线程池的原理: 线程池是预先创建线程的一种技术。线程池在还没有任务到来之前, 创建一定数量的线程,放入空闲队列中。这些线程都是处于睡眠状态, 即均为启动,不消耗CPU,而只是占用较小的内存空间。当请求到来之后, 缓冲池给这次请求分配一个空闲线程,把请求传入此线程中运行,进行处理。 当预先创建的线程都处于运行状态,即预制线程不够,线程池可以自由创建一定数量的新线程, 用于处理更多的请求。当系统比较闲的时候,也可以通过移除一部分一直处于停用状态的线程。
进程间的通信原理: OS提供了沟通的媒介供进程之间“对话”用。既然要沟通,如同人类社会的沟通一样, 沟通要付出时间和金钱,计算机中也一样,必然有沟通需要付出的成本。 出于所解决问题的特性,OS提供了多种沟通的方式,每种方式的沟通成本也不尽相同, 使用成本和沟通效率也有所不同。我们经常听到的 管道、消息队列、共享内存都是OS提供的供进程之间对话的方式。
Process(target, name, args, kwargs) name: 给进程取名字 默认为Process-1,Process-2..... p.name 查看进程名 args: 以元组的形式给target函数传参 kwargs: 以字典的形式给对应键的值传参
进程对象的其他常用属性方法: p.name p.start() p.join() p.pid: 获取创建进程的pid号 p.is_alive(): 判断进程是处于alive状态 p.daemon: 默认为Flase 如果设置为True 主进程结束时杀死所有子进程 daemon属性一定要在start()前设置 设置daemon为True 一般不需要加join() daemon不是真正意义上的守护进程 守护进程: 不受终端控制 后台自动运行 生命周期长
多进程copy一个文件拆分为两个进行保存
import os
from multiprocessing import Process
from time import sleep
#获取文件的大小
size = os.path.getsize("./timg.jpeg") # 获取文件的字节数
# f = open("timg.jpeg",'rb')
#复制前半部分
def copy1(img):
f = open(img,'rb') # 二进制读取要复制的文件
n = size // 2
fw = open('1.jpeg','wb') # 二进制创建文件
while True:
if n < 1024: # 判断文件大小是否大于1024字节 如果小于则直接读取写入
data = f.read(n)
fw.write(data)
break
data = f.read(1024) # 否则每次循环读取1024字节并写入
fw.write(data)
n -= 1024
f.close()
fw.close()
#复制后半部分
def copy2(img):
f = open(img,'rb') # 读取文件必须要每次读取 如果在父进程中打开文件流对像
# 子进程会通同时调用一个文件流对像 由于文件流对象特性会记录游标
# 如若先执行后半部复制这前半部会导致读取不到数据
fw = open('2.jpeg','wb')
f.seek(size // 2,0)
while True:
data = f.read(1024)
if not data:
break
fw.write(data)
fw.close()
f.close()
p1 = Process(target = copy1,args = ('timg.jpeg',)) # 创建子进程并让子进程分别同时复制
p2 = Process(target = copy2,args = ('timg.jpeg',))
p1.start()
p2.start()
p1.join()
p2.join()
os.path.getsize('./1.txt'): 读取文件大小 注: 1.如果多个子进程拷贝同一个父进程的对象则多个子进程 使用的是同一个对象(如文件队形,套接字,队列,管道。。。) 2.如果在创建子进程后单独创建的对象,则多个子进程各不相同
创建子自定义进程类 1.编写类继承 Process 2.在自定义类中加载父类 __init__以获取父类属性, 同时可以自定义新的属性 3.重写 run方法 在调用start时自动执行该方法 示例:
from multiprocessing import Process
import time
class ClockProcess(Process):
def __init__(self,value):
#调用父类init
super().__init__()
self.value = value
#重写run方法
def run(self):
for i in range(5):
time.sleep(self.value)
print("The time is {}".format(time.ctime()))
p = ClockProcess(2)
#自动执行run
p.start()
p.join()
进程的缺点: 进程在创建和销毁的过程中消耗的资源相对较多
进程池技术: 产生原因: 如果有大量的任务需要多进程完成,而调用周期比较短且需要频繁创建 此时可能产生大量进程频繁创建销毁的情况 消耗计算机资源较大 使用方法: 1.创建进程池,在池内放入适当数量的进程 2.将事件封装成函数。放入到进程池 3.事件不断运行,直到所有放入进程池事件运行完成 4. 关闭进程池, 回收进程
from multiprocessing import pool pool(Process) 功能:创建进程池对象 参数:进程数量 返回值:进程池对象 pool = pool() pool. apply_async(fun, args, kwds)(异步执行) 功能:将事件放入进程池内 参数: fun:要执行的函数 args:以元组形式为fun传参 kwds:以字典形式为fun传参 返回值: 返回一个事件对象,通过p. get()函数可以获取fun的返回值 pool.close(): 功能: 关闭进程池,无法再加入新的事件,并等待已有事件结束执行 pool.join() 功能:回收进程池 pool. apply(fun, args, kwds)(同步执行) 功能:将事件放入进程池内 参数: fun:要执行的函数 args:以元组形式为fun传参 kwds:以字典形式为fun传参 没有返回值 示例:
from multiprocessing import Pool
