

本篇文章超长,慎入。
本文我们讨论的是:
如何评价一个字段,一个特征,一个数据源,一个模型的有效性。
这个问题比建模本身要简单一点,所以受众会广一点,毕竟用模型的人比做模型的人还是要多不少的。但又不像大家想的那么简单.
我们可以把这个问题分为两部分:
1. 如何在数学上评价两个变量的关系?
2. 假设其中一个变量是我们定义好的因变量,那这个关系要近到什么程度,才能够产生经济效益?
以下是我总结的一些常用分析方法(如有遗留欢迎大家补充)。
Bivariate Analysis
在讨论bivariate analysis 之前,需要提一下univaiate analysis,单变量分析,也就是俗称的“单身狗分析”。它也许是统计分析中最简单的一种形式。
而bivariate analysis,二元变量分析,用来讨论两个变量之间的相互关系。
这两个变量,可以是一个因变量,一个自变量(特征,评分等等),也可以是两个自变量。为了把本篇的立意提高一个档次,我可以这样说:
univaiate analysis是bivariate analysis的基础;
bivariate analysis是所有learing的基础。
做过模型的或用过模型的都知道,风险模型其实就是一种典型的supervised learning。
supervised learning
(百度百科)是一个机器学习中的技巧,可以由训练资料中学到或建立一个模式(函数 / learning model),并依此模式推测新的instances。训练资料是由输入物件(通常是向量)和预期输出所组成。函数的输出可以是一个连续的值(称为回归分析),或是预测一个分类标签(称作分类)。
用大白话说就是,有明确目标的学习,比如要学到什么样的客户是坏客户、就是想先实现一个亿的小目标、就是想打通关;与之相对的是unsupervised learning,我漫无目标的学,因为我也不知道我要什么样的,就像现在好多人谈恋爱,最早也不知道自己喜欢什么样的,那只好见一个爱一个,慢慢的才能把自己的口味试出来,毕竟每个人的口味不一样。
那肯定有人问了,这种漫无目标的尝试和学习,有什么意义呢?会不会反倒是资源的浪费?
其实不是,不管是社会、某个行业、亦或者是某种语言,保持多样性是非常重要,放弃多样性就意味着放弃可能性。回到我们的话题,我之前提到风险模型其实就是一种典型的supervised learning,这句话不完全对,因为在建立风险模型的过程中,有一个关键的步骤叫做“特征工程characteristic engineering”,狭义的特征工程也叫做特征提取,就是找到那些可能作为模型自变量的这个步骤,这个步骤其实就是unsupervised learning,最理想的就是穷尽各种可能性来代表用户某一方面的特征。
可以度量的风险(不仅仅是风险因变量),可能出现四种类型:
连续型变量(continuous variable)
序数型变量(ordinal variable)
二元型变量(binary variable)
无序列表型变量(nominal variable)
同因变量一样,我们在这个领域中遇到的几乎所有(again,就是这么严谨)二元分析能够遇到的变量也都是属于上述四种类型,我们后面会分别讨论这四种变量在做二元分析时的这10对两两关系一般都是如何处理的。
变量和特征
先来说变量,变量是一个可以变化数值的量化指标,比如所有申请人的年龄。因为每个申请人的年龄有各种各样的可能性,那么这个变量就实际上是“随机变量”。随机变量是一个统计学中的概念,指我们把现实中一件事可能发生的结果和实数的集合做了一个1-1的对应关系,专业人士中的变量,本质上是一个函数或一个关系,而不是一个数。举个例子,性别是男女,这不叫变量,你把男女映射成1/0,才是变量。
这里要引入另外一个概念,“事件”。除了像年龄,性别这样的属性,其他大部分的用户行为都是一个事件,如某年某月我借了一笔钱,某天我给120打了电话,某天我上了一个赌博网站。但在风险模型和规则中,一般是不会直接使用这些事件作为变量和特征的。用数学的语言来描述的话,就是在风险模型和规则中可以使用的变量和特征,是所有用户事件集合的σ代数(σ-algebra)
用直白的语言来描述,就是穷尽所有的事件组合,所构成的集合才是最完美的特征集合。在绝大多数金融场景中,原始的客户事件数据都是存储在一个带时间标记的二维表中,这种数据我们称其为面板数据(panel data),在一般情况下我们得到的特征集合,其实都是基本事件的σ代数的子集。同时,在将面板数据(panel data)转化为可供模型使用的宽表(flat file/flat data)的过程,我们称为特征提取。
二元分析的主要目的
因变量-自变量:这里的自变量可以是一个特征,或是一个评分,既可以来自于内部,也可能是一个外部的数据源,由于因变量的存在,此时我们既可以用同一套指标和标准来评估不同的自变量,来给出自变量显著性的排序;也可以用不用的指标,来研究同一对变量之间关系。
自变量-自变量:这种分析即会应用在建模的流程中,来进行降维或诊断模型的有效性;也可以用来分析不同数据的重叠度,主要应用在外部数据评估和模型部署的场景下。
离散化
