

node
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。 Node.js 使用了一个事件驱动、非阻塞式 I/O 的模型,使其轻量又高效。 Node.js 的包管理器 npm,是全球最大的开源库生态系统。
阻塞I/O
程序执行过程中必然要进行很多I/O操作,读写文件、输入输出、请求响应等等。I/O操作时最费时的,至少相对于代码来说,在传统的编程模式中,举个例子,你要读一个文件,整个线程都暂停下来,等待文件读完后继续执行。换言之,I/O操作阻塞了代码的执行,极大地降低了程序的效率。
非阻塞I/O
理解了阻塞I/O,非阻塞I/O就好理解。非阻塞I/O是程序执行过程中,I/O操作不会阻塞程序的执行,也就是在I/O操作的同时,继续执行其他代码(这得益于Node的事件循环机制)。在I/O设备效率还远远低于CPU效率的时代,这种I/O模型(非阻塞I/O)为程序带来的性能上的提高是非常可观的。
Node.js事件轮询机制 event loop
下面我们写一个静态服务,从中可以了解到node常用的api和http方便的知识
目录结构
server
├─server.js //node 服务
├─config.js //host,port跟路径配置
├─tpl.ejs //渲染模版
正式搭建服务
// config.js
let path = require('path')
module.exports = {
host: 'localhost',
port: 8081,
root: path.join(__dirname, '..') // 配置我们要的根目录
}
配置模版
// tpl.ejs
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title><%= title %></title>
</head>
<body>
<% if (files.length) { %>
<ul>
<% files.forEach(function(file){ %>
<li><a href="<%= file.url %>"><%= file.name %></a></li>
<% }) %>
</ul>
<% } %>
</body>
</html>
在server中遍历文件目录使files中增加name和url传递到ejs模版中来渲染页面
// server.js
let config = require('./config')
let fs = require('fs')
let path = require('path')
let http = require('http')
let chalk = require('chalk')
class Server {
constructor() {
this.config = Object.assign({}, config)
this.tpl = fs.readFileSync(path.resolve(__dirname,'.', 'tpl.ejs'),'utf8');
}
start() {
console.log(this.tpl)
let server = http.createServer()
server.listen(this.config.port, () => {
let url = `${this.config.host}:${this.config.port}`
console.log(`server start at ${chalk.green(url)}`)
})
}
}
let server = new Server
server.start()
构建一个server服务在start中查看否获取到模版
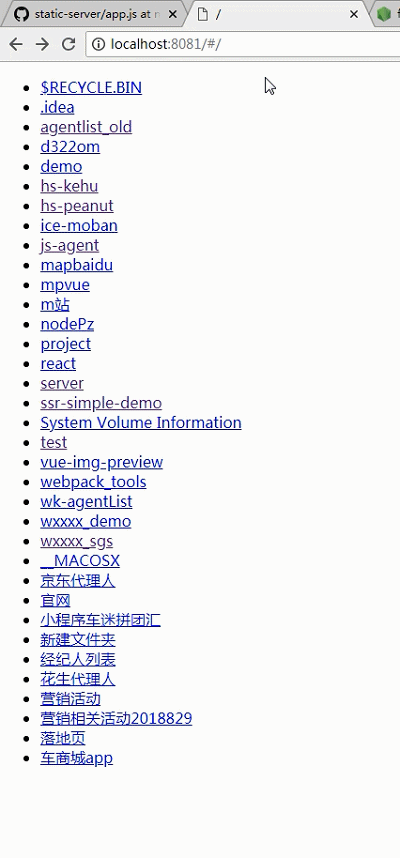
目前服务启动在localhost:8081上访问的是config.root下的所有文件,这是浏览器发起一个请求后,需要把相应的内容渲染到浏览器上。通过res.end(html)返回一个通过ejs模版渲染后的页面,返回给客户端。
start() {
..//
server.on('request', this.request.bind(this))
}
async request(req,res) {
try {
let {pathname} = url.parse(req.url, true)
let p = path.join(this.config.root, pathname)
let statObj = await stat(p);
if(statObj.isDirectory()) { // 如果当前一个目录
let files = await readdir(p)
files = files.map(file => ({
name: file,
url: path.join(pathname, file)
}))
let tpl = this.tpl
let html = ejs.render(tpl, {
title:pathname,
files
})
res.setHeader('Content-type', 'text/html;charset=utf8')
res.end(html)
} else { // 如果是文件
}
}catch(e) {
}
}
Server中创建一个getStream用来读取文件
先说说断点续传:
