

我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种(mini-batch gradient descent和stochastic gradient descent),关于Batch gradient descent(批梯度下降,BGD)就不细说了(一次迭代训练所有样本),因为这个大家都很熟悉,通常接触梯队下降后用的都是这个。这里主要介绍Mini-batch gradient descent和stochastic gradient descent(SGD)以及对比下Batch gradient descent、mini-batch gradient descent和stochastic gradient descent的效果。
一、Batch gradient descent
Batch gradient descent 就是一次迭代训练所有样本,就这样不停的迭代。整个算法的框架可以表示为:
1X = data_input
2Y = labels
3parameters = initialize_parameters(layers_dims)
4for i in range(0, num_iterations): #num_iterations--迭代次数
5 # Forward propagation
6 a, caches = forward_propagation(X, parameters)
7 # Compute cost.
8 cost = compute_cost(a, Y)
9 # Backward propagation.
10 grads = backward_propagation(a, caches, parameters)
11 # Update parameters.
12 parameters = update_parameters(parameters, grads)
Batch gradient descent的优点是理想状态下经过足够多的迭代后可以达到全局最优。但是缺点也很明显,就是如果你的数据集非常的大(现在很常见),根本没法全部塞到内存(显存)里,所以BGD对于小样本还行,大数据集就没法娱乐了。而且因为每次迭代都要计算全部的样本,所以对于大数据量会非常的慢。
二、stochastic gradient descent
为了加快收敛速度,并且解决大数据量无法一次性塞入内存(显存)的问题,stochastic gradient descent(SGD)就被提出来了,SGD的思想是每次只训练一个样本去更新参数。具体的实现代码如下:
1X = data_input
2Y = labels
3permutation = list(np.random.permutation(m))
4shuffled_X = X[:, permutation]
5shuffled_Y = Y[:, permutation].reshape((1, m))
6for i in range(0, num_iterations):
7 for j in range(0, m): # 每次训练一个样本
8 # Forward propagation
9 AL,caches = forward_propagation(shuffled_X[:, j].reshape(-1,1), parameters)
10 # Compute cost
11 cost = compute_cost(AL, shuffled_Y[:, j].reshape(1,1))
12 # Backward propagation
13 grads = backward_propagation(AL, shuffled_Y[:,j].reshape(1,1), caches)
14 # Update parameters.
15 parameters = update_parameters(parameters, grads, learning_rate)
如果我们的数据集很大,比如几亿条数据,num_iterationsnum_iterations 基本上 设置1,2,(10以内的就足够了)就可以。但是SGD也有缺点,因为每次只用一个样本来更新参数,会导致不稳定性大些(可以看下图(图片来自ng deep learning 课),每次更新的方向,不想batch gradient descent那样每次都朝着最优点的方向逼近,会在最优点附近震荡)。因为每次训练的都是随机的一个样本,会导致导致梯度的方向不会像BGD那样朝着最优点。
注意:代码中的随机把数据打乱很重要,因为这个随机性相当于引入了“噪音”,正是因为这个噪音,使得SGD可能会避免陷入局部最优解中。
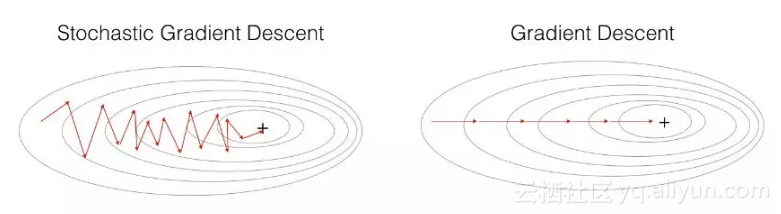
下面来对比下SGD和BGD的代价函数随着迭代次数的变化图:
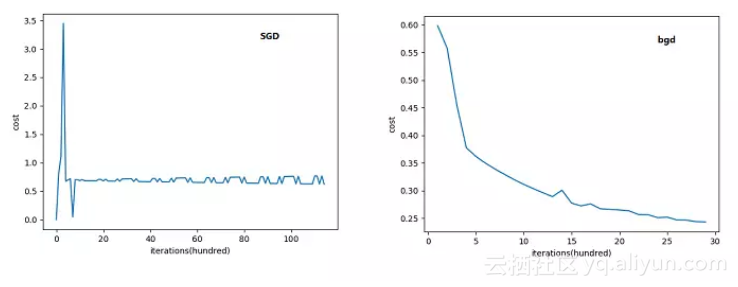
可以看到SGD的代价函数随着迭代次数是震荡式的下降的(因为每次用一个样本,有可能方向是背离最优点的)
三、Mini-batch gradient descent
mini-batch gradient descent 是batch gradient descent和stochastic gradient descent的折中方案,就是mini-batch gradient descent每次用一部分样本来更新参数,即 batch_size。因此,若batch_size=1 则变成了SGD,若batch_size=m 则变成了batch gradient
descent。batch_size通常设置为2的幂次方,通常设置2,4,8,16,32,64,128,256,512(很少设置大于512)。因为设置成2的幂次方,更有利于GPU加速。现在深度学习中,基本上都是用 mini-batch gradient descent,(在深度学习中,很多直接把mini-batch gradient descent(a.k.a stochastic mini-batch gradient descent)简称为SGD,所以当你看到深度学习中的SGD,一般指的就是mini-batch
gradient descent)。下面用几张图来展示下mini-batch gradient descent的原理(图片来自ng deep learning 课):
