

周一有幸参加了大搜车的前端面试,虽说因为手写算法不过关连面试官的脸都没见着,不过事后和舍友讨论其中一道关于字符串查找的算法题时却发现它并没有自己当时想的那么简单。
题
// 只使用最基本的便利来实现判断字符串a是否被包含在字符串b中,
// 并且返回第一次出现的位置(找不到返回-1),算法效率尽量高,
// 不要使用indexOf、正则、substring、contain、slice等现成的方法
// 例如 a = '34';b = '1234567'; 返回2
// balabala...
当我拿到题的时候是这么想的

出题的怕不是石乐志吧,好好的有原生提供的方法为啥要自己造轮子啊。。。不过想了想小学的时候老是碰到的那个一边开水龙头倒水,一边又拔了塞子放水的游泳池管理员,Emmmm...还是试着写一下吧。
该题有以下几个条件:
- 要实现的函数有两个参数,子串a与主串b
- 要实现的功能,如果a存在于b中则返回a在b中第一次出现的位置,如果a不存在于b中则返回-1
- 不可使用js提供的现成api,只能用简单遍历来实现
- 手写实现,效率尽可能高
这些条件忽略掉第四点,其实就是要求你以遍历的方式实现一个类似indexOf的功能。好,思路有了,那可以撸袖子干了。
初步的实现思路
按照一般的习惯的话,在我们拿到两个字符串的时候,比方说例子里面的‘34’ 与 ‘1234567’,我们会先把‘34’的首位3拿出来与1234567逐个进行对比,直到在1234567中找到了3,我们才会进行下一步骤把‘34’里3后面的4拿出来与‘1234567’里3之后的数字进行对比,如果值相同,则会继续刚才的步骤把在‘34’里4后面的值(当然在这个例子中对比到4就可以了)拿出来继续与‘1234567’进行比较,直到把‘34’里所有的值都对比完就结束对比,并把‘1234567’里面3的位置数出来就可以了,就像下面的草图一样:
// 对1234567与34进行比较,接下来以b表示1234567,a表示34
step1: a[0]为3,b[0]为1,不相等,则a往后移动一位
1 2 3 4 5 6 7 -变化为-> 1 2 3 4 5 6 7
3 4 3 4
step2: a[0]为3,b[1]为2,不相等,则a往后移动一位
1 2 3 4 5 6 7 -变化为-> 1 2 3 4 5 6 7
3 4 3 4
step3: a[0]为3,b[2]为3,相等,则比较a[1]与b[3];
a[1]为4,b[3]为4相等,且a[1]为a内最后一位,停止比较并返回b[3]的下标以表示第一次查询到的位置
下面用代码实现了字符串查找的的主要功能的逻辑,当然还得添加一些简单的判断,一些直观的字符串的比较就没有必要放到双层for循环里面去遍历了。
// '34'作为子串,我们把它视为变量a
// '1234567'作为主串,我们把它视为变量b
for (i=0;i<b.length;i++) {
if (b[i] == a[0]) {
for (j=1; j<a.length; j++) {
if (a[j] != b[j + i]) {
break //跳出内部的for循环
} else {
continue //继续内部的for循环,直到a遍历完或者出现a[j] != b[j + i]的情况发生
}
}
}
}
当然笔试的时候遇到的最大的困难便是没办法把想法实现出来,毕竟时间有限而且还是手写,一紧张就会被多层嵌套的for循环绕晕。。。我是谁,我在哪,我要干嘛,这些问题都会从脑海里蹦出来,然后就放弃思考,听隔壁面试java的和另一个面试官聊设计模式(java的不用笔试???)、面产品还是测试的小姑娘和面试官讲自己在别的公司里实习时干过的事(大概应届生)。。。啊,跑题了,下面放上我之后实现的代码和按着笔试时的想法画出来的流程图,这些比上面讲的更直观。
code
function isContain(a, b) {
var aItem = a[0];
var aLength = a.length;
var bLength = b.length;
if (bLength == aLength) {
return b == a ? 0 : -1
}
if (bLength < aLength) {
return -1
}
for (let i = 0; i < bLength; i++) {
if (b[i] == aItem) {
let j;
for (j = 1; j < aLength; j++) {
if (b[j+i] != a[j]) {
break
} else {
continue
}
}
if (j == aLength) return i
}
}
return -1
}
流程图
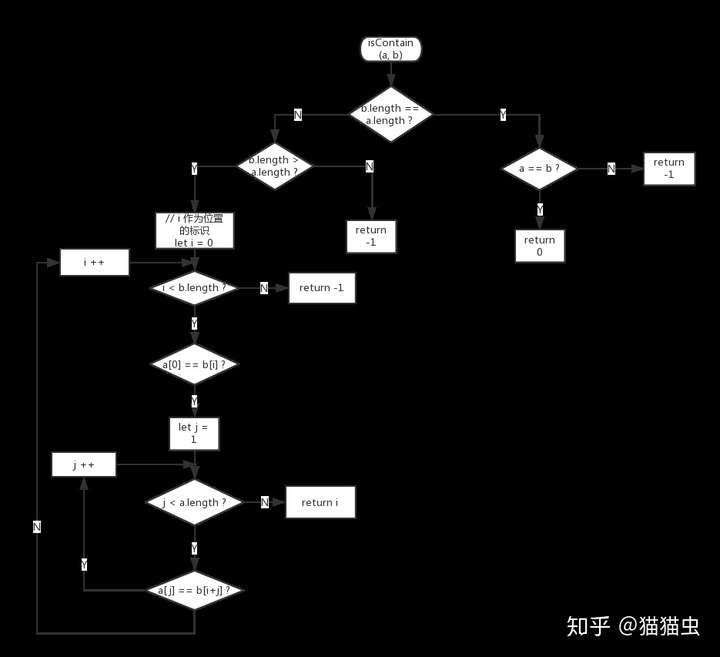
是否有优化空间?有,kmp了解一下?
上面的实现是按着一般思维来实现的,但考虑到出去面试处处小心的原则,肯定有坑!毕竟题目里都写了算法效率尽可能高,那比O(m * n)更快的算法肯定是存在的(应试教育所培养的直觉(´・Д・)」),后面和舍友聊天的时候了解到还存在一个kmp的算法,能把时间复杂度变成O(m + n),Ummmm....总之kmp更高效就是了。
下面对于kmp的介绍主要是基于以下两篇文章的归纳与补充,补充部分为如何推导出kmp算法内所用到的Partial Match Table(部分匹配表)。
[字符串匹配的KMP算法)]( 字符串匹配的KMP算法 - 阮一峰的网络日志)
[The Knuth-Morris-Pratt Algorithm in my own words](The Knuth-Morris-Pratt Algorithm in my own words)
接下来将围绕以下几点讲解kmp:
- 什么是proper prefixes(前缀)与proper suffixes(后缀)
- 什么是PMT与其计算方式
- 使用PMT实现kmp算法
proper prefixes & proper suffixes
这里直接套用阮老师的说法来描述前缀与后缀
"前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合
// 假定有一字符串b的值为'ABCDEFG'
// 对于该字符串来说,其前缀(左)与后缀(右)
A G
AB FG
ABC EFG
ABCD DEFG
ABCDE CDEFG
ABCDEF BCDEFG
(`_´)ゞ讲完了,是的就这么简单,是不是有一种被那看起来牛逼哄哄的洋文骗到了?
PMT(部分匹配表)
部分匹配表由部分匹配值构成,部分匹配值为"前缀"和"后缀"的最长的共有元素的长度。还是以"ABCDABD"为例。
- "A"的前缀和后缀都为空集,共有元素为空,其最长共有元素长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素为空,其最长共有元素长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素为空,其最长共有元素长度为0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素为空,其最长共有元素长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",其长度为1,则最长共有元素长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",其长度为1,则其最长共有元素长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0
(`_´)ゞ好,这里又照搬照抄了阮老师的,把上面的值汇总一下得到下面的表。

