

一、环境
1、服务器
- CentOS Linux release 7.4.1708 (Core)
- CPU:4核
- 硬盘:80G
- ip:X.X.X.X
2、安装包
二、服务器相关配置
1、更改主机名(可选)
修改主机名主要为了方便管理。
# 输入查看主机名
hostname
# 输入修改主机名:
vim /etc/sysconfig/network
HOSTNAME=test1
注:主机名称更改之后,要重启(reboot)才会生效。
# 添加 主机IP 和对应的主机名称,做映射。
vim /etc/hosts

2、关闭防火墙
关闭防火墙,方便外部访问。
# CentOS 7版本以下输入:
service iptables stop
# CentOS 7 以上的版本输入:
systemctl stop firewalld.service
3、时间设置
# 查看当前时间
date
# 查看服务器时间是否一致,若不一致则更改
# 更改时间命令
date -s 'MMDDhhmmYYYY.ss'
三、Hadoop环境安装
1、下载安装
将下载下来的jdk、Hadoop安装包解压到home目录下,并新建文件夹java、hadoop
# 输入:
tar -xvf jdk-8u144-linux-x64.tar.gz -C /home/java
tar -xvf hadoop-2.8.2.tar.gz -C /home/hadoop
解压jdk和hadoop ,分别移动文件到java和hadoop文件下, 并将文件夹重命名为jdk1.8和hadoop2.8
2、JDK环境配置
# 首先查看是否已经安装,如果版本不合适,就卸载
java -version
3.2.1 profile 文件更改
# 编辑 /etc/profile 文件
vim /etc/profile
# 添加内容
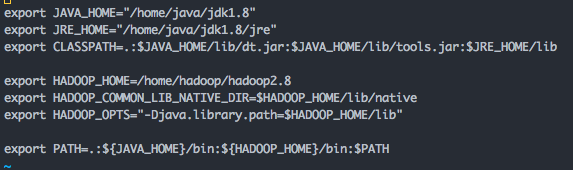
export JAVA_HOME=/home/java/jdk1.8
export JRE_HOME=/home/java/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
# :wq 保存退出后,使配置生效
source /etc/profile
3、Hadoop环境配置
3.3.1 编辑 /etc/profile 文件
vim /etc/profile
# 添加内容
export HADOOP_HOME=/home/hadoop/hadoop2.8
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
# 使配置生效
source /etc/profile
3.3.2 新建文件夹
在修改配置文件之前,先在root目录下建立一些文件夹。
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data
注:在root目录下新建文件夹是防止被莫名的删除。
3.3.3 修改core-site.xml
切换到 /home/hadoop/hadoop2.8/etc/hadoop/ 目录下
vim core-site.xml
# 在<configuration>节点内添加
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://test1:9000</value>
</property>
说明: test1 是主机名,可以替换为主机的ip。
3.3.4 修改 hadoop-env.sh
vim hadoop-env.sh
将${JAVA_HOME} 修改为自己的JDK路径
export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/home/java/jdk1.8
3.4.5 修改 hdfs-site.xml
vim hdfs-site.xml
# 在<configuration>节点内添加
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
说明:dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true。
3.4.6 修改mapred-site.xml
如果没有 mapred-site.xml 该文件,就复制mapred-site.xml.template文件并重命名为mapred-site.xml。 输入:
vim mapred-site.xml
修改这个新建的mapred-site.xml文件,在节点内加入配置:
<property>
<name>mapred.job.tracker</name>
<value>test1:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
四、启动Hadoop
第一次启动Hadoop需要初始化
hadoop namenode -format
初始化成功后,可以在/root/hadoop/dfs/name 目录下(该路径在hdfs-site.xml文件中进行了相应配置,并新建了该文件夹)新增了一个current 目录以及一些文件。
启动Hadoop 主要是启动HDFS和YARN
切换到/home/hadoop/hadoop2.8/sbin目录
启动HDFS
start-dfs.sh
登录会询问是否连接,输入yes ,然后输入密码就可以了
启动YARN
start-yarn.sh
可以输入 jps 查看是否成功启动
启动成功后,可以在浏览器输入以下地址查看
http://X.X.X.X:8088/cluster 查看任务状况
http://X.X.X.X:50070 查看HDFS集群状况
五、遇到的错误及解决方案
1、HDFS格式化后启动dfs出现以下错误:
[root@master sbin] ./start-dfs.sh
Starting namenodes on [master]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [slave1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
解决方案
在/hadoop/sbin路径下
将 start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
将 start-yarn.sh,stop-yarn.sh顶部添加以下
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
修改后重启 ./start-dfs.sh
2、Hadoop出现错误:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
其中有个warn信息,在这个信息附近找到一个:Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError,这表明是java.library.path出了问题,
解决方案是在文件hadoop-env.sh中增加:
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
3、hadoop无法访问50070端口
hdfs-site.xml 添加如下内容,然后重新格式化namenode,启动hadoop。最终访问正常
<property>
<name>dfs.http.address</name>
<value>test1:50070</value>
</property>
4、DataNode无法启动
以下提供两种解决办法:
- 方式1
删除前先关闭进程
[hadoop@zydatahadoop001 sbin]$ jps
26884 Jps
26043 SecondaryNameNode
25756 NameNode
[hadoop@zydatahadoop001 sbin]$ kill -9 26043
[hadoop@zydatahadoop001 sbin]$ kill -9 25756
删除 /tmp/hadoop-hadoop/dfs/data/data目录下的文件
[hadoop@zydatahadoop001 ~]$ cd /tmp/hadoop-hadoop/dfs/data/
[hadoop@zydatahadoop001 data]$ ll
total 8
drwxrwxr-x. 3 hadoop hadoop 4096 Dec 19 00:33 current
-rw-rw-r--. 1 hadoop hadoop 21 Dec 19 00:33 in_use.lock
[hadoop@zydatahadoop001 data]$ rm -rf current
这时候在进行格式化
[hadoop@zydatahadoop001 bin]$ hdfs namenode -format
问题就解决了。
- 方式2
修改current目录的VERSION中的clusterID使两个的clusterID相同,就可以解决了(/tmp/hadoop-hadoop/dfs/data/)
[hadoop@zydatahadoop001 ~]$ cd /tmp/hadoop-hadoop/dfs/data/
[hadoop@zydatahadoop001 data]$ ll
total 8
drwxrwxr-x. 3 hadoop hadoop 4096 Dec 19 00:33 current
-rw-rw-r--. 1 hadoop hadoop 21 Dec 19 00:33 in_use.lock
[hadoop@zydatahadoop001 current]$ cat VERSION
#Tue Dec 19 00:33:48 CST 2017
storageID=DS-d9b740ba-fe83-44ec-b3d2-e21da706a597
clusterID=CID-2544b3e3-8400-47a6-a253-63dffc356e47
cTime=0
datanodeUuid=79d78c7d-cd1b-4854-89df-c063ce5fba86
storageType=DATA_NODE
layoutVersion=-57
这时候在进行格式化
[hadoop@zydatahadoop001 bin]$ hdfs namenode -format
格式化之后jps查看datanode启动。问题就解决了。
五、启动dfs时报错 Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
# 首先确认是否已经有ssh-keygen,如果没有执行下面命令生成秘钥
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权
chmod 600 ./authorized_keys # 修改文件权限
然后在启动dfs就可以了
文章主要摘自: blog.csdn.net/qazwsxpcm