from time import sleep,ctime
def worker(msg):
sleep(2)
print(msg)
return ctime()
#创建进程池对象
pool = Pool(processes = 4)
result = []
for i in range(10):
msg = "hello %d"%i
#将事件放入进程池
r = pool.apply_async(func = worker,args = (msg,))
result.append(r)
#同步执行
# pool.apply(func = worker,args = (msg,))
#关闭进程池
pool.close()
#回收
pool.join()
#获取事件函数返回值
for i in result:
print(i.get())
pool. map(func, iter) 功能: 将要执行的事件放入进程池 参数: func 要执行的函数 iter 可迭代对象 示例:
from multiprocessing import Pool
import time
def fun(n):
time.sleep(1)
print("执行 pool map事件",n)
return n ** 2
pool = Pool(4)
#在进程池放入6个事件
r = pool.map(fun,range(6)) # map高阶函数 fun和iter执行6次
print("返回值列表:",r)
pool.close()
pool.join()进程间的通信(IPC) 由于进程空间独立,资源无法共享, 此时在进程间通讯就需要专门的通讯方法 通信方法: 管道、消息队列、共享内存 信号、信号量、套接字
管道通信: 在内存中开辟一块内存空间,形成管道结构 多个进程使用同一个管道,即可通过对管道的读写操作进行通讯 multiprocessing --> Pipe fd1,fd2 = Pipe(duplex=True) 功能:创建管道 参数: 默认表示双向管道 如果设置为False则为单向管道 返回值: 俩个管道对象的,分别表示管道的两端 如果是双向管道则均可读写 如果是单向管道则fd1只读,fd2只写 fd.recv() 功能:从管道读取信息 返回值:读取到的内容 当管道为空则阻塞 fd.send(data) 功能:向管道写入内容 参数:要写入的内容 当管道满时会阻塞 可以写入几乎所有Python所有数据类型
队列通信: 在内存中开辟队列结构空间,多个进程可见, 多个进程操作同一个队列对象可以实现消息存取工作 在取出时必须按照存入顺序取出(先进先出) q = Queue(maxsize=0) 功能: 创建队列对象 参数: maxsize 默认表示根据系统分配空间储存消息 如果传入一个正整数则表示最多存放多少条消息 返回值:队列对象 q.put(data,[block,timeout]) 功能:向队列存入消息 参数: data:存入消息(支持Python数据类型) block:默认True表示当队满时阻塞 设置为False 则为非阻塞 timeout:当block为True是表示超时检测 data = q.get([block,timeout]) 功能:取出消息 参数: block:设置为True 当队列为空时阻塞 设置为False表示非阻塞 timeout: 当block为True是表示超时检测
q.full() 判断队列是否为满 q.empty() 判断队列是否为空 q.qsize() 获取队列中消息的数量 q.close() 关闭队列
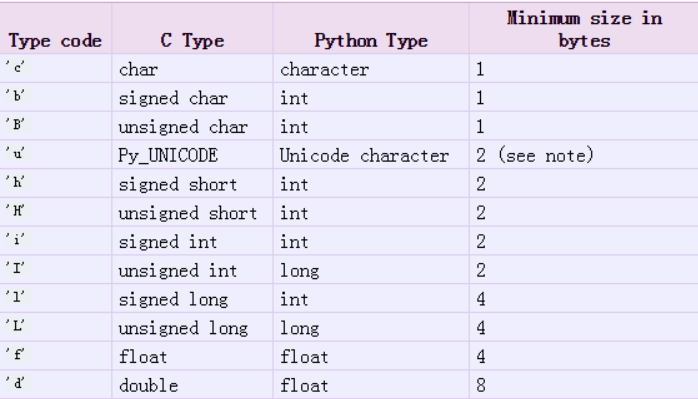
共享内存通信: 在内存中开辟一段空间存储数据对多个进程可见, 每次写入共享内存中的内容都会覆盖之前内容 对内存的读操作不会改变内存中的内容 form multiprocessing import Value,Array shm = Value(ctype,obj) 功能:共享内存共享空间 参数: ctype:字符串 要转换的c语言的数据类型 obj:共享内存的初始数据 返回值:返回共享内存对象 shm.value: 表示共享内存的值
示例:
from multiprocessing import Process,Value
import time
import random
#创建共享内存
money = Value('i',6000)
#存钱
def deposite():
for i in range(100):
time.sleep(0.05)
#对value的修改就是对共享内存的修改
money.value += random.randint(1,200)
#花销
def withdraw():
for i in range(100):
time.sleep(0.04)
#对value的修改就是对共享内存的修改
money.value -= random.randint(1,200)
d = Process(target = deposite)
w = Process(target = withdraw)
d.start()
w.start()
d.join()
w.join()
print(money.value)shm = Array(ctype,obj) 功能: 开辟共享内存空间 参数: ctype:要转换的数据类型 obj: 要存入共享内容的的数据(结构化数据) 列表、字符串 表示要存入得内容 要求数据结构内的类型相同 整数 表示要开辟几个单元的空间 返回值: 返回共享内存对象 可迭代对象
示例:
from multiprocessing import Process,Array
import time
#创建共享内存
shm = Array('c',b"hello") #字符类型要求是bytes
#开辟5个整形单元的共享内存空间
# shm = Array('i',5)
def fun():
for i in shm:
print(i)
shm[0] = b"H"
p = Process(target = fun)
p.start()
p.join()
print(shm.value) #从首地址打印字符串
# for i in shm:
# print(i)
三种进程间通信区别: 管道通信: 消息队列: 共享内存: 开辟空间: 内存 内存 内存 读写方式: 两端读写 先进先出 每次覆盖上次内容 单向/双向 效率: 一般 一般 较快 应用: 多用于父子进程 应用灵活广泛 复杂,需要同步互斥