


上周(这说起来已经是五月初的事情了),Atlassian向开源社区开源了Escalator,它是一款经过优化的Kubernetes自动扩展工具,大家可以从我们的GitHub仓库[1]中拿到源码。
容器到Kubernetes之旅

在Atlassian内部,我们在自有平台和服务方面,已经有很长使用容器的传统。大概时间在2013年或者2014年左右,那时候我们正在基于Docker搭建公司最早的PaaS(Platform as a Service——平台即服务)平台。从微服务堆栈的容器,到构建微服务体系的CI/CD工作流程,Docker都能很方便的对过程完整打包,确保整个软件架构可以在任何需要的地方快速运行。无论是在个人笔记本上、开发阶段还是生产环境中,容器都能为我们提供可靠、准确的保障,并且我们只需要付出很少的代价。 但是容器旅行并不是一帆风顺,很快一个突显的问题出现了:容器编排。下面是四个最大的痛点:
-
我们需要将Pod规划好并安装到用户的计算基础设施上。
-
我们需要保证在云环境的硬件出现问题时我们的服务仍然正常。
-
我们需要能够扩展基础设施和应用,应对弹性用户负载中的峰值压力。
-
我们需要及时关闭不再使用的虚拟机资源,节约公司云上开支。
新问题出现:急需更好的自动扩展能力
在使用Kubernetes平台之初,我们能惊喜的感受到批量化工作负载到Kubernetes的便捷性。但是当并发数量攀升上来后,我们开始感觉的这条路走起来有些颠簸。实际感受是,集群不能足够快的扩容和缩容。 扩容:当前集群达到能力极限时,Kubernetes启动并服务于该负载需要持续几分钟时间,此时用户只能等待。这不是一个很好的解决方案,因为一些操作可能由于没有容错而失败。这个问题实际上是由于Kubernetes的集群扩展服务缺少一个关键特性:不能在集群达到能力极限之前提前做出预判并提前扩展计算节点。更简单点说,它不能为峰值负载提供一种缓冲机制。
