

OpenTraceing 规范
SOFATracer 对 OpenTraceing 的实现
SOFATracer 就是根据 OpenTracing 规范 衍生出来的分布式 链路跟 踪的解决方案。
概念
OpenTracing 标准中有三个重要的相互关联的类型,分别是Tracer, Span和 SpanContext。
【下面的概念说明过程中,如不做说明,所使用的案例代码均以SOFATracer中的实现为例。】
Tracer
一个 trace 代表一个潜在的,分布式的,存在并行数据或并行执行轨迹(潜在的分布式、并行)的系统。一个trace可以认为是多个span的有向无环图(DAG)。
Tracer接口用来创建Span,以及处理如何处理Inject(serialize) 和 Extract (deserialize),用于跨进程边界传递。
SOFATracer 中 SofaTracer这个类实现了 opentracing 的 Tracer 接口,并在此规范接口上做了一些扩展。看下Tracer 中声明的方法:
public interface Tracer {
//启动一个新的span
SpanBuilder buildSpan(String operationName);
//将SpanContext上下文Inject(注入)到carrier
<C> void inject(SpanContext spanContext, Format<C> format, C carrier);
//将SpanContext上下文从carrier中Extract(提取)
<C> SpanContext extract(Format<C> format, C carrier);
interface SpanBuilder {
// 省略
}
}
所以从接口定义来看,要实现一个Tracer,必须要实现其以下的几个能力:
启动一个新的span
SOFATracer 实现了 Tracer 中 buildSpan 方法:
@Override
public SpanBuilder buildSpan(String operationName) {
return new SofaTracerSpanBuilder(operationName);
}
operationName :操作名称,字符串类型,表示由Span完成的工作 (例如,RPC方法名称、函数名称或一个较大的计算任务中的阶段的名称)。操作名称应该用泛化的字符串形式标识出一个Span实例。
何为泛化的字符串形式,比如现在有一个操作:获取用户 ;下面有几种标识方式:
- 1、/get
- 2、/get/user
- 3、/get/user/123
方式1过于抽象,方式3过于具体。方式2是正确的操作名。
将SpanContext上下文Inject(注入)到carrier
@Override
public <C> void inject(SpanContext spanContext, Format<C> format, C carrier) {
RegistryExtractorInjector<C> registryInjector = TracerFormatRegistry.getRegistry(format);
if (registryInjector == null) {
throw new IllegalArgumentException("Unsupported injector format: " + format);
}
registryInjector.inject((SofaTracerSpanContext) spanContext, carrier);
}
SpanContext:实例format(格式化)描述,一般会是一个字符串常量,但不做强制要求。通过此描述,通知Tracer实现,如何对SpanContext进行编码放入到carrier中。 carrier,根据format确定。Tracer实现根据format声明的格式,将SpanContext序列化到carrier对象中。
RegistryExtractorInjector 见后面
将SpanContext上下文从carrier中Extract(提取)
@Override
public <C> SpanContext extract(Format<C> format, C carrier) {
RegistryExtractorInjector<C> registryExtractor = TracerFormatRegistry.getRegistry(format);
if (registryExtractor == null) {
throw new IllegalArgumentException("Unsupported extractor format: " + format);
}
return registryExtractor.extract(carrier);
}
- 格式描述符(
format descriptor)(通常但不一定是字符串常量),告诉Tracer的实现如何在载体对象中对SpanContext进行编码 - 载体(
carrier),其类型由格式描述符指定。Tracer的实现将根据格式描述对此载体对象中的SpanContext进行编码
返回一个SpanContext实例,可以使用这个SpanContext实例,通过Tracer创建新的Span。
Format
从Tracer的注入和提取来看,format都是必须的。
Inject(注入)和Extract(提取)依赖于可扩展的format参数。format参数规定了另一个参数"carrier"的类型,同时约束了"carrier"中SpanContext是如何编码的。所有的Tracer实现,都必须支持下面的format。
Text Map: 基于字符串:字符串的map,对于key和value不约束字符集。HTTP Headers: 适合作为HTTP头信息的,基于字符串:字符串的map。(RFC 7230.在工程实践中,如何处理HTTP头具有多样性,强烈建议tracer的使用者谨慎使用HTTP头的键值空间和转义符)Binary: 一个简单的二进制大对象,记录SpanContext的信息。
在上面的注入和提取代码中,有如下代码片段:
//注入
RegistryExtractorInjector<C> registryInjector =
TracerFormatRegistry.getRegistry(format);
//提取
RegistryExtractorInjector<C> registryExtractor =
TracerFormatRegistry.getRegistry(format);
来通过TracerFormatRegistry这个类来来看下 SOFATracer 中的 Format 的具体实现。
X-B3
在看Format之前,先了解下X-B3。
Access-Control-Expose-Headers:
X-B3-TraceId,X-B3-ParentSpanId,X-B3-SpanId
HTTP请求时其span参数通过http headers来传递追踪信息;header中对应的key分别是:
- X-B3-TraceId: 64 encoded bits(id被encode为hex Strings)
- X-B3-SpanId : 64 encoded bits
- X-B3-ParentSpanId: 64 encoded bits
- X-B3-Sampled:(是否采样) Boolean (either “1” or “0”)(下面的调用是否进行采样)
- X-B3-Flags:a Long