上面计算字符串的部分匹配表的方式需要把所有搜索词的前缀后缀都写出来,然后再查重,再找出重复元素中最长的字符串数出它的长度才能知道其部分匹配值,想象一下你要把这一步骤用代码实现出来。。。

不过对于求部分匹配表还是有简单的实现的,接下来是全文重点!如何根据传入的字符串,得出其部分匹配表!
当然我们还是以"ABCDABD"为例
step1

step2

step3

step4

step5

step6

step7

看上去有点绕呼呼的,不过多看几次就能搞明白,直接贴上自己写的代码给诸位做参考
function pmt(str) {
var arr = [0];
var i = 0;
var length = str.length;
for (let j = 1; j < length; j++) {
while (i > 0 && str[j] != str[i]) {
i = arr[i - 1];
}
if (str[j] == str[i]) {
i = i + 1;
}
arr[j] = i;
}
return arr
}
拿到pmt之后,实现算法就好说了。
结合PMT实现kmp算法
经过上面的解析,我们已经可以得到传入的字符串的PMT,接下来我们来看看kmp内是如何通过使用PMT内的数据实现字符串搜索的简化,这里以在"BBC ABCDAB ABCDABCDABDE"内查询"ABCDABD"为例:
复制一份PMT


接下来直接上代码实现,上面的没看懂建议看下阮大师的图例介绍
function isContain(a, b) {
let aLength = a.length;
let bLength = b.length;
if (bLength == aLength) {
return b == a ? 0 : -1
}
if (bLength < aLength) {
return -1
}
let table = pmt(a);
let num = function (index) {
return index - table[index - 1]
}
let result;
let moveNum;
for (let i = 0, k = 0; k < bLength;) {
result = k;
while (a[i] == b[k]) {
if (i + 1 == aLength) return result
i++;
k++;
}
if (i == 0) {
moveNum = 1;
} else {
moveNum = num(i);
}
k = result + moveNum;
i = 0;
if (k >= bLength) return -1
}
}
参考文档
[字符串匹配的KMP算法)]( 字符串匹配的KMP算法 - 阮一峰的网络日志)
[The Knuth-Morris-Pratt Algorithm in my own words](The Knuth-Morris-Pratt Algorithm in my own words)
[bilibili (゜-゜)つロ 干杯]( 【soso字幕】汪都能听懂的KMP字符串匹配算法【双语字幕】_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili)
结尾吐槽
学算法短期收益不高,但确实是一类必备的技能,这些东西如果生活状态稳定的话,每天学一点当作脑筋急转弯放松放松还是蛮好的,对于招别人去应聘工作什么的,最好还是来一轮电话面,如果不合适也不需要安排面试了,毕竟每个人的时间都很值钱,而且都已经约了面试了,那至少面试官也露个面呀,大老远跑去面试结果填张表,写个题就赶人回去......

祝各位找工作的朋友能早日找到自己喜欢的工作,也希望各位的技术日渐精进,不用到处吃瘪。
(`_´)ゞ如果各位火眼金睛的观众老爷们发现哪里有错误或是有更好的实现,欢迎评论区指出,如果不出意外下一篇就是八皇后或者二叉树或者高阶函数什么的(之前说的正则就丢一边吧(≧∇≦)),虽然平常用不着,但可以拿来忽悠面试官。
