,但一些损坏的驱动会造成中断的延迟,因此最关键点因素还是CPU本身。
因为systrace构建在ftrace之上,ftrace在CPU上运行,所以硬件改变log必然会写入到的ftrace缓冲区。这就意味着如果你好奇为什么显示栏改变了,那么你可以看CPU在该转换点上的运行内容(CPU上运行的事件均被保存到log中)。这个概念是使用systrace分析性能的基础。
例子:working frame
这是一个描述正常UI管道过程的systrace,请事先下载好zip文件,点击下载zip文件,解压并在浏览器中打开systrace_tutorial.html,注意:这个文件要比一般的html文件大得多。
对于一个持续的定期的工作负载,例如TouchLatency,UI管道,通常包含以下阶段:
SurfaceFlinger中的EventThread唤醒了应用程序UI线程,表明现在是渲染新帧的时候了。
应用程序使用CPU和GPU资源在UI线程,RenderThread和hwuiTasks中渲染帧。这部分暂UI的大部分。
应用程序通过binder将绘制好的帧发送到SurfaceFlinger并进入睡眠状态。
SurfaceFlinger中的第二个EventThread唤醒SurfaceFlinger来触发组合和显示输出。如果SurfaceFlinger确定没有任何工作要完成,它将返回睡眠状态。