SOFATracer 中的 Format
具体代码在 tracer-core -> com.alipay.common.tracer.core.registy 包下:
- TextMapFormatter
- TextMapB3Formatter
- HttpHeadersFormatter
- HttpHeadersB3Formatter
- BinaryFormater
BinaryFormater:这个的注入和提取实现没有编解码一说;本身就是基于二进制流的操作。
TextMapB3Formatter/TextMapFormatter 和 HttpHeadersB3Formatter/HttpHeadersFormatter 区别就在于编解码不同。HttpHeadersB3Formatter使用的是 URLDecoder.decode && URLDecoder.encode ; TextMapB3Formatter 返回的是值本身(如果为空或者null则返回空字符串)。
TextMapFormatter和TextMapB3Formatter区别在于注入或者提取是使用的key不用。TextMapB3Formatter中使用的是 x-b3-{} 的字符串作为key。
Span
一个span代表系统中具有开始时间和执行时长的逻辑运行单元。span之间通过嵌套或者顺序排列建立逻辑因果关系。当Span结束后(span.finish()),除了通过Span获取SpanContext外,下列其他所有方法都不允许被调用。
同样先来看下opentracing规范api 定义的 span 的定义及方法:
public interface Span extends Closeable {
SpanContext context();
void finish();
void finish(long finishMicros);
void close();
Span setTag(String key, String value);
Span setTag(String key, boolean value);
Span setTag(String key, Number value);
Span log(Map<String, ?> fields);
Span log(long timestampMicroseconds, Map<String, ?> fields);
Span log(String event);
Span log(long timestampMicroseconds, String event);
Span setBaggageItem(String key, String value);
String getBaggageItem(String key);
Span setOperationName(String operationName);
Span log(String eventName, /* @Nullable */ Object payload);
Span log(long timestampMicroseconds, String eventName, /* @Nullable */ Object payload);
}
通过Span获取SpanContext
//SOFATracerSpan
@Override
public SpanContext context() {
return this.sofaTracerSpanContext;
}
返回值,Span构建时传入的SpanContext。这个返回值在Span结束后(span.finish()),依然可以使用。
复写操作名
@Override
public Span setOperationName(String operationName) {
this.operationName = operationName;
return this;
}
operationName:新的操作名,覆盖构建Span时,传入的操作名。
结束Span
@Override
public void finish() {
this.finish(System.currentTimeMillis());
}
@Override
public void finish(long endTime) {
this.setEndTime(endTime);
//关键记录:report span
this.sofaTracer.reportSpan(this);
SpanExtensionFactory.logStoppedSpan(this);
}
有一个可选参数,如果指定完成时间则使用当前指定的时间;如果省略此参数,使用当前时间作为完成时间。finish方法中会将当前span进行report操作。
为Span设置tag
Tag是一个key:value格式的数据。key必须是String类型,value可以是字符串、布尔或者数字。
- 字符串类型的value 设置tag
@Override
public Span setTag(String key, String value) {
if (StringUtils.isBlank(key) || StringUtils.isBlank(value)) {
return this;
}
this.tagsWithStr.put(key, value);
//注意:server 还是 client 在 OpenTracing 标准中是用 tags 标识的,所以在这里进行判断
if (isServer()) {
Reporter serverReporter = this.sofaTracer.getServerReporter();
if (serverReporter != null) {
this.setLogType(serverReporter.getReporterType());
}
} else if (isClient()) {
Reporter clientReporter = this.sofaTracer.getClientReporter();
if (clientReporter != null) {
this.setLogType(clientReporter.getReporterType());
}
}
return this;
}
- 布尔类型的value 设置tag
public Span setTag(String key, boolean value) {
this.tagsWithBool.put(key, value);
return this;
}
- 数字类型的value 设置tag
public Span setTag(String key, Number number) {
if (number == null) {
return this;
}
this.tagsWithNumber.put(key, number);
return this;
}
Log结构化数据
@Override
public Span log(long currentTime, Map<String, ?> map) {
AssertUtils.isTrue(currentTime >= startTime, "current time must greater than start time");
this.logs.add(new LogData(currentTime, map));
return this;
}
@Override
public Span log(Map<String, ?> map) {
return this.log(System.currentTimeMillis(), map);
}
