

正则中的小九九
正则也用了很多了,而真正自己写的正则到真是寥寥无几呀,不是粘贴复制,就是粘贴复制修改,有时候对于一些正则还不是很理解匹配的过程,觉得这作为程序员最基本的知识还是应该自己写一下正则比较好,所以重新又看了一下正则,做一下记录,以备以后自己复习和使用;
正则主要是用于操作字符串
(一)作用
- 验证字符串是不是合法
- 查找符合制定特征的字符串
- 替换字符串
(二)前提知识点
- 零宽度:子表达式匹配的仅仅是个位置,或者匹配的内容并不保存到最终的匹配结果中,就认为这个子表达式是零宽的,(其实就是表达式匹配的开始位置和结束位置是一个位置);如:"^ $ (?=xxx) (?!=xxx)"
- 占有字符:子表达式匹配的是字符内容不是位置,并保存在最后的匹配结果中
var reg = /abc/; 可以认为/a/ /b/ /c/ 都是子表达式
(三)表达式
-
申明方式:
- 构造函数:
var reg1 = new RegExp("xyz",'gi'); //参数一:正则内容 //参数二:修饰符; // i:不区分大小写; // g:全局匹配; // m:多行匹配,遇到换行符也不结束,匹配到到字符串结束; - 字面量:
var reg = /xyz/gi;
- 构造函数:
-
方法:
- reg.test() //返回true|false
var reg = /zyx/i; var str="zyxaa" reg.test(str) // true; - exec方法、compile方法 可以自行了解
- 其他使用的都是字符串的方法,不是正则方法;
- reg.test() //返回true|false
-
匹配多字符
| 表达式 | 匹配范围 | 占位 | 表达式 | 匹配范围 |
|---|---|---|---|---|
| \d | 任意一个数字,0~9 中的任意一个 | \D匹配取非 \W | \w | 任意一个字母或数字或下划线 |
| \s | 包括空格、制表符、换页符等空白字符的其中任意一个 | \B匹配位置(\b 取非的位置) | \b | 匹配一个单词边界,一个位置:(其中一边是 "\w" 范围,另一边是 非"\w" 的范围) |
| . | 除了换行符(\n)以外的任意一个字符 | [^12A-Z]取补集 | [12A-Z] | 匹配中括号中的任意一个1或2或A到Z的字符 |
| ^ | 匹配开始位置,不匹配任何字符 | $ | 匹配结束位置 | |
| | | 两边表达式是或的关系 | () | 子表达式开始和结束的位置 |
1. 注意
很多元字符在字符组内都变成了普通字符,如(^$?)等
[.$^?]就是匹配点和$^?
[^] ^在第一个位置时候是取补集
- 次数修饰
| 表达式 | 匹配范围 | 占位 | 表达式 | 匹配范围 |
|---|---|---|---|---|
| {n} | 重复n次 | {m,} | 重复至少m次数 | |
| {m,n} | 重复次数在[m,n]这个范围 | ? | 重复0到1次 相当于{0,1} | |
| + | 重复次数大于等于1 相当于{1,} | * | 重复任意次数 相当于{0,} |
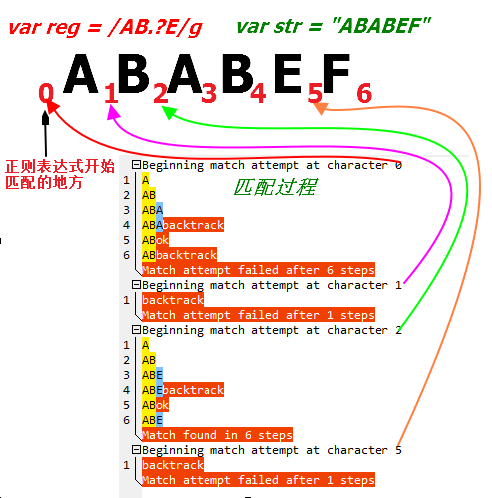
(四) 匹配过程
- 对于整个表达式来说,一般是从字符串位置0处开始尝试,中间有回溯等一些处理,如何匹配成功则返回,接着从成功之后的位置接着匹配,如何失败,就从位置1重新开始之前的匹配,以此类推,直到成功或者是匹配失败;
- 对于子表达式来说: 开始匹配的位置是上一个表达式匹配成功结束的位置;
- 例如下面匹配:
(五) 一些特殊的用法
-
匹配次数的贪婪与非贪婪
- 贪婪模式:正则默认情况是贪婪模式:在可以让整个表达式匹配成功的前提下,尽可能最多的去匹配字符串

- 非贪婪匹配:在匹配次数修饰符({m,n}/?+*)之后加上"?" 则在可以让整个表达式匹配成功的前提下,尽可能少的去匹配字符串;

-
捕获组的引用:
- 括号"( )"在正则中括号的作用(起到分组的效果):
- 在被修饰匹配次数的时候,括号中的表达式可以作为整体被修饰;
- 取匹配结果的时候,括号中的表达式匹配到的内容可以被单独得到;
- 捕获组 : 就是把正则表达式中子表达式(括号中的表达式)匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用。
- 引用:可以在正则表达式内部引用\number (反向引用), 也可以在正则表达式外部引用$number
- 引用number是和子表达式左侧括号出现的顺序相对应的
- 括号 "( )" 内的子表达式,如果希望匹配结果不进行记录供以后使用,可以使用 "(?:xxxxx)" 格式

- 括号"( )"在正则中括号的作用(起到分组的效果):
-
正则断言(正向、负向、先行、后行)
js中不支持后行断言,所以只介绍先行:
- (?=pattern) 正向先行断言 //代表字符串中的一个位置,紧接该位置之后的字符序列能够匹配pattern。
- (?!pattern) 负向先行断言 //代表字符串中的一个位置,紧接该位置之后的字符序列不能匹配pattern。

(六) 常用正则表达式
最后送上一些(个)正则表达式供大家使用
- 只允许字母数字下划线,必须含有大小写和数字和下划线
var reg=/^(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*\_)\w{8,20}$/;
- 银行卡四位一空格展示:
var str="888888888888888888";
var newStr= str.replace(/\s/g, '').replace(/(.{4})/g, "$1 ");
- 有趣的正则:
var reg = /[^\w.$]/;
reg 匹配非字母数字下划线点和$ (匹配特殊字符和中文)