下面直接给出mini-batch gradient descent的代码实现: 1.首先要把训练集分成多个batch
1# GRADED FUNCTION: random_mini_batches
2def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
3 """
4 Creates a list of random minibatches from (X, Y)
5 Arguments:
6 X -- input data, of shape (input size, number of examples)
7 Y -- true "label" vector (1 for blue dot / 0 for red dot), of shape (1, number of examples)
8 mini_batch_size -- size of the mini-batches, integer
9
10 Returns:
11 mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
12 """
13 np.random.seed(seed) # To make your "random" minibatches the same as ours
14 m = X.shape[1] # number of training examples
15 mini_batches = []
16
17 # Step 1: Shuffle (X, Y)
18 permutation = list(np.random.permutation(m))
19 shuffled_X = X[:, permutation]
20 shuffled_Y = Y[:, permutation].reshape((1,m))
21
22 # Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
23 num_complete_minibatches = m//mini_batch_size # number of mini batches
24 for k in range(0, num_complete_minibatches):
25 mini_batch_X = shuffled_X[:, k * mini_batch_size: (k + 1) * mini_batch_size]
26 mini_batch_Y = shuffled_Y[:, k * mini_batch_size: (k + 1) * mini_batch_size]
27 mini_batch = (mini_batch_X, mini_batch_Y)
28 mini_batches.append(mini_batch)
29
30 # Handling the end case (last mini-batch < mini_batch_size)
31 if m % mini_batch_size != 0:
32 mini_batch_X = shuffled_X[:, num_complete_minibatches * mini_batch_size : m]
33 mini_batch_Y = shuffled_Y[:, num_complete_minibatches * mini_batch_size : m]
34 mini_batch = (mini_batch_X, mini_batch_Y)
35 mini_batches.append(mini_batch)
36
37 return mini_batches
2.下面是在model中使用mini-batch gradient descent 进行更新参数
1seed = 0
2for i in range(0, num_iterations):
3 # Define the random minibatches. We increment the seed to reshuffle differently the dataset after each epoch
4 seed = seed + 1
5 minibatches = random_mini_batches(X, Y, mini_batch_size, seed)
6 for minibatch in minibatches:
7 # Select a minibatch
8 (minibatch_X, minibatch_Y) = minibatch
9 # Forward propagation
10 AL, caches = forward_propagation(minibatch_X, parameters)
11 # Compute cost
12 cost = compute_cost(AL, minibatch_Y)
13 # Backward propagation
14 grads = backward_propagation(AL, minibatch_Y, caches)
15 parameters = update_parameters(parameters, grads, learning_rate)
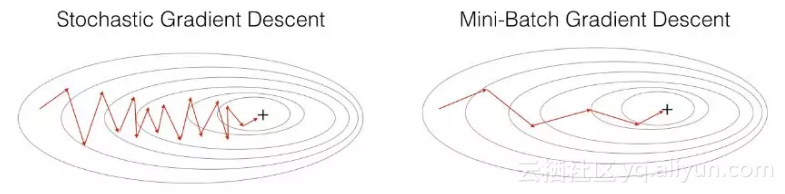
下面来看mini-batch gradient descent 和 stochastic gradient descent 在下降时的对比图:
下面是mini-batch gradient descent的代价函数随着迭代次数的变化图:
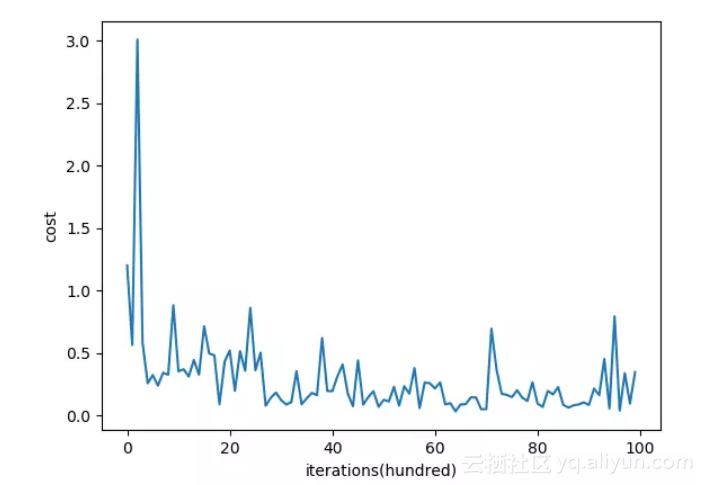
从图中能够看出,mini-batch gradient descent 相对SGD在下降的时候,相对平滑些(相对稳定),不像SGD那样震荡的比较厉害。mini-batch gradient descent的一个缺点是增加了一个超参数 batch_size ,要去调这个超参数。
以上就是关于batch gradient descent、mini-batch gradient descent 和 stochastic gradient descent的内容。
原文发布时间为:2018-09-12
本文来自云栖社区合作伙伴“机器学习算法与Python学习”,了解相关信息可以关注“ 机器学习算法与Python学习”。