- Map<String, ?> map : 键必须是字符串类型,值可以是任意类型
- currentTime : 时间戳。如果指定时间戳,那么它必须在
span的开始和结束时间之内。
设置一个baggage(随行数据)元素
Baggage元素是一个键值对集合,将这些值设置给给定的Span,Span的SpanContext,以及所有和此Span有直接或者间接关系的本地Span。 也就是说,baggage元素随trace一起保持在带内传递。(译者注:带内传递,在这里指,随应用程序调用过程一起传递)
Baggage元素为OpenTracing的实现全栈集成,提供了强大的功能 (例如:任意的应用程序数据,可以在移动端创建它,显然的,它会一直传递了系统最底层的存储系统。由于它如此强大的功能,他也会产生巨大的开销,请小心使用此特性。
再次强调,请谨慎使用此特性。每一个键值都会被拷贝到每一个本地和远程的下级相关的span中,因此,总体上,他会有明显的网络和CPU开销。
@Override
public Span setBaggageItem(String key, String value) {
this.sofaTracerSpanContext.setBizBaggageItem(key, value);
return this;
}
SofaTracerSpan 中的属性
- sofaTracer : 当前 tracer
- spanReferences : 当前span的关系,ChildOf(引用) or FollowsFrom(跟随)
- tagsWithStr : String 类型的tag 集合
- tagsWithBool : 布尔类型的tag集合
- tagsWithNumber : 数值类型的tag集合
- logs : log结构化数据列表,通过span.log(map)操作的map,均存储在logs中。
- operationName:当前span的操作名
- sofaTracerSpanContext:当前 spanContext
- startTime : 当前span 开始时间
- endTime : 当前span 结束时间,在finish方法中传入。
- logType : report时才有意义:摘要日志类型,日志能够正确打印的关键信息;当前 span 的日志类型,如:客户端为 rpc-client-digest.log,服务端为 rpc-server-digest.log
- parentSofaTracerSpan:父亲 span,当作为客户端结束并弹出线程上下文时,需要将父亲 span 再放入
SpanContext
opentracing 中 SpanContext 接口中只有一个baggageItems方法,通过这个方法来遍历所有的baggage元素。
public interface SpanContext {
Iterable<Map.Entry<String, String>> baggageItems();
}
相对于OpenTracing中其他的功能,SpanContext更多的是一个“概念”。也就是说,OpenTracing实现中,需要重点考虑,并提供一套自己的API。
OpenTracing的使用者仅仅需要,在创建span、向传输协议Inject(注入)和从传输协议中Extract(提取)时,使用SpanContext和references,
OpenTracing要求,SpanContext是不可变的,目的是防止由于Span的结束和相互关系,造成的复杂生命周期问题。
Disruptor 简介
A High Performance Inter-Thread Messaging Library 高性能的线程间消息传递库
关于 Disruptor 的 一些原理分析可以参考:disruptor
案例
先通过 Disruptor 的一个小例子来有个直观的认识;先看下它的构造函数:
public Disruptor(
final EventFactory<T> eventFactory,
final int ringBufferSize,
final ThreadFactory threadFactory,
final ProducerType producerType,
final WaitStrategy waitStrategy)
{
this(
RingBuffer.create(producerType, eventFactory, ringBufferSize, waitStrategy),
new BasicExecutor(threadFactory));
}
- eventFactory : 在环形缓冲区中创建事件的
factory - ringBufferSize:环形缓冲区的大小,必须是2的幂。
- threadFactory:用于为处理器创建线程。
- producerType:生成器类型以支持使用正确的
sequencer和publisher创建RingBuffer;枚举类型,SINGLE、MULTI两个项。对应于SingleProducerSequencer和MultiProducerSequencer两种Sequencer。 - waitStrategy : 等待策略;
如果我们想构造一个disruptor,那么我们就需要上面的这些组件。从eventFactory来看,还需要一个具体的Event来作为消息事件的载体。【下面按照官方给的案例进行简单的修改作为示例】
消息事件 LongEvent ,能够被消费的数据载体
public class LongEvent {
private long value;
public void set(long value) {
this.value = value;
}
public long getValue() {
return value;
}
}
创建消息事件的factory
public class LongEventFactory implements EventFactory<LongEvent> {
@Override
public LongEvent newInstance() {
return new LongEvent();
}
}
ConsumerThreadFactory
public class ConsumerThreadFactory implements ThreadFactory {
private final AtomicInteger index = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "disruptor-thread-" + index.getAndIncrement());
}
}
OK ,上面的这些可以满足创建一个disruptor了:
private int ringBufferCapacity = 8;
//消息事件生产Factory
LongEventFactory longEventFactory = new LongEventFactory();
//执行事件处理器线程Factory
ConsumerThreadFactory consumerThreadFactory = new ConsumerThreadFactory();
//用于环形缓冲区的等待策略。
WaitStrategy waitStrategy = new BlockingWaitStrategy();
//构建disruptor
Disruptor<LongEvent> disruptor = new Disruptor<>(
longEventFactory,
ringBufferCapacity,
longEventThreadFactory,
