

前言
上次给大家带来的卫视收视率的实时分析,反响还不错。而此次我们的主题是:"中国好诗人",这次小编会与大家聊聊在中国历史中留下浓墨重彩的古代文人们,究竟谁的作品最受欢迎,谁的人气最高,谁又最高产。本文将用当前流行的选秀节目形式在轻松的氛围中回答这些问题,并与大家分享一些爬虫和统计的知识。
本次案例相关包

1.海选
首先评判一个文人的标准就是它的作品的受欢迎度以及它的作品数量,所以此次我们采集了唐诗、宋词各10000首,明曲1450篇,文言文600篇对做为我们的原始数据,数据的采集网站为"https://www.gushiwen.org"
数据采集下来后,由于该网站数据有重复出现,所以我们需要对数据进行去重。去重完成后,我们就需要对所采集的数据进行合并处理,因为我们此次评选的是”中国好诗人“,所以首先的要求就是全能,多产。于是我们将只有一篇作品的文人给去除掉。诗词曲文的数据合并后,我们就需要将每篇文人作品的点赞数和产量进行求和。从而筛选出前100名作为海选的晋级对象。
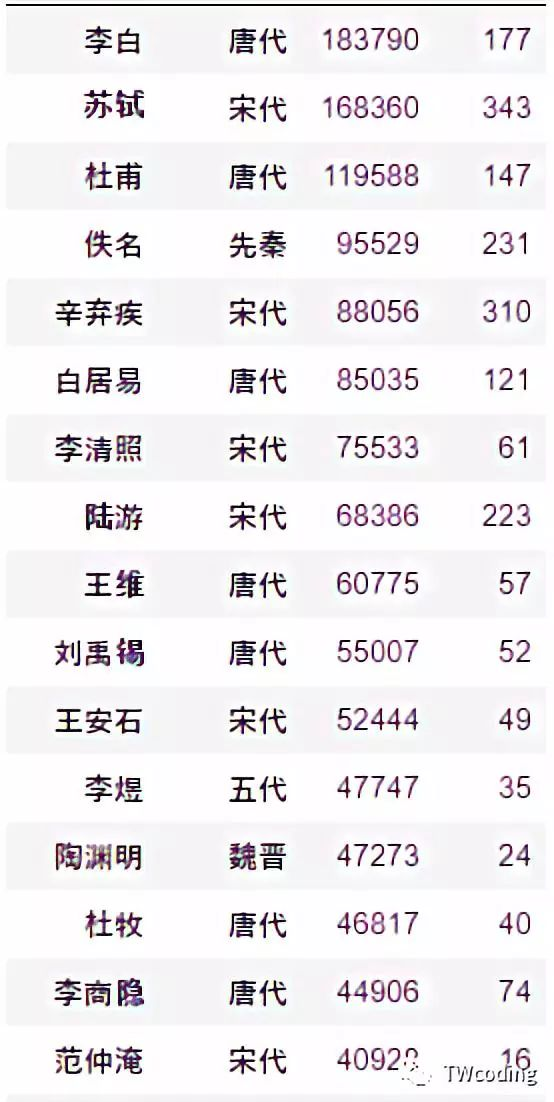
我们可以从图中看出由于不少诗歌不知出处,所以就打上了”佚名“的标签,所以在此我们还需要对数据进行处理,从而剔除掉这一类的诗歌。最后我们我们将前100位的作者的作品数量和作品总点赞数分别作为x,y轴绘制散点图。