SurfaceFlinger通过HWC / HWC2或GL处理组合。 HWC / HWC2组合更快,更低的功耗,但会受到SOC的限制。这一步通常需要4-6ms,但是 可以与步骤2重叠,因为Android应用程序总是三重缓冲。 (虽然应用程序总是三重缓冲,但在SurfaceFlinger中只能有一个待处理帧,因此和双重缓存差不多。)
SurfaceFlinger通过供应商驱动程序调度最终输出,并返回睡眠状态,等待EventThread唤醒。
让我们从15409ms开始查看帧:
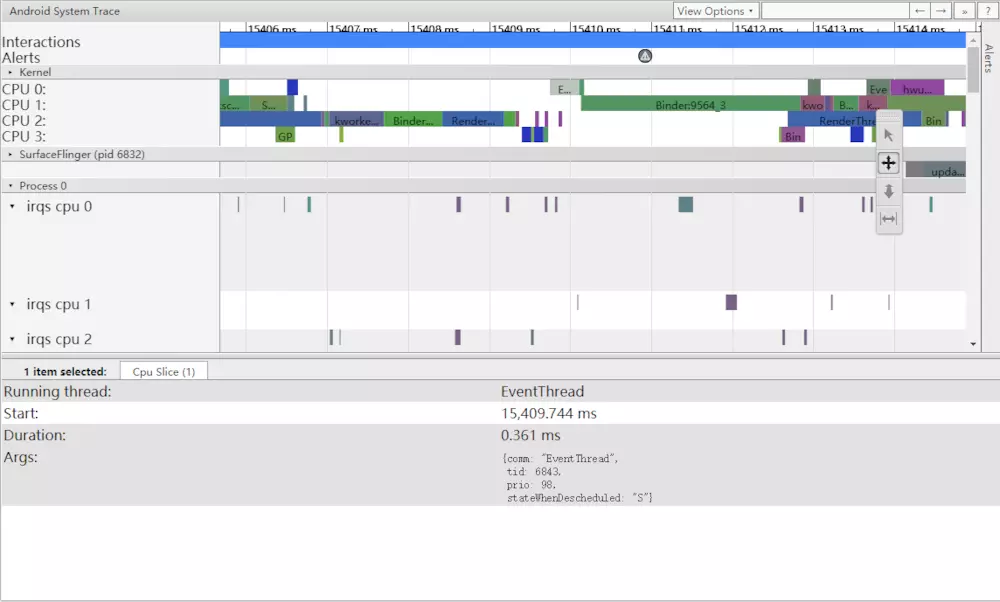
图1是正常的帧(对应阶段1),要了解UI管道如何工作这是一个很好的示范。 TouchLatency的UI线程行在不同时间包含不同的颜色。 不同的线代表线程的不同状态:
灰色: 睡眠。
蓝色: 可以运行(它可以运行,但还未被调度运行)。
绿色: 正在运行(调度程序认为它正在运行)。
注意:中断处理程序没有CPU时间轴中显示,因此在线程运行的过程中虽然没有显示中断,但实际上你可能已经执行了中断或者softirqs,最终需要通过检查trace(进程0)来判断中断是否发生。
红色: 不间断的睡眠(通常发生在内核锁上), 指出I / O负载,对于性能问题的调试非常有用。