ProducerType.SINGLE,
waitStrategy);
现在是已经有了 disruptor 了,然后通过:start 来启动:
//启动 disruptor
disruptor.start();
到这里,已经构建了一个disruptor;但是目前怎么使用它来发布消息和消费消息呢?
发布消息
下面在 for 循环中 发布 5 条数据:
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
for (long l = 0; l < 5; l++)
{
long sequence = ringBuffer.next();
LongEvent event = ringBuffer.get(sequence);
event.set(100+l);
System.out.println("publish event :" + l);
ringBuffer.publish(sequence);
Thread.sleep(1000);
}
消息已经发布,下面需要设定当前disruptor的消费处理器。前面已经有个LongEvent 和 EventFactory ; 在disruptor中是通过 EventHandler 来进行消息消费的。
编写消费者代码
public class LongEventHandler implements EventHandler<LongEvent> {
@Override
public void onEvent(LongEvent event, long sequence, boolean endOfBatch) throws Exception {
System.out.println("Event: " + event.getValue()+" -> " + Thread.currentThread().getName());
Thread.sleep(2000);
}
}
将 eventHandler 设置到 disruptor 的处理链上
//将处理事件的事件处理程序 -> 消费事件的处理程序
LongEventHandler longEventHandler = new LongEventHandler();
disruptor.handleEventsWith(longEventHandler);
运行结果(这里):
publish event :0
Event: 0 -> disruptor-thread-1
-------------------------------->
publish event :1
Event: 1 -> disruptor-thread-1
-------------------------------->
publish event :2
Event: 2 -> disruptor-thread-1
-------------------------------->
publish event :3
Event: 3 -> disruptor-thread-1
-------------------------------->
publish event :4
Event: 4 -> disruptor-thread-1
-------------------------------->
基本概念和原理
Disruptor
整个基于ringBuffer实现的生产者消费者模式的容器。主要属性
private final RingBuffer<T> ringBuffer;
private final Executor executor;
private final ConsumerRepository<T> consumerRepository = new ConsumerRepository<>();
private final AtomicBoolean started = new AtomicBoolean(false);
private ExceptionHandler<? super T> exceptionHandler = new ExceptionHandlerWrapper<>();
ringBuffer:内部持有一个RingBuffer对象,Disruptor内部的事件发布都是依赖这个RingBuffer对象完成的。executor:消费事件的线程池consumerRepository:提供存储库机制,用于将EventHandler与EventProcessor关联起来started: 用于标志当前Disruptor是否已经启动exceptionHandler: 异常处理器,用于处理BatchEventProcessor事件周期中uncaught exceptions。
RingBuffer
环形队列[实现上是一个数组],可以类比为BlockingQueue之类的队列,ringBuffer的使用,使得内存被循环使用,减少了某些场景的内存分配回收扩容等耗时操作。
public final class RingBuffer<E> extends RingBufferFields<E>
implements Cursored, EventSequencer<E>, EventSink<E>
- E:在事件的交换或并行协调期间存储用于共享的数据的实现 -> 消息事件
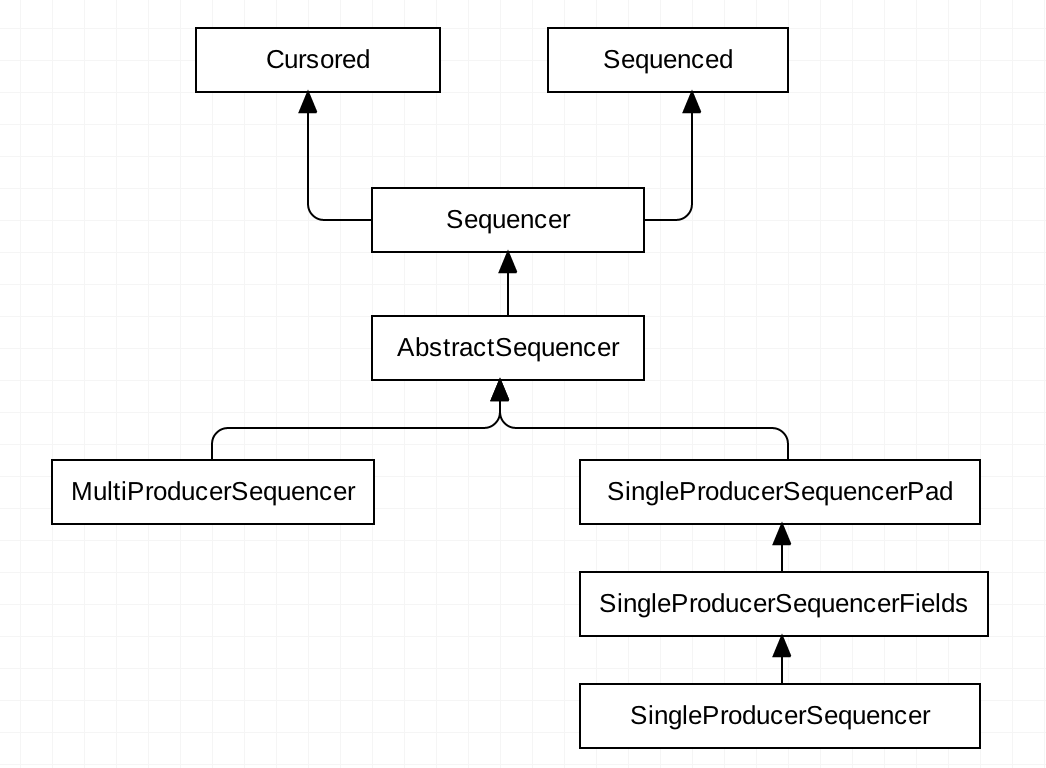
Sequencer
RingBuffer 中 生产者的顶级父接口,其直接实现有SingleProducerSequencer和MultiProducerSequencer;对应 SINGLE、MULTI 两个枚举值。
EventHandler
事件处置器,改接口用于对外扩展来实现具体的消费逻辑。如上面 demo 中的 LongEventHandler ;
//回调接口,用于处理{@link RingBuffer}中可用的事件
public interface EventHandler<T> {
void onEvent(T event, long sequence, boolean endOfBatch) throws Exception;
}
event:RingBuffer已经发布的事件sequence: 正在处理的事件 的序列号endOfBatch: 用来标识否是来自RingBuffer的批次中的最后一个事件
SequenceBarrier
消费者路障。规定了消费者如何向下走。事实上,该路障算是变向的锁。
final class ProcessingSequenceBarrier implements SequenceBarrier {
//当等待(探测)的需要不可用时,等待的策略
private final WaitStrategy waitStrategy;
//依赖的其它Consumer的序号,这个用于依赖的消费的情况,
//比如A、B两个消费者,只有A消费完,B才能消费。
private final Sequence dependentSequence;
private volatile boolean alerted = false;
//Ringbuffer的写入指针
private final Sequence cursorSequence;
//RingBuffer对应的Sequencer
private final Sequencer sequencer;
//exclude method
}
waitStrategy 决定了消费者采用何种等待策略。
WaitStrategy
Strategy employed for making {@link EventProcessor}s wait on a cursor {@link Sequence}.