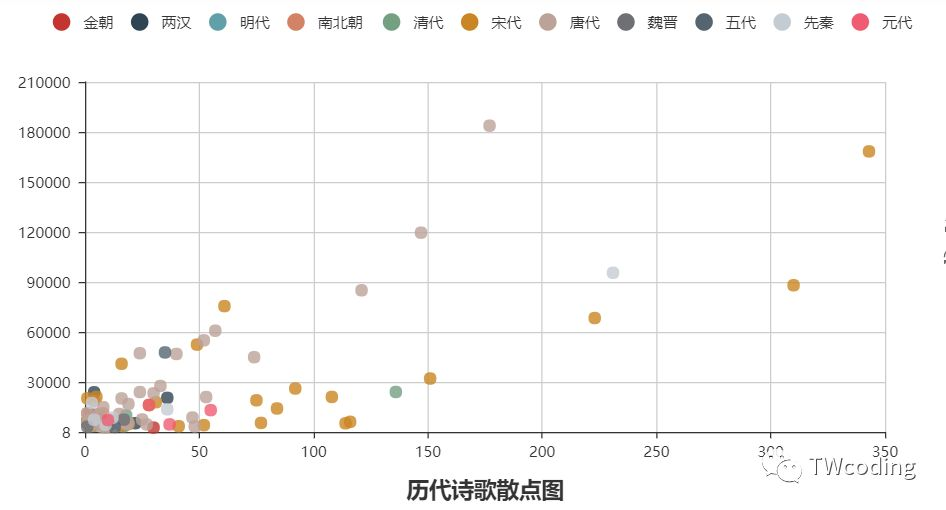
我们发现原始数据集中在左下角,为了提高可读性,我们将横纵坐标分别log处理。
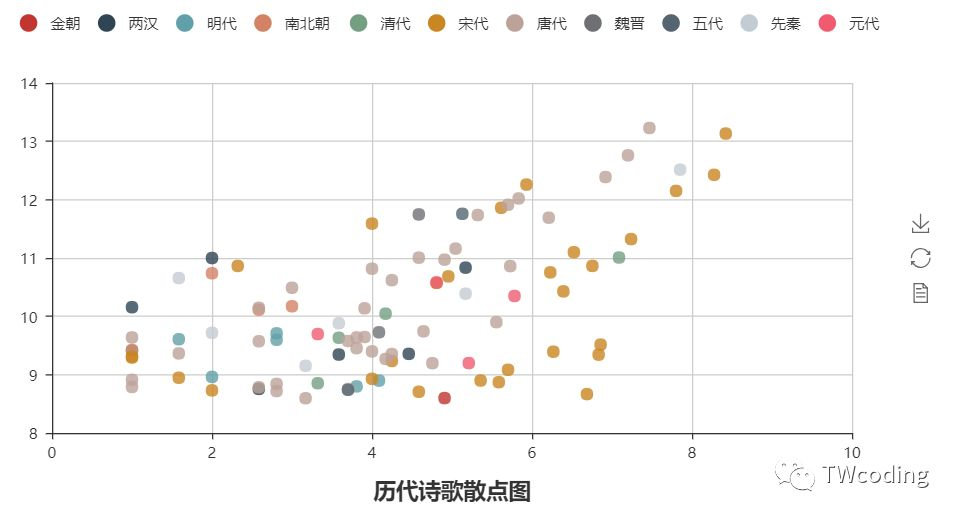
从图中我们可以大体看出晋级的文人所属的朝代分布,但是想要仔细的对比,对于我们来说还是有些难度,于是我们将各朝各代的诗歌数量和点赞量进行对比。
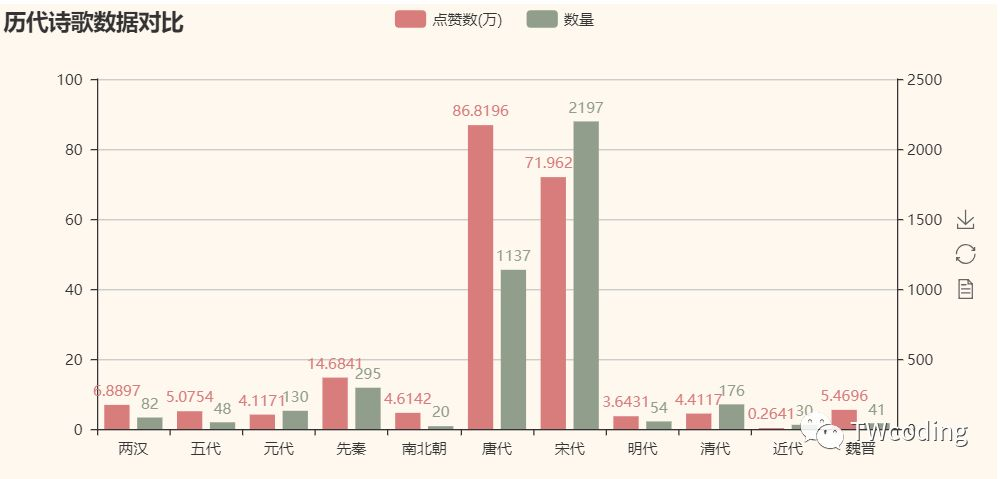
既然已经筛选出了前100名的文人们,那么我们的海选也已经完成,接下来我们进入复赛。
2.复赛
有了好的作品和一定的产量,那么我们也需要文人们有较高的人气才能从才子如云的群体中杀出重围,所以我们选取百度百科中读者们对文人们的打分来做为我们衡量文人们人气的标准。这同时也是文人们晋级决赛的标准。

我们分别采取了文人们在百度百科中的点赞数和转发数,并将他们相加作为人气值,从而筛选出人气值前50的文人进入决赛。
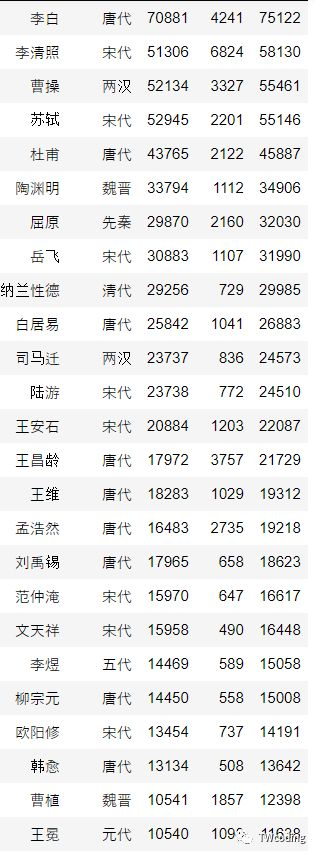
我们再来看一下50大诗人的具体朝代分布
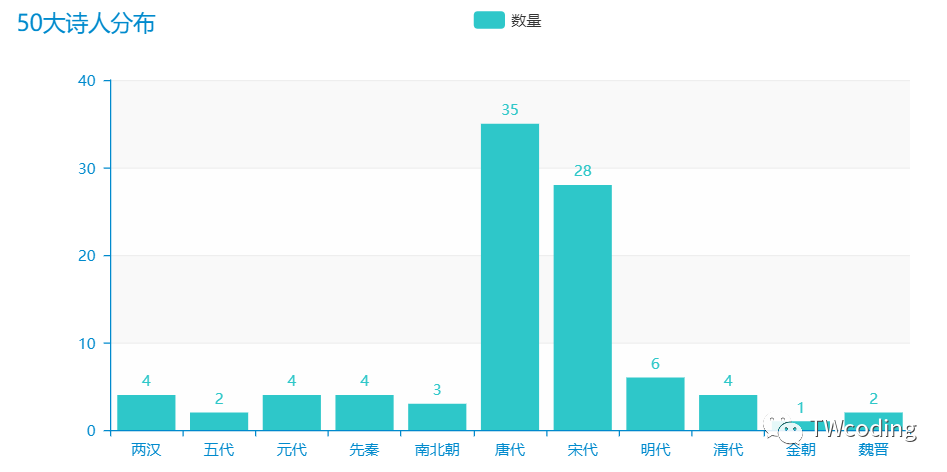
最后已经有50个文人晋级了决赛,那么我们就来看看他们在决赛当中如何厮杀吧。
3.决赛