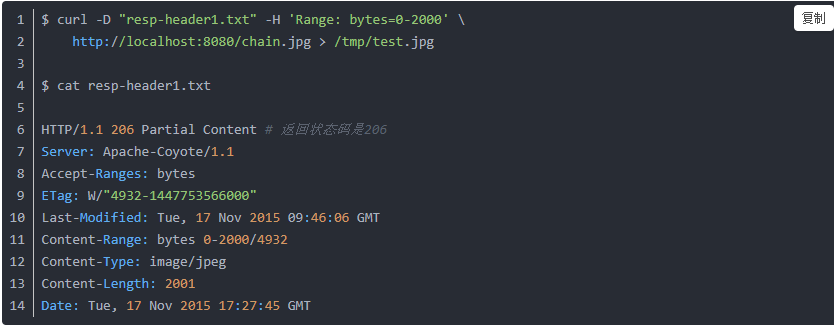
getStream(req, res, filepath, statObj) {
let start = 0;
let end = statObj.size - 1;
let range = req.headers['range'];
if (range) {
res.setHeader('Accept-Range', 'bytes');
res.statusCode = 206;//返回整个内容的一块
let result = range.match(/bytes=(\d*)-(\d*)/);
if (result) {
start = isNaN(result[1]) ? start : parseInt(result[1]);
end = isNaN(result[2]) ? end : parseInt(result[2]) - 1;
}
}
return fs.createReadStream(filepath, {
start, end
});
}
说说处理压缩
浏览器请求头中,都会携带自己的压缩类型,最常用的两种是gzip和deflate,服务端可以根据Accept-Ecoding头来返回响应的压缩资源 具体实现代码:
getEncoding(req, res) {
let acceptEncoding = req.headers['accept-encoding'];
if (/\bgzip\b/.test(acceptEncoding)) {
res.setHeader('Content-Encoding', 'gzip');
return zlib.createGzip();
} else if (/\bdeflate\b/.test(acceptEncoding)) {
res.setHeader('Content-Encoding', 'deflate');
return zlib.createDeflate();
} else {
return null;
}
}
在getStream中返回一个可读流,通过pipe返回给源源不断的把读到数据写入浏览器。
说说处理缓存
1.对比缓存
Last-Modified
- 当浏览器第一次请求服务器时,服务器会把缓存标识(Last-Modified)和数据一起返回客户端,再次请求时,服务器根据浏览器请求信息(if-modified-since)判断是否命中缓存,如果命中返回304状态码。
1 .但是如果文件修改比较频繁,如果一秒内修改多次那么,Last-Modified是没法准确判断了,因为他只能精确到秒。 2 . 如果文件的修改的时间变了,但是内容未改变,我们也不希望客户端认为文件修改了 。 3 .如果同样的一个文件位于多个CDN服务器上的时候内容虽然一样,修改时间不一样。
ETag
- 当浏览器二次请求的时候,服务器取出请求标识(if-none-match),并根据实体内容生成一段哈希字符串,标识资源状态。当资源未改变命中缓存,反之不执行缓存。
2.强制缓存
Cache-Control 和 Expires 强制缓存的好处是浏览器不需要发送HTTP请求,一般不常更改的页面都会设置一个较长的强制缓存。 Cache-Control与Expires的作用一致,都是指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据还是重新发请求到服务器取数据,如果同时设置的话,其优先级高于Expires。但Expires是HTTP1.0的内容,现在浏览器均默认使用HTTP1.1,所以基本可以忽略 。 Cache-Control 有几个参数
- private 客户端可以缓存
- public 客户端和代理服务器都可以缓存
- max-age=60 缓存内容将在60秒之后生效
- no-cache 需要使用对比缓存验证数据,强制向服务器再次发送
- no-store 所有内容都不会缓存,强制缓存和对比缓存都不会触发
handleCache(req,res,filepath,statObj){
let isNoneMatch = req.headers['is-none-match'];
res.setHeader('Expires',new Date(Date.now() + 30 *1000).toGMTString());
let etag = statObj.size;
let ifModifiedSince = req.headers['if-modified-since'];
let lastModified = statObj.ctime.toGMTString();
res.setHeader('ETag',etag);
res.setHeader('Last-Modified',lastModified);
//如果任何一个对比缓存头不匹配,则不走缓存
if(isNoneMatch && isNoneMatch !== etag){
return false
}
if(lastModified && lastModified !==ifModifiedSince){
return false
}
if (isNoneMatch || ifModifiedSince) {
res.writeHead(304);
res.end();
return true;
} else {
return false;
}
}