EventProcessor 的等待策略;具体实现在 disruptor 中有8种,
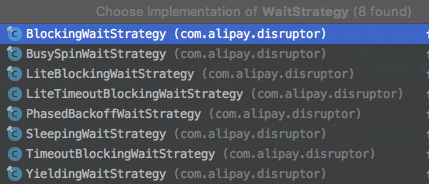
这些等待策略不同的核心体现是在如何实现 waitFor 这个方法上。
EventProcessor
事件处理器,实际上可以理解为消费者模型的框架,实现了线程Runnable的run方法,将循环判断等操作封在了里面。该接口有三个实现类:
1、BatchEventProcessor
public final class BatchEventProcessor<T> implements EventProcessor {
private final AtomicBoolean running = new AtomicBoolean(false);
private ExceptionHandler<? super T> exceptionHandler = new FatalExceptionHandler();
private final DataProvider<T> dataProvider;
private final SequenceBarrier sequenceBarrier;
private final EventHandler<? super T> eventHandler;
private final Sequence sequence = new Sequence( Sequencer.INITIAL_CURSOR_VALUE);
private final TimeoutHandler timeoutHandler;
//exclude method
}
- ExceptionHandler:异常处理器
- DataProvider:数据来源,对应
RingBuffer - EventHandler:处理
Event的回调对象 - SequenceBarrier:对应的序号屏障
- TimeoutHandler:超时处理器,默认情况为空,如果要设置,只需要要将关联的
EventHandler实现TimeOutHandler即可。
如果我们选择使用 EventHandler 的时候,默认使用的就是 BatchEventProcessor,它与EventHandler是一一对应,并且是单线程执行。
如果某个RingBuffer有多个BatchEventProcessor,那么就会每个BatchEventProcessor对应一个线程。
2、WorkProcessor
public final class WorkProcessor<T> implements EventProcessor {
private final AtomicBoolean running = new AtomicBoolean(false);
private final Sequence sequence = new Sequence(Sequencer.INITIAL_CURSOR_VALUE);
private final RingBuffer<T> ringBuffer;
private final SequenceBarrier sequenceBarrier;
private final WorkHandler<? super T> workHandler;
private final ExceptionHandler<? super T> exceptionHandler;
private final Sequence workSequence;
private final EventReleaser eventReleaser = new EventReleaser() {
@Override
public void release() {
sequence.set(Long.MAX_VALUE);
}
};
private final TimeoutHandler timeoutHandler;
}
基本和 BatchEventProcessor 类似,不同在于,用于处理Event的回调对象是WorkHandler。
原理图
无消费者情况下,生产者保持生产,但是 remainingCapacity 保持不变
在写demo的过程中,本来想通过不设定 消费者 来观察 RingBuffer 可用容量变化的。但是验证过程中,一直得不到预期的结果,(注:没有设置消费者,只有生产者),先看结果:
publish event :0
bufferSie:8
remainingCapacity:8
cursor:0
-------------------------------->
publish event :1
bufferSie:8
remainingCapacity:8
cursor:1
-------------------------------->
publish event :2
bufferSie:8
remainingCapacity:8
cursor:2
-------------------------------->
publish event :3
bufferSie:8
remainingCapacity:8
cursor:3
-------------------------------->
publish event :4
bufferSie:8
remainingCapacity:8
cursor:4
-------------------------------->
publish event :5
bufferSie:8
remainingCapacity:8
cursor:5
-------------------------------->
publish event :6
bufferSie:8
remainingCapacity:8
cursor:6
-------------------------------->
publish event :7
bufferSie:8
remainingCapacity:8
cursor:7
-------------------------------->
publish event :8
bufferSie:8
remainingCapacity:8
cursor:8
-------------------------------->
publish event :9
bufferSie:8
remainingCapacity:8
cursor:9
-------------------------------->
从结果来看,remainingCapacity 的值应该随着 发布的数量 递减的;但是实际上它并没有发生任何变化。
来看下ringBuffer.remainingCapacity() 这个方法:
/**
* Get the remaining capacity for this ringBuffer.
*
* @return The number of slots remaining.
*/
public long remainingCapacity()
{
return sequencer.remainingCapacity();
}
这里面又使用 sequencer.remainingCapacity()这个方法来计算的。上面的例子中使用的是ProducerType.SINGLE,那来看SingleProducerSequencer 这个里面remainingCapacity的实现。
@Override
public long remainingCapacity()
{
//上次申请完毕的序列值
long nextValue = this.nextValue;
//计算当前已经消费到的序列值
long consumed = Util.getMinimumSequence(gatingSequences, nextValue);
//当前生产到的序列值
long produced = nextValue;
return getBufferSize() - (produced - consumed);
}
来解释下这段代码的含义:
假设当前 ringBuffer 的 bufferSize 是 8 ;上次申请到的序列号是 5,其实也就是说已经生产过占用的序列号是5;假设当前已经消费到的序列号是 3,那么剩余的容量为: 8-(5-2) = 5;
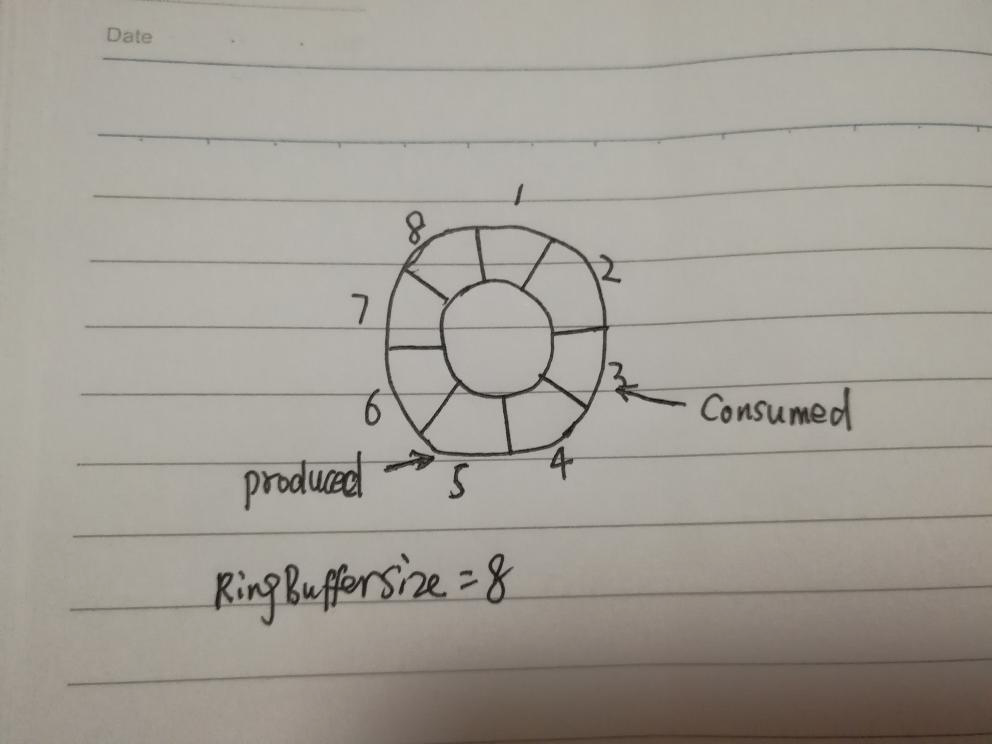
因为这里我们可以确定 bufferSize 和 produced 的值了,那么 remainingCapacity 的结果就取决于getMinimumSequence的计算结果了。
public static long getMinimumSequence(final Sequence[] sequences, long minimum)
{
for (int i = 0, n = sequences.length; i < n; i++)
{
long value = sequences[i].get();
minimum = Math.min(minimum, value);
}
return minimum;
}
这个方法是从 Sequence 数组中获取最小序列 。如果sequences 为空,则返回 minimum。回到上一步,看下sequences这个数组是从哪里过来的,它的值在哪里设置的。
long consumed = Util.getMinimumSequence(gatingSequences, nextValue);
gatingSequences是 SingleProducerSequencer父类 AbstractSequencer 中的成员变量:
protected volatile Sequence[] gatingSequences = new Sequence[0];
gatingSequences 是在下面这个方法里面来管理的。
/**
* @see Sequencer#addGatingSequences(Sequence...)