经过了前两轮的筛选,我们的选手可谓都是万中挑一了,不过这还不够,可谓一山不容二虎,我们的文人墨客们也需分出胜负。在此我们我们以第一轮的文人获赞数和产量,第二轮的人气值,来综合作为我们最后的评判标准。由于是入门案例,需要照顾大部分读者,所以在此我们就不展示使用PCA(主成分分析)来对我们的最终数据进行中心化求得总分,小编在这里按权重占比来计算最后的得分,即最终得分=获赞数*0.3+产量*0.3+人气值*0.4,最后我们给出这次大赛的完整排名。
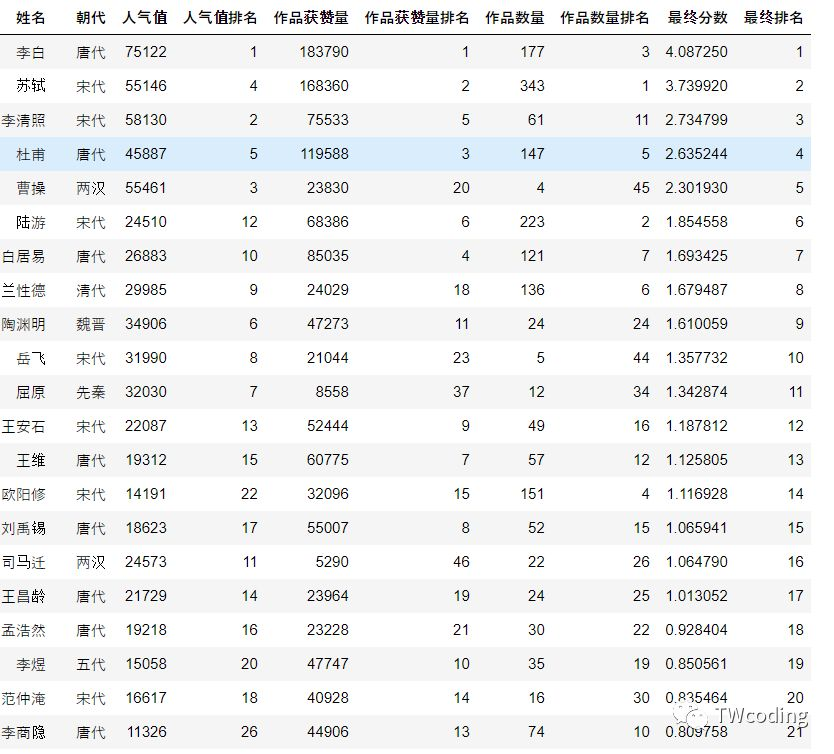
从表中我们可以看出唐代大诗人李白由人气值排名第1,作品获赞数第1,作品量第3获得了我们这次大赛的第1名,其次分别是宋代大文豪苏轼和女中豪杰李清照夺得2、3名。而且从表中还可看出最后的前50榜单,唐朝诗人占据着很大的比例,这也与唐朝是诗歌的黄金时代一美名相对应。最后我们言归正传,此次的”中国好诗人“的TOP3分别为李白、苏轼、李清照。排名4-10位的分别是:杜甫、曹操、陆游、白居易、纳兰性德、陶渊明、岳飞。我们在此向他们送去衷心的祝福。
需要源码和PCA(主成分分析)代码的读者可以后台给小编留言,小编看到就会第一时间回复你。
对爬虫,数据分析,算法感兴趣的朋友们,可以加微信公众号 TWcoding,我们一起玩转Python。
If it works for you.Please,star.
自助者,天助之