橙色: 由于I / O负载导致的不间断睡眠。 要查看不间断睡眠的原因(可从sched_blocked_reason跟踪点获取),请选择红色不间断睡眠切片。
当EventThread正在运行时,TouchLatency的UI Thread就变成了可以运行的蓝色。 要查看是什么,请点击蓝色部分:
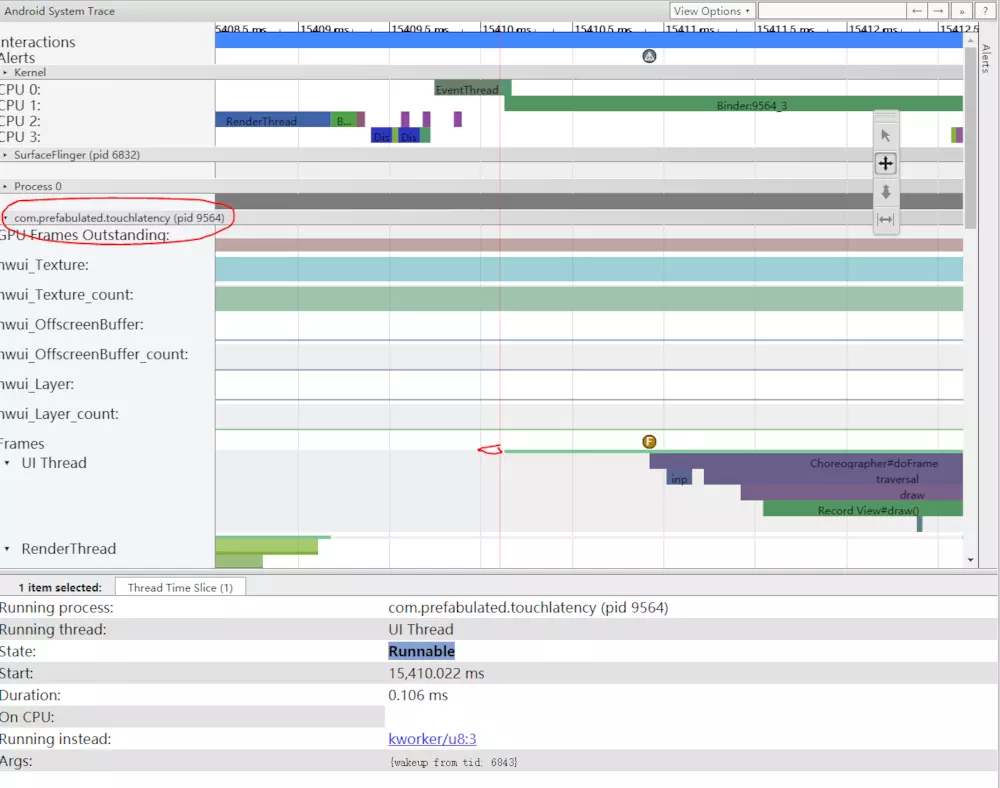
图2(对应阶段1) 显示的是EventThread运行后,TouchLatency的tid6843唤醒UIThread为其工作,这一个信息可以从下方的“wakeup from tid:6843”看出
如果'binder_drivier'tag被开启后,你可以选择binder transaction来查看整个过程。
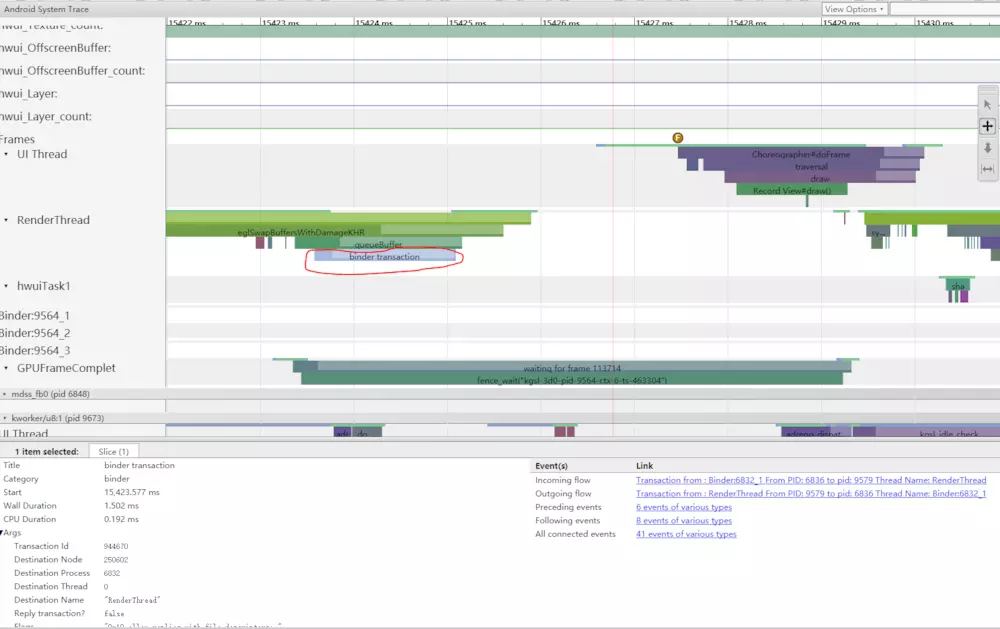
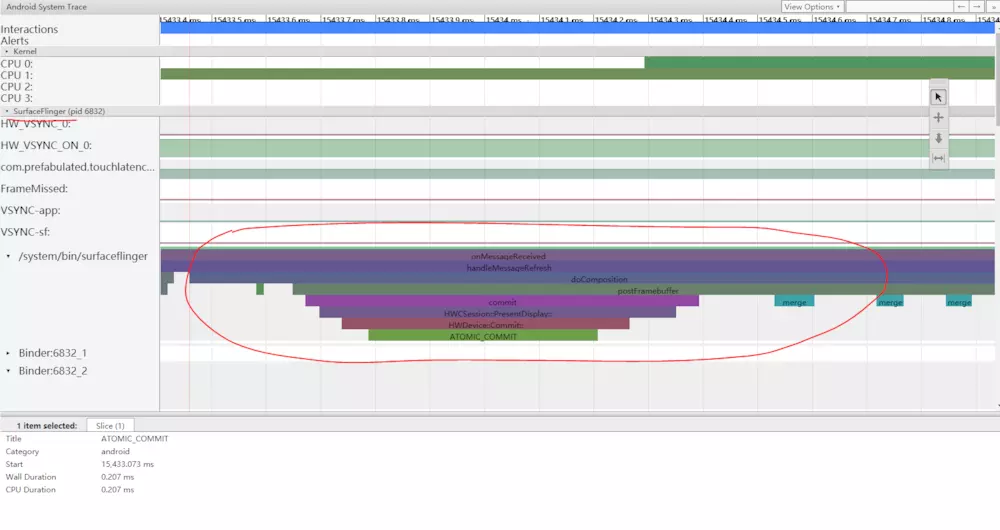
图4(对应阶段3) Binder transaction 如图4所示,在15423ms处,SurfaceFlinger的Binder:6832_1由于pid9579的调用变为了可运行状态。在binder tracsaction的两侧你也可以看到缓冲队列。 在SurfaceFlinger的queueBuffer中,TouchLtency的待绘制帧数量从1变为了2.