*/
@Override
public final void addGatingSequences(Sequence... gatingSequences)
{
SequenceGroups.addSequences(this, SEQUENCE_UPDATER, this, gatingSequences);
}
这个方法的调用栈向前追溯有这几个地方调用了:
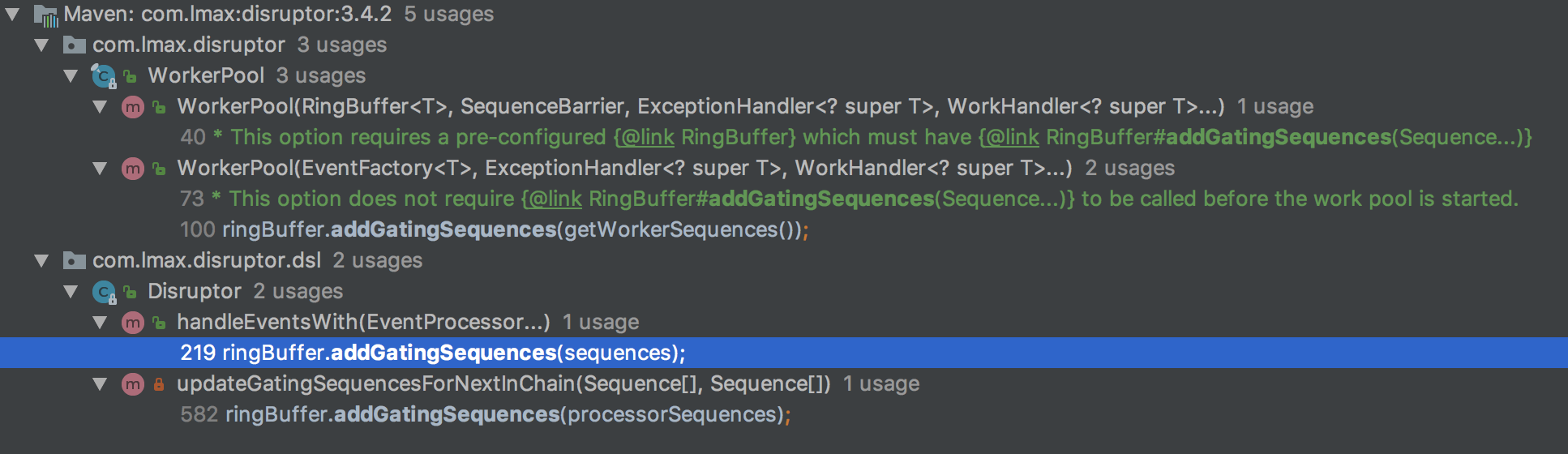
WorkerPool来管理多个消费者;hangdlerEventsWith 这个方法也是用来设置消费者的。但是在上面的测试案例中我们是想通过不设定消费者 只设定生成者 来观察 环形队列的占用情况,所以gatingSequences 会一直是空的,因此在计算时会把 produced 的值作为 minimum 返回。这样每次计算就相当于:
return getBufferSize() - (produced - produced) === getBufferSize();
也就验证了为何在不设定消费者的情况下,remainingCapacity 的值会一直保持不变。
SOFATracer 中 Disruptor 实践
SOFATracer中,AsyncCommonDigestAppenderManager 对 disruptor 进行了封装,用于处理外部组件的Tracer摘要日志。该部分借助 AsyncCommonDigestAppenderManager 的源码来分析下SOFATracer如何使用disruptor的。
SOFATracer中使用了两种不同的事件模型,一种是SOFATracer内部使用的 StringEvent , 一种是 外部扩展使用的 SofaTacerSpanEvent。这里以 SofaTacerSpanEvent 这种事件模型来分析。StringEvent 消息事件模型对应的是 AsyncCommonAppenderManager 类封装的disruptor。
SofaTracerSpanEvent ( -> LongEvent)
定义消息事件模型,SofaTacerSpanEvent 和 前面 demo 中的 LongEvent 基本结构是一样的,主要是内部持有的消息数据不同,LongEvent 中是一个long类型的数据,SofaTacerSpanEvent中持有的是 SofaTracerSpan 。
public class SofaTracerSpanEvent {
private volatile SofaTracerSpan sofaTracerSpan;
public SofaTracerSpan getSofaTracerSpan() {
return sofaTracerSpan;
}
public void setSofaTracerSpan(SofaTracerSpan sofaTracerSpan) {
this.sofaTracerSpan = sofaTracerSpan;
}
}
Consumer ( -> LongEventHandler)
Consumer 是 AsyncCommonDigestAppenderManager 的内部类;实现了 EventHandler 接口,这个consumer就是作为消费者存在的。
在AsyncCommonAppenderManager中也有一个,这个地方个人觉得可以抽出去,这样可以使得AsyncCommonDigestAppenderManager/AsyncCommonAppenderManager的代码看起来更干净;
private class Consumer implements EventHandler<SofaTracerSpanEvent> {
//日志类型集合,非该集合内的日志类型将不会被处理
protected Set<String> logTypes = Collections.synchronizedSet(new HashSet<String>());
@Override
public void onEvent(SofaTracerSpanEvent event, long sequence, boolean endOfBatch)
throws Exception {
// 拿到具体的消息数据 sofaTracerSpan
SofaTracerSpan sofaTracerSpan = event.getSofaTracerSpan();
// 如果没有数据,则不做任何处理
if (sofaTracerSpan != null) {
try {
String logType = sofaTracerSpan.getLogType();
// 验证当前日志类型是否可以被当前consumer消费
if (logTypes.contains(logType)) {
// 获取编码类型
SpanEncoder encoder = contextEncoders.get(logType);
//获取 appender
TraceAppender appender = appenders.get(logType);
// 对数据进行编码处理
String encodedStr = encoder.encode(sofaTracerSpan);
if (appender instanceof LoadTestAwareAppender) {
((LoadTestAwareAppender) appender).append(encodedStr,
