

前言
前段时间学习node、慕课网Scott老师的课程中有一节网络爬虫、闲暇之余写出来,共勉。
第一次写、还请见谅。
目录:
- 安装node,并下载依赖
- 搭建服务
- 请求我们要爬取的页面,返回json
安装node
我们开始安装node,可以去node官网下载nodejs.org/zh-cn/,下载完成后运行node使用
node -v安装成功后会显示你的node版本号。
搭建服务器
安装依赖
npm install express
创建一个demo.js文件夹
引入http,监听8080端口
var http = require('http');
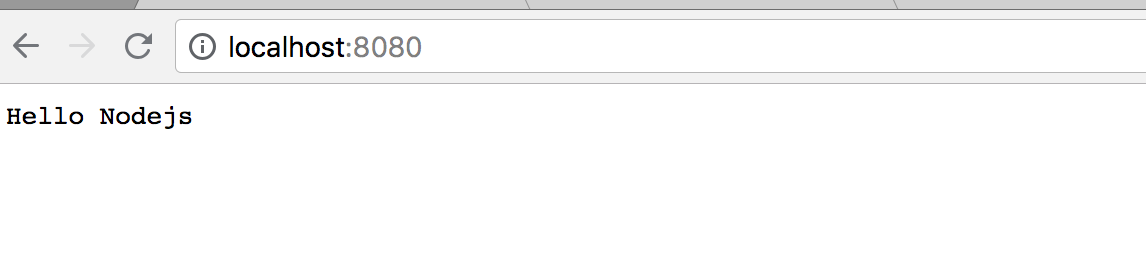
http .createServer(function (req,res) { res.writeHead(200, {'Content-Type':'text/plain'}); res.write('Hello Nodejs'); res.end(); }) .listen(8080);//端口号随意终端运行node demo.js、浏览器打开输入http://localhost:8080/
使用promise爬取网页数据
安装依赖
npm install bluebird //引入promise
npm install cheerio //为服务器特别定制的,快速、灵活、实施的jQuery核心实现
npm install fs //处理文件
var http = require('http');const fs = require('fs');var Promise = require('bluebird');var cheerio = require('cheerio');
var baseUrl = {
"htmlUrl": 'http://www.imooc.com/learn/',
"numberUrl": 'http://www.imooc.com/course/AjaxCourseMembers?ids='
};
videoIds = [348, 259, 197, 134, 75]
请求我们的地址:http://www.imooc.com/learn/
function filterChapters(html) {
var $ = cheerio.load(html)
var chapters = $('.chapter')
var title = $('#main .course-infos .hd h2').text().trim();
var courseData = {
title: title,
videos: []
}
chapters.each(function(item) {
var chapter = $(this)
var chapterTitle = chapter.find('h3').text().trim();
var videos = chapter.find('.video').children('li')
var chapterData = {
chapterTitle,
videos: []
}
videos.each(function(item) {
var video = $(this).find('.J-media-item')
var videoTitle = video.contents().filter(function() {
return this.nodeType == 3;
}).text().trim().split('\n');
var id = video.attr('href').split('video/')[1].trim();
chapterData.videos.push({
title: videoTitle[0].trim(),
id: id
})
//console.log(JSON.stringify(chapterData, undefined, 2));
});
courseData.videos.push(chapterData)
});
return courseData
}
function printCourseInfo(coursesData) {
// console.log(coursesData);
coursesData.forEach(function(courseData) {
console.log(courseData.number + '人学过' + courseData.title + '\n')
})
coursesData.forEach(courseData => {
// console.log('####' + courseData + '\n')
courseData.videos.forEach(function(item) {
var chapterTitle = item.chapterTitle
console.log(chapterTitle + '\n')
item.videos.forEach(function(video) {
console.log(' [' + video.id + ']' + video.title + '\n')
})
})
});
}
function getPageAsync(url) {
return new Promise(function(resolve, reject) {
console.log('*********正在爬取' + url + '*********')
var html = ''
var number = 0
http.get(url.htmlUrl, function(res) {
res.on('data', function(data) {
html += data
})
res.on('end', function() {
console.log("*************开始获取学习人数*************")
http.get(url.numberUrl, function(res) {
var resData = '';
res.on('data', function(data) {
resData += data;
});
res.on('end', function(res) {
number = JSON.parse(resData).data[0].numbers;
resolve({
"html": html,
"number": number
})
})
})
}).on('error', function(e) {
reject(e)
console.log('获取数据出错')
})
})
})
}
var fetchCourseArray = []
videoIds.forEach(function(id) {
fetchCourseArray.push(getPageAsync({
"htmlUrl": baseUrl.htmlUrl + id,
"numberUrl": baseUrl.numberUrl + id
}))
})
Promise.all(fetchCourseArray)
.then(function(pages) {
var coursesData = []
pages.forEach(function(page) {
fs.writeFileSync('./index.html', page.html);
var course = filterChapters(page.html)
course.number = parseInt(page.number)
coursesData.push(course)
})
coursesData.sort(function(a, b) {
return a.number < b.number
})
printCourseInfo(coursesData)
})
终端运行js文件


一个爬虫就完成了。希望可以到 项目上点一个 star 作为你对这个项目的认可与支持,谢谢。