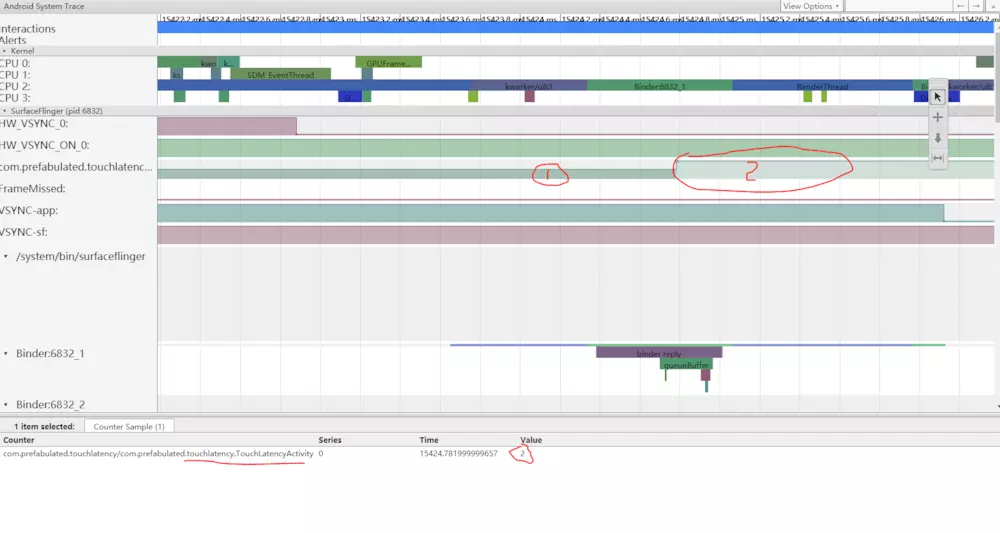
图5显示了三重缓冲,其中有两个完整的帧,应用程序将很快开始渲染第三个帧。 这是因为我们已经删除了一些帧,所以应用程序会保留两个挂起的帧而不是一个帧,以避免跳帧。
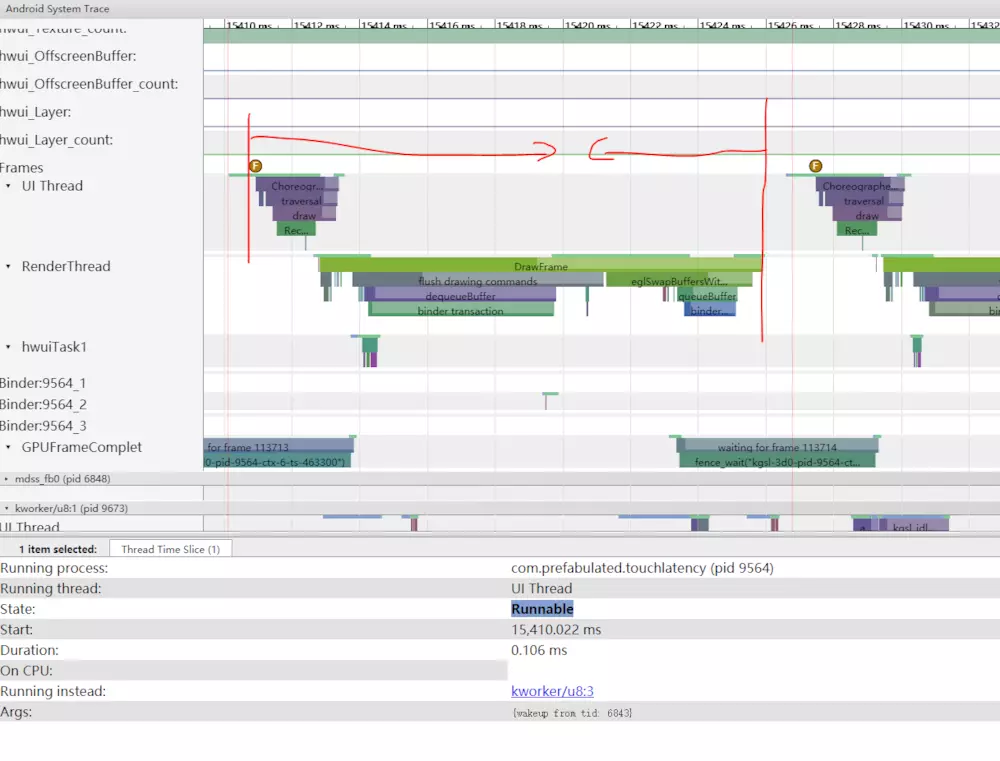
随后,SurfaceFlinger的主线程被第二个EventThread唤醒,因此它可以将的待处理帧输出到显示器:
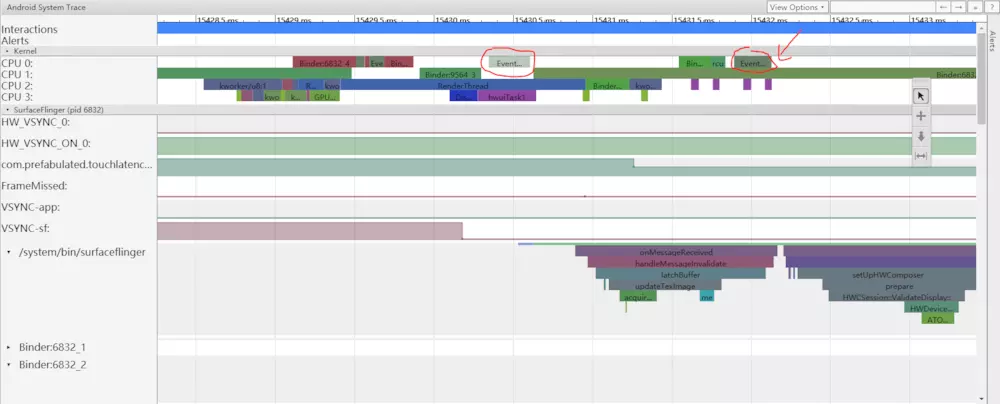
SurfaceFlinger首先锁定较早的待绘制缓冲区,这将导致挂起的缓冲区数从2减为1:
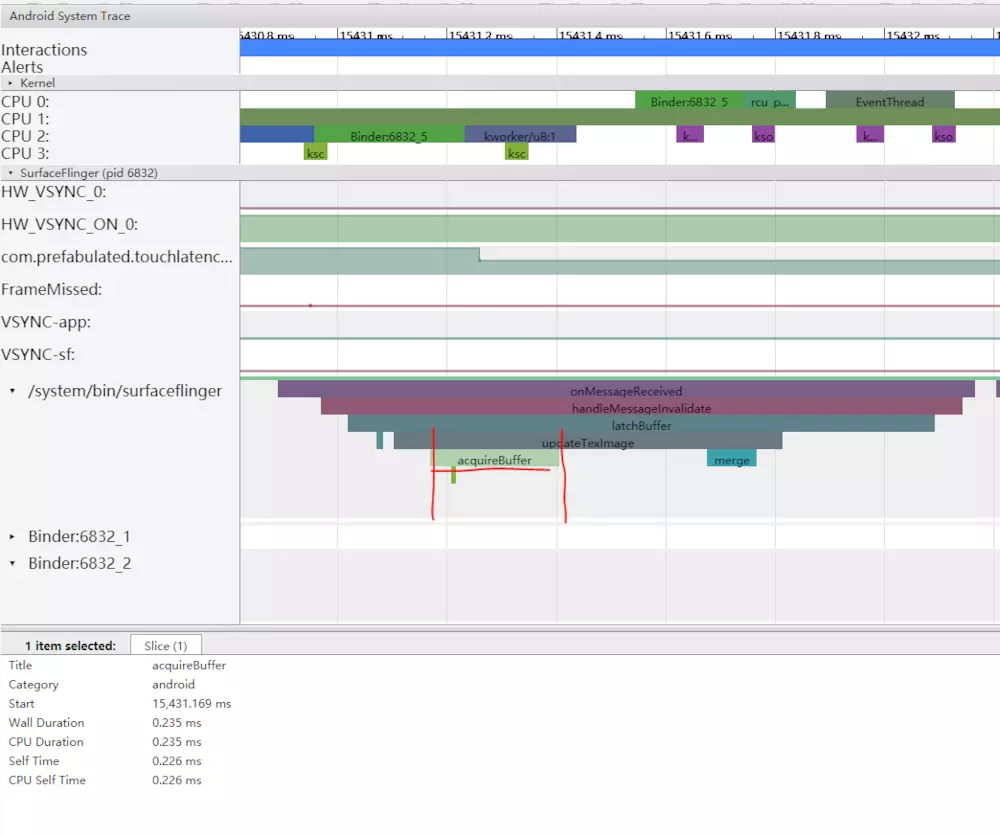
锁定缓冲区后,SurfaceFlinger进行组装并显示新帧。
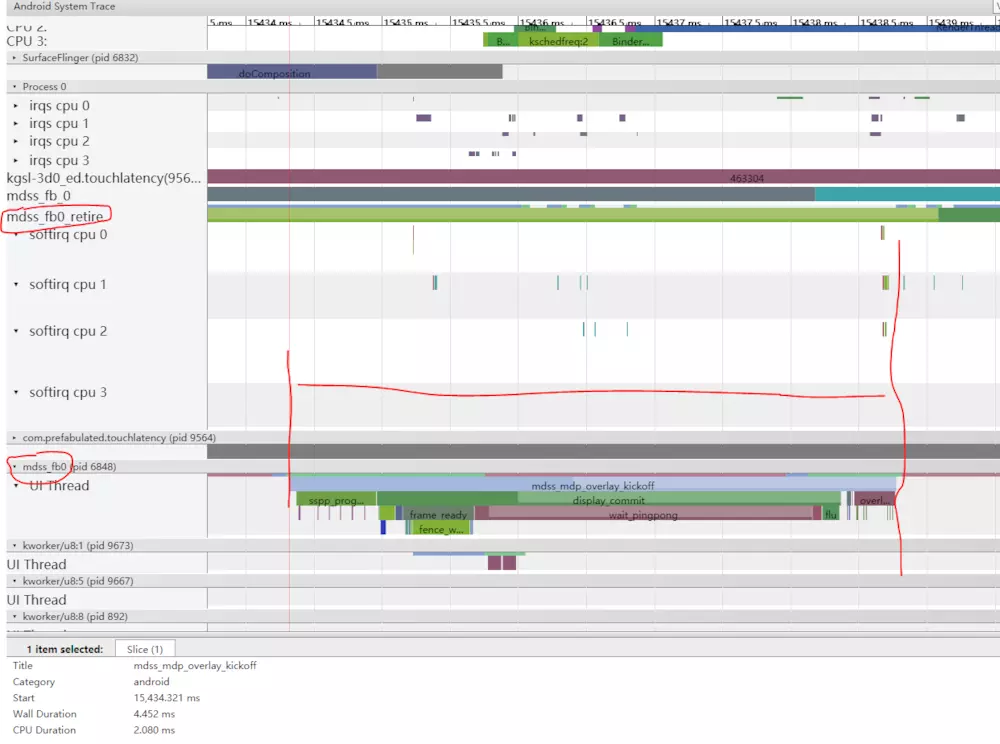
接下来,'mdss_fb0'在CPU 0上唤醒。'mdss_fb0'是显示管道的内核线程,用于将渲染的帧输出到显示器。 我们可以看到’mdss_fb0‘的信息(向下滚动查看)。
使用 Systrace
