

代码仓库地址:https://gitee.com/jikeh/BigData
开发环境:maven、IntelliJ IDEA
环境搭建:Hadoop单节点集群环境搭建
入目项目:Hadoop实战:MapReduce之WordCount实例
进阶项目:Hadoop实战:数据预处理之数据排序实例Hadoop实战:数据预处理之数据去重实例(IP去重、url去重)
说明:这个案例与wordcount类似
1、启动hadoop
cd /usr/local/Env/Hadoop/hadoop-2.6.5/sbin/
./start-all.sh
2、HDFS创建目录
hadoop fs -mkdir -p /jikeh/datascore/input
3、上传文本文件到HDFS
测试数据:
Chinese:
张三 78
李四 89
王五 96
赵六 67
Math:
张三 88
李四 99
王五 66
赵六 77
English:
张三 80
李四 82
王五 84
赵六 86
hadoop fs -copyFromLocal /usr/local/src/* /jikeh/datascore/input
4、运行datascore程序
语法:hadoop jar ***.jar [输入文件] [输出目录]
hadoop jar datascore-0.0.1-SNAPSHOT.jar com/jikeh/hadoop/datascore/DataScore
5、查看运行结果
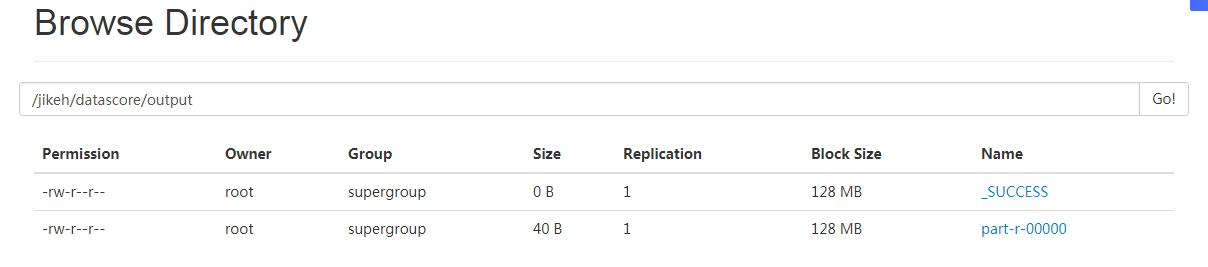
hadoop fs -ls /jikeh/datascore/output
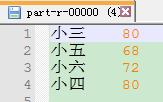
hadoop fs -cat /jikeh/datascore/output/part-r-00000
补充:常用HDFS命令
hadoop fs -mkdir 创建HDFS目录
hadoop fs -ls 列出HDFS目录
hadoop fs -copyFromLocal 复制本地文件到HDFS
hadoop fs -put 复制本地文件到HDFS
hadoop fs -cat 查看HDFS目录下的文件内容
hadoop fs -copyToLocal 将HDFS上的文件复制到本地
hadoop fs -get 将HDFS上的文件复制到本地
hadoop fs -cp 复制HDFS文件
hadoop fs -rm 删除HDFS文件
hadoop fs -rm -R /jikeh/datascore/output