TracerUtils.isLoadTest(sofaTracerSpan));
} else {
appender.append(encodedStr);
}
// 刷新缓冲区,日志输出
appender.flush();
}
} catch (Exception e) {
// 异常省略
}
}
}
public void addLogType(String logType) {
logTypes.add(logType);
}
}
SofaTracerSpanEventFactory (-> LongEventFactory)
用于产生消息事件的 Factory
public class SofaTracerSpanEventFactory implements EventFactory<SofaTracerSpanEvent> {
@Override
public SofaTracerSpanEvent newInstance() {
return new SofaTracerSpanEvent();
}
}
ConsumerThreadFactory (-> LongEventThreadFactory )
用来产生消费线程的 Factory。
public class ConsumerThreadFactory implements ThreadFactory {
private String workName;
public String getWorkName() {
return workName;
}
public void setWorkName(String workName) {
this.workName = workName;
}
@Override
public Thread newThread(Runnable runnable) {
Thread worker = new Thread(runnable, "Tracer-AsyncConsumer-Thread-" + workName);
worker.setDaemon(true);
return worker;
}
}
构建disruptor
disruptor 的构建是在 AsyncCommonDigestAppenderManager 的构造函数中完成的。
public AsyncCommonDigestAppenderManager(int queueSize, int consumerNumber) {
// 使用这个计算来保证realQueueSize是2的次幂(返回当前 大于等于queueSize的最小的2的次幂数 )
int realQueueSize = 1 << (32 - Integer.numberOfLeadingZeros(queueSize - 1));
//构建disruptor,使用的是 ProducerType.MULTI
//等待策略是 BlockingWaitStrategy
disruptor = new Disruptor<SofaTracerSpanEvent>(new SofaTracerSpanEventFactory(),
realQueueSize, threadFactory, ProducerType.MULTI, new BlockingWaitStrategy());
//消费者列表
this.consumers = new ArrayList<Consumer>(consumerNumber);
for (int i = 0; i < consumerNumber; i++) {
Consumer consumer = new Consumer();
consumers.add(consumer);
//设置异常处理程序
disruptor.setDefaultExceptionHandler(new ConsumerExceptionHandler());
//绑定消费者
disruptor.handleEventsWith(consumer);
}
//是否允许丢弃,从配置文件获取
this.allowDiscard = Boolean.parseBoolean(SofaTracerConfiguration.getProperty(
SofaTracerConfiguration.TRACER_ASYNC_APPENDER_ALLOW_DISCARD, DEFAULT_ALLOW_DISCARD));
if (allowDiscard) {
//是否记录丢失日志的数量
this.isOutDiscardNumber = Boolean.parseBoolean(SofaTracerConfiguration.getProperty(
SofaTracerConfiguration.TRACER_ASYNC_APPENDER_IS_OUT_DISCARD_NUMBER,
DEFAULT_IS_OUT_DISCARD_NUMBER));
//是否记录丢失日志的TraceId和RpcId
this.isOutDiscardId = Boolean.parseBoolean(SofaTracerConfiguration.getProperty(
SofaTracerConfiguration.TRACER_ASYNC_APPENDER_IS_OUT_DISCARD_ID,
DEFAULT_IS_OUT_DISCARD_ID));
//丢失日志的数量达到该阈值进行一次日志输出