在介绍使用之前,先简单说明一下Systrace的原理:它的思想很朴素,在系统的一些关键链路(比如System Service,虚拟机,Binder驱动)插入一些信息(我这里称之为Label),通过Label的开始和结束来确定某个核心过程的执行时间,然后把这些Label信息收集起来得到系统关键路径的运行时间信息,进而得到整个系统的运行性能信息。Android Framework里面一些重要的模块都插入了Label信息(Java层的通过android.os.Trace类完成,native层通过ATrace宏完成),用户App中可以添加自定义的Label,这样就组成了一个完成的性能分析系统。
TraceView试图收集某个阶段所有函数的运行信息(sampling的也是基于此思路),它希望在你并不知道哪个函数有问题的时候直接定位到关键函数;但可惜的是,收集所有信息 这个是不现实的,它的运行时开销严重干扰了运行环境;一个人犯罪了,你要把全国人民都抓起来审问一遍吗?Systrace的思路是反过来的,在不清楚问题的情况下,你压根儿无法下手,只有掌握了一些基本的信息,通过假设-分析-验证 的过程一步一步找出问题的原因;TraceView那种一招吃遍天下鲜的方式,讲道理是不符合科学依据的(当然在特定的场合TraceView有他的用途)。
首先,在手机端准备好你需要分析的过程的环境;比如假设你要分析App的冷启动过程,那就先把App进程杀掉,切换到Launcher中有你的App 图标的那个页面,随时准备点击图标启动进程;假设你要分析某个Activity的卡顿情况,那就先在手机上进入到上一个Activity,随时准备点按钮切换到待分析的Activity中。
因为Systrace没办法自由滴控制开始和结束(下面有一个办法可以缓解),而trace得到的数据有可能非常多,因此我们需要手工缩小需要分析的数据集合;不然你可能被一堆眼花缭乱的数据和图像弄得晕头转向,然后什么有用的结论也分析不出来。记住哦,手动缩小范围,会帮助你加速收敛问题的分析过程,进而快速地定位和解决问题。
./systrace.py -t 10 sched gfx view wm am app webview -a <package-name>
这样,systrace.py 这个脚本就通过adb给手机发送了收集trace的通知;与此同时,切换到手机上进行你需要分析的操作,比如点击Launcher中App的Icon启动App,或者进入某个Activity开始滑动ListView/RecyclerView。经过你指定的时间之后(以上是10s),就会有trace数据生成在当前目录,默认是 trace.html;用Chrome浏览器打开即可。
如上文所述,systrace没有办法在代码中控制Trace运行的开始和结束;那么,如果我们要分析App的启动性能,我点了桌面图标,把Trace时间设置为10s,我怎么知道这10s中,哪段时间是我App的启动过程?如果不知道我们需要分析的时间段,那后续不是扯淡么?