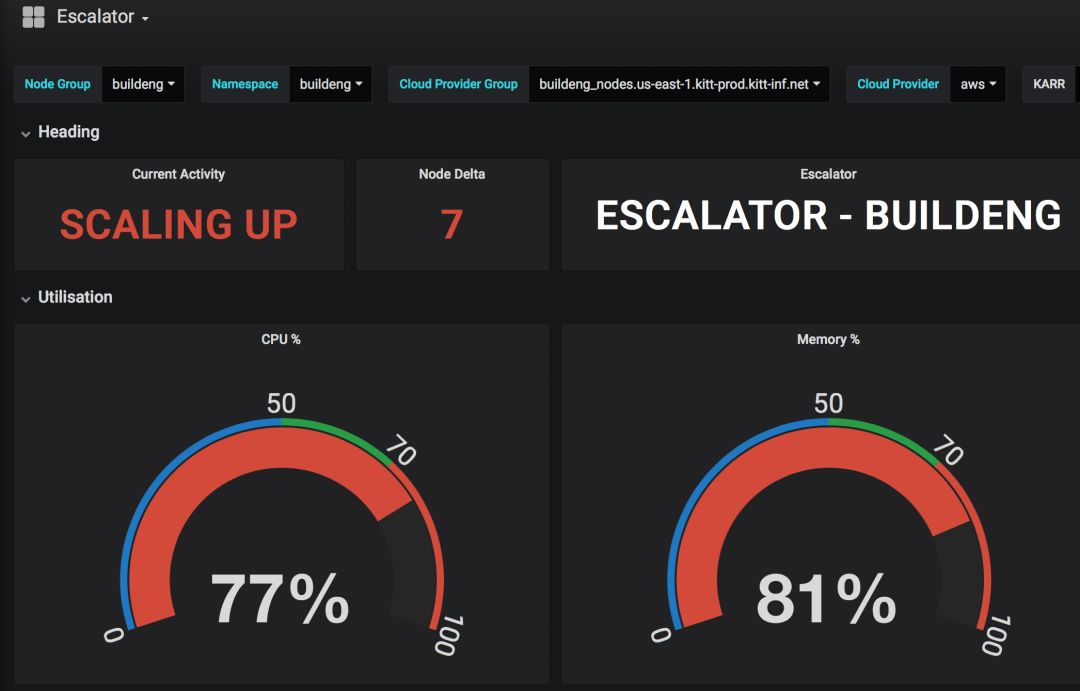
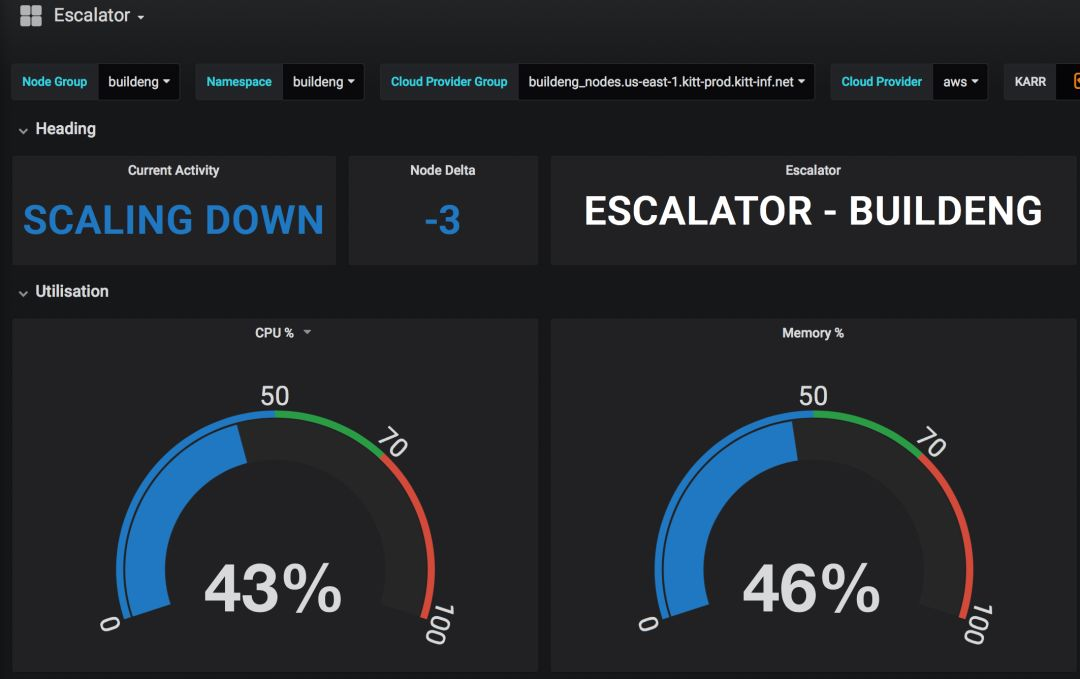
更好的解决方案:Escalator
带着解决上面两个扩展问题的动机,我们团队开始审视不同的选择。我们需要扩展Kubernetes集群扩展器的现有能力吗?是否存在一个新的自动扩展器可供利用?有必要开发一套我们自己的自动扩展工具来优化现有的工作负载吗? 经过对种种原因的分析,最终我们选择了构建一套自己的自动扩展工具的方案,这个工具称之为Escalator。我们假设了这套用于优化批量工作负载的自动扩展器的两个基础目标:提供先发制人的集群能力缓冲特性,用来防止用户直面集群负载能力达到上限的情形;对不再需要的资源执行强制缩容。此项目建立之初我们也为Ops团队做了一些考虑,通过使用Prometheus监控工具,我们只提供底层的东西,Ops团队也可以同时使用Prometheus进行其他集成工作。

接下来
目前为止我们已经在内部和外部客户中进行了Escalator的应用。我们同时也关心公司其他团队在生产上如何处理Escalator在我们的环境中起到了极大的作用,所以我们将它贡献给Kubernetes社区,作为开源软件,大家可以下载并使用它。 您可以从Github account上取得源码,同时我们也很希望您能做出贡献。您可以从Git上获得Escalator的下一步路线图,如果您有一些新的想法,欢迎提交PR或者feature request给我们。 相关链接:
-
https://github.com/atlassian/escalator
