

线性回归
函数模型
线性回归函数想必大家在高中的学习中就已经学习过了,这一篇文章中我们并不会很详细的介绍。首先,如同下面这张散点图:
我们会怎么去用函数拟合?
我们一眼就会发现,用一条直线穿过数据会很好的拟合这些数据,这些数据很均匀的分布在直线的两侧。看到这里我们就可以直接写出我们线性函数的表达式了:
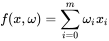
不过通常我们认为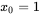 ,所以这个式子展开之后就是:
,所以这个式子展开之后就是:
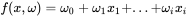
在机器学习中,我们常常使用线性代数去描绘数据,因此我们写成下面这种形式

也就是说,将表达式写成矩阵的形式,就成了:
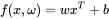
这只是最简单的一种线性函数,还有一些广泛应用于神经网络的线性函数是一层一层的嵌套函数,例如:
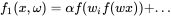
目前我们并不去讨论非线性的函数模型,对于非线性的函数模型,我们往往需要进行正则化进行调整,这里我会在后面进行详细的介绍。
代价函数
代价函数又称为损失函数,在这里我们可以试着来推导一下。我们的代价函数主要就是用于衡量预测数据和真实数据之间的误差。很容易的我们会想到直接用他们之间的差值作为衡量。
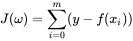
不过这个函数存在一个问题,就是
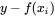 的符号是不确定的,因此即使误差很大,
的符号是不确定的,因此即使误差很大,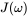 甚至可以为0,因此我们需要改进这个函数。
甚至可以为0,因此我们需要改进这个函数。
那么,加一个绝对值怎么样呢?
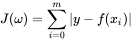
这样显然我们的代价函数有了更好的性能,不过还是存在一些问题,就是绝对值是无法求导的。那么我们会想,有什么方法既可以不影响函数的代数性质又不会造成误差的失误呢?很明显,二次函数是一个不错的想法。
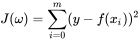
这个时候我们已经完成了我们的函数设计,不过还有一点点小问题,就是 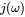 有可能出现过大的情况,我们需要对它进行求平均值,同时,为了方便我们后续的求导计算,我们通常还会乘以一个参数
有可能出现过大的情况,我们需要对它进行求平均值,同时,为了方便我们后续的求导计算,我们通常还会乘以一个参数 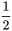 ,当然你不做处理也不会有问题。最终的函数解析式就成了:
,当然你不做处理也不会有问题。最终的函数解析式就成了:
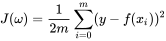
相信很多数学底子好一些的朋友,肯定发现了一件事,这不就是我们常常使用的方差的变形吗?是的,这个函数我们称为均方误差函数,你可以理解为广义上的方差,我们记得方差是减去数据的平均值,这里也是类似的,因为我们所用的拟合函数就已经充当了平均值的作用。
极大似然估计
这个玩意名字取得总是让人觉得怪怪的,一眼看不出这是干嘛的。极大似然估计有点类似文言文的一种说法,似然,也就是可能性的意思。极大似然估计也就是最大可能性的估计。
构造极大似然估计的条件很容易,也就是i.i.d条件,数据独立同分布条件。我们给出一个概率函数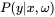 。如何评判函数的好坏呢?我们知道,对于给定的数据,概率达到最大值就是最好的,那么针对整个数据集来说,我们应当对概率函数进行求积:
。如何评判函数的好坏呢?我们知道,对于给定的数据,概率达到最大值就是最好的,那么针对整个数据集来说,我们应当对概率函数进行求积:
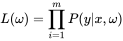
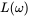 就是我们的似然函数了,而求出函数最大值所对应的
就是我们的似然函数了,而求出函数最大值所对应的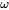 也就是我们所讨论的极大似然估计了。
也就是我们所讨论的极大似然估计了。
大部分情况下,我们不喜欢求连积,我们要想办法将变成一个求和的函数,这样我们的计算会方便许多。很容易想到对数的性质。我们对 进行求对数,得到:
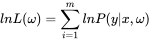
同样的我们防止数据过大,对它求一个平均值,不过这里的平均值应该是负平均值比较好,为什么?看一看对数函数的图像,概率是衡在[0,1]之间,对应的对数始终为负值,所以我们应该用负数好。
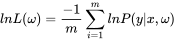
对数函数也有缺点,就是遇上0的时候,对数函数就显得无能为力了,在一些分类问题中,假设真实标记是0,那么极大似然估计出的概率函数也应该是0,或者是接近0,这样就会导致对它求对数的时候数值会变得巨大。这里我们引入一个概念——熵。我们将在下一节信息论中进行详细的介绍。
我的掘金:WarrenRyan
我的简书:WarrenRyan
欢迎关注我的博客获得第一时间更新 blog.tity.online
我的Github:StevenEco