我们可以用自定义Trace Label解决;Android SDK中提供了android.os.Trace#beginSection和android.os.Trace#endSection 这两个接口;我们可以在代码中插入这些代码来分析某个特定的过程;比如我们觉得Fragment的onCreateView过程有问题,那就在onCreateView 中加上代码:
public View onCreateView(LayoutInflater inflater, @Nullable ViewGroup container,
Bundle savedInstanceState) {
Trace.beginSection("Fragement_onCreateView");
// .. 其他代码
// ...
// .. 结束处
Trace.endSection();
}
这样,在Trace的分析结果中就会带上Fragement_onCreateView 这个过程的运行时间段信息(当然你得开启 -a 选项!),如下:
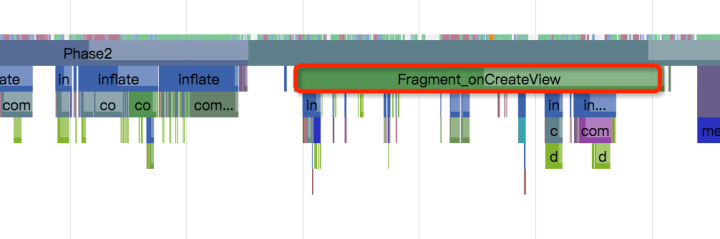
我们可以在任意自己感兴趣的地方添加自定义的Label;一般来说,分析过程就是,你怀疑哪里有问题,就在那那个函数加上Label,运行一遍抓一个Trace,看看自己的猜测对不对;如果猜测正确,进一步加Label缩小范围,定位到具体的自定义函数,函数最终调用到系统内部,那就开启系统相关模块的Trace,继续定位;如果猜测错误,那就转移目标,一步步缩小范围,直至问题收敛。
回到正题,我们如何控制Systace的开始和结束?事实上这是没法办到的,不过控制开始和结束的目的是什么?其实就是得到开始和结束这段时间内的Trace信息。要达到这个目的,我们只需要在期望开始和结束的地方加上自定义的Label就可以了。比如你要分析App的冷启动过程,那就在Application类的attachBaseContext调用Trace.beginSection("Boot Procedure"),然后在App首页的onWindowFocusChanged 或者你认为别的合适的启动结束点调用Trace.endSection就可以到启动过程的信息;比如下图是我的Label:
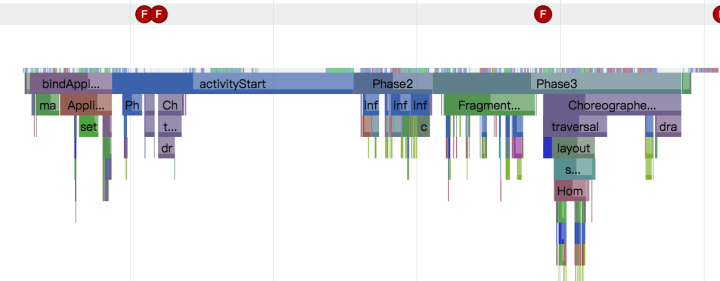
从bindApplication到activityStart,到Phase2,Phase3;这几个过程组合就是我感兴趣的启动过程。从图中可以直观地看出来,从Application到activityStart占用了启动一半的时间,activityStart下面那有一大段空白是在干什么?这是个问题。
systrace官方文档说待trace的App必须是debuggable的,但是官方又说,debuggable的App与非debuggable的性能有较大差别;因为系统为了支持debug开启了一些列功能并且关闭掉了某些重要的优化。
如果我们想要待分析的App尽可能接近真实情况,那么必须要在非Debug的App中能启用systrace功能;因为相同情况下Debug的App性能比非Debuggable的差,你无法确保在debuggable版本上分析出来的结论能准确推广到非debuggable的版本上。
分析systrace源码之后 ,发现这个条件只是个障眼法而已;我们可以手动开启App的自定义Label的Trace功能,方法也很简单,调用一个函数即可;但是这个函数是SDK @hide的,我们需要反射调用:
Class<?> trace = Class.forName("android.os.Trace");
Method setAppTracingAllowed = trace.getDeclaredMethod("setAppTracingAllowed", boolean.class);
setAppTracingAllowed.invoke(null, true);
把这段代码放在Application的attachBaseContext 中,这样就可以手动开启App自定义Label的Trace功能,在非debuggable的版本中也适用!