this.discardOutThreshold = Long.parseLong(SofaTracerConfiguration.getProperty(
SofaTracerConfiguration.TRACER_ASYNC_APPENDER_DISCARD_OUT_THRESHOLD,
DEFAULT_DISCARD_OUT_THRESHOLD));
if (isOutDiscardNumber) {
this.discardCount = new PaddedAtomicLong(0L);
}
}
}
启动 disruptor
disruptor的启动委托给了AsyncCommonDigestAppenderManager 的start方法来执行。
public void start(final String workerName) {
this.threadFactory.setWorkName(workerName);
this.ringBuffer = this.disruptor.start();
}
来看下,SOFATracer 中 具体是在哪里调用这个start 的:
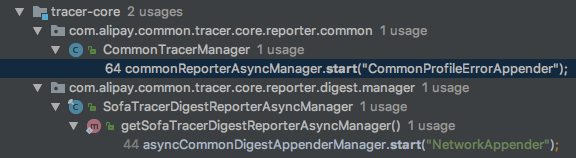
CommonTracerManager: 这个里面持有了AsyncCommonDigestAppenderManager类的一个单例对象,并且是static静态代码块中调用了start方法;这个用来输出普通日志。SofaTracerDigestReporterAsyncManager:这里类里面也是持有了AsyncCommonDigestAppenderManager类的一个单例对像,并且提供了getSofaTracerDigestReporterAsyncManager方法来获取该单例,在这个方法中调用了start方法;该对象用来输出摘要日志。
发布事件
前面的demo中是通过一个for循环来发布事件的,在 SOFATracer 中 的事件发布无非就是当有Tracer日志需要输出时会触发发布,那么对应的就是日志的 append 操作,将日志 append 到环形缓冲区。
public boolean append(SofaTracerSpan sofaTracerSpan) {
long sequence = 0L;
//是否允许丢弃
if (allowDiscard) {
try {
//允许丢弃就使用tryNext尝试申请序列,申请不到抛出异常
sequence = ringBuffer.tryNext();
} catch (InsufficientCapacityException e) {
//是否输出丢失日志的TraceId和RpcId
if (isOutDiscardId) {
SofaTracerSpanContext sofaTracerSpanContext = sofaTracerSpan
.getSofaTracerSpanContext();
if (sofaTracerSpanContext != null) {
SynchronizingSelfLog.warn("discarded tracer: traceId["
+ sofaTracerSpanContext.getTraceId()
+ "];spanId[" + sofaTracerSpanContext.getSpanId()
+ "]");
}
}
//是否输出丢失日志的数量
if ((isOutDiscardNumber) && discardCount.incrementAndGet() == discardOutThreshold) {
discardCount.set(0);
if (isOutDiscardNumber) {
SynchronizingSelfLog.warn("discarded " + discardOutThreshold + " logs");
}
}
return false;
}
} else {
// 不允许丢弃则使用next方法
sequence = ringBuffer.next();
}
try {
SofaTracerSpanEvent event = ringBuffer.get(sequence);
event.setSofaTracerSpan(sofaTracerSpan);
} catch (Exception e) {
SynchronizingSelfLog.error("fail to add event");
return false;
}
//发布
ringBuffer.publish(sequence);
return true;
}
SOFATracer 事件发布的调用逻辑:
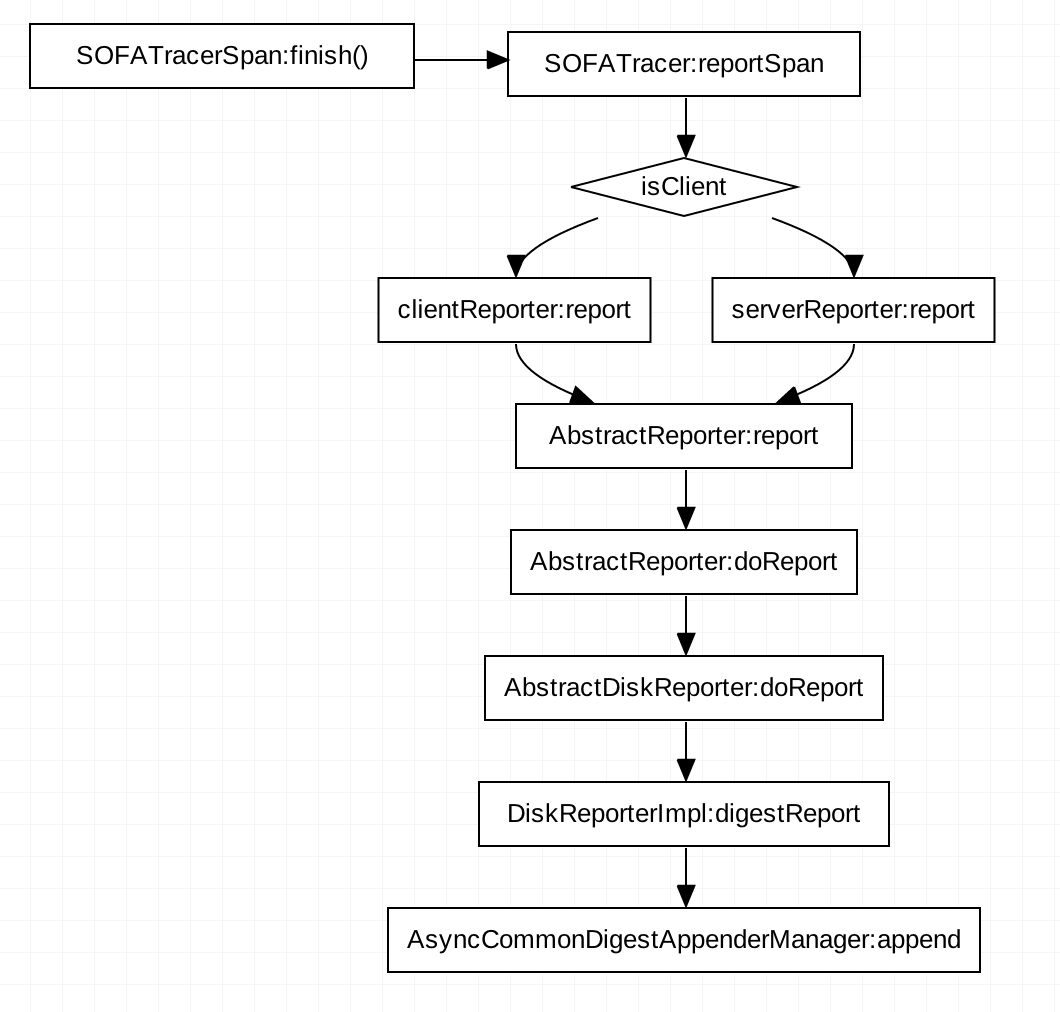
追溯调用的流程,可以知道当前 span 调用 finish时或者 SOFATracer中调用reportSpan时 就相当于发布了一个消息事件。
小结
本文对 SOFATracer 中使用 Disruptor 来进行日志输出的代码进行了简单的分析,更多内部细节原理可以自行看下SOFATracer的代码。SOFATracer 作为一种比较底层的中间件组件,在实际的业务开发中基本是无法感知的。但是作为技术来学习,还是有很多点可以挖一挖。
如果有小伙伴对中间件感兴趣,欢迎加入我们团队,欢迎来撩;对 SOFA 技术体系有兴趣的可以关注我们 ALIPAY SOFA 社区;附团队镇楼图。