MAT 使用

内存优化





- UI 不可见时释放资源
- 在 onStop 中关闭网络连接、注销广播接收器、释放传感器等资源;
- 在 onTrimMemory() 回调方法中监听 TRIM_MEMORY_UI_HIDDEN 级别的信号,此时可在 Activity 中释放 UI 使用的资源,大符减少应用占用的内存,从而避免被系统清除出内存。
- 内存紧张时释放资源
运行中的程序,如果内存紧张,会在 onTrimMemory(int level) 回调方法中接收到以下级别的信号:
- TRIM_MEMORY_RUNNING_MODERATE:系统可用内存较低,正在杀掉 LRU 缓存中的进程。你的进程正在运行,没有被杀掉的危险。
- TRIM_MEMORY_RUNNING_LOW:系统可用内存更加紧张,程序虽然暂没有被杀死的危险,但是应该尽量释放一些资源,以提升系统的性能(这也会直接影响你程序的性能)。
- TRIM_MEMORY_RUNNING_CRITICAL:系统内存极度紧张,而 LRU 缓存中的大部分进程已被杀死,如果仍然无法获得足够的资源的话,接下来会清理掉 LRU 中的所有进程,并且开始杀死一些系统通常会保留的进程,比如后台运行的服务等。关于进程的优先级,参考这里(developer.android.com/guide/compo…
当程序未在运行,保留在 LRU 缓存中时, onTrimMemory(int level) 中会返回以下级别的信号:
- TRIM_MEMORY_BACKGROUND:系统可用内存低,而你的程序处在 LRU 的顶端,因此暂时不会被杀死,但是此时应释放一些程序再次打开时比较容易恢复的 UI 资源。
- TRIM_MEMORY_MODERATE:系统可用内存低,程序处于 LRU 的中部位置,如果内存状态得不到缓解,程序会有被杀死的可能。
- TRIM_MEMORY_COMPLETE:系统可用内存低,你的程序处于 LRU 尾部,如果系统仍然无法回收足够的内存资源,你的程序将首先被杀死。此时应释放无助于恢复程序状态的所有资源。
注:该 API 在版本 14 中加入。旧版本的 onLowMemory() 方法,大致相当于 onTrimMemory(int level) 中接收到 TRIM_MEMORY_COMPLETE 级别的信号。
另:尽管系统主要按照 LRU 中顺序来杀进程,不过系统也会考虑程序占用的内存多少,那些占用内存高的进程有更高的可能性会被首先杀死。
- 确定你的程序应该占用多少内存
可以通过 getMemoryClass()来获取你的程序被分配的可用内存,以 M 为单位。
你可以通过在 标签下将 largeHeap 属性设为 true 来要求更多的内存,这时通过 getLargeMemoryClass() 方法来获取可用内存。
大部分应用程序不需要使用此功能,因此使用该标签前,确认你的程序是否真的需要更多内存。使用更多内存会对整个系统的性能产生影响,而且当程序进入 LRU 时会更容易首先被系统清理掉。
- 正确使用 Bipmap,避免浪费内存
如果你的 ImageViwe 的尺寸只有 100 * 100,那么没有必要将一张 2560 * 1600 的图片整个加载入内存。关于如何加载图片,参考这里(developer.android.com/topic/perfo…)。
- 使用 Android 提供的优化过的数据结构
如 SparseArray, SparseBooleanArray, LongSparseArray 等,相比 Java 提供的 HashMap,这些结构更节省内存。
- 始终对内存使用情况保持关注
- 枚举类型 Enum 会比静态常量占用更多的内存;
- Java 中每个类(包括匿名内部类)都占用至少 500 字节左右的代码;
- 每个类的实例会在 RAM 中占用大约 12 ~ 16 字节的内存;
- 每向 HashMap 中添加一个 Entry 时,新生成的 Entry 占用大约 32 个字节。