离散化,就是我们前文提到的变量分组;通常我们的离散化,就是通过分区间的手段,把连续型变量,变为序数型变量。比如,我们把精确的逾期天数,划分成M1,M2,M3等;把一天24小时分为凌晨,上午,下午,夜间等等。
像小时,分钟,月份,星期几这种变量,看似它和实际的连续型变量差不多,但跟正常的连续型变量有一个很大的区别,这种变量的值是头尾相接的,比如,周日后面是周一,而不是周八,12月后面是1月而不是13月。这类特殊的连续型变量在统计学中称为Circular distribution,是有着特殊的处理方法的,我们在一些特定的场景下需要注意。
虚拟化
虚拟化,是指通过虚拟化技术将一台计算机虚拟为多台逻辑计算机。在一台计算机上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统,并且应用程序都可以在相互独立的空间内运行而互不影响,从而显著提高计算机的工作效率。虚拟化使用软件的方法重新定义划分IT资源,可以实现IT资源的动态分配、灵活调度、跨域共享,提高IT资源利用率,使IT资源能够真正成为社会基础设施,服务于各行各业中灵活多变的应用需求。
我们的虚拟化,跟计算机里的虚拟化,完全不是一回事。这里的虚拟化,指的是把连续型或序数型或无序列表型变量转化为二元变量的过程,这类二元变量有个特定名称,叫做虚拟变量(dummy variable)。比如说,我们把逾期表现定义为,M2+和else;把星期几变成weekday和weekend等等。
虚拟化和离散化的主要作用是将连续型的随机变量转变为离散的变量,使得连续型的随机变量能够使用那些针对离散型变量的评估方法,另外在做一些传统的线性回归或逻辑回归时,通过虚拟化和离散化能够捕捉到一些非线性的相关关系。
连续型变量的二元相关关系
连续型变量的二元相关关系其实在整个的分析过程中,基本属于不被重视经常被忽略的,主要原因就是在风险模型中大概95%的模型都是二元的因变量。但连续型变量的二元相关关系,发挥的通常都是基础性的作用,所以呢,我把它放在了第一个介绍。
通常情况下,如果两个连续型变量的可以被认定为是有关系的,那么应该会满足下面四种相关关系中的一种,分别是:
线性相关
依分布线性相关
秩相关
其他非线性相关
需要注意的是,这里的四种关系的相关性是逐渐减弱的(相对),而且完全是我自己总结的,甚至连其中两种相关关系的名字都是我现编的,难免有不严谨的地方,因此接受讨论,不接受批评,u can u up。
线性相关
线性相关是我认为最强的相关关系,也就两个变量线性相关的程度。常用的评估线性相关关系的方法有如下三种,
相关系数:相关系数是最早由统计学家卡尔·皮尔逊设计的统计指标,是研究变量之间线性相关程度的量,一般用字母 r 表示。由于研究对象的不同,相关系数有多种定义方式,较为常用的是皮尔逊相关系数。
相关关系是一种非确定性的关系,相关系数是研究变量之间线性相关程度的量。由于研究对象的不同,相关系数有如下几种定义方式。
简单相关系数:又叫相关系数或线性相关系数,一般用字母r 表示,用来度量两个变量间的线性关系。
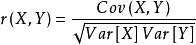
相关系数的主要应用场景是在做一般线性回归或逻辑回归时,诊断自变量之间的多重共线性,在进行变量筛选时应用较少,主要原因是,线性相关是一直比较严格相关关系,用它来做标准会误杀很多变量。
多重共线性(multi-collinearity)
很多受到过比较严格模型训练的同学都知道在做一般线性回归或逻辑回归时都要做多重共线性诊断,但很少有人会去思考为什么,可能只是当年在公司带你的那个人say so。这个事情其实挺滑稽的,当年老罗语录中有个段子叫传统论,我觉得放在这里特别应景(具体请自行百度)。
其实,多重共线性是在做线性回归诊断的时候发明出来的一个名词,指的是自变量之间有比较强的线性相关关系。
对于每一种数学模型,比如线性回归、逻辑回顾等,其实都是有两个要素的,分别是函数形式和参数拟合,对一般线性回归来说,它的这两个要素分别是线性的函数形式和最小二乘估计。
有理论推导可以证明,多重共线性会导致最小二乘估计拟合出来的参数的方差偏大,说人话就是多重共线性会导致最小二乘估计这个方法失效,这其实这是做多重共线性诊断的根本原因。话说回来,它所使用的这个参数拟合方法叫做极大似然估计,也有可能是我孤陋寡闻,一直没看到多重共线性导致极大似然估计失效的相关文献,所以其实都是经验结论,如果有哪位同学有请一定发给我。
R平方(R-square)
R方是典型的用模型指标来进行变量相关性评估的方法之一,跟这个类似还有用LASSO或随机森林给出在一对多的变量评估时,给出变量的相关性。
以R-square为例,此类方案的原理就是将两个(或多个)中的某一个作为因变量,剩余的作为自变量,训练一个模型,用衡量模型的指标来做为衡量变量之间相关关系的指标。
(百度百科)在统计学中对变量进行线行回归分析,采用最小二乘法进行参数估计时,R平方为回归平方和与总离差平方和的比值,表示总离差平方和中可以由回归平方和解释的比例,这一比例越大越好,模型越精确,回归效果越显著。R平方介于0~1之间,越接近1,回归拟合效果越好,一般认为超过0.8的模型拟合优度比较高。
由于R-square取值0~1,而且在最完美的时候是1,在经济统计中,R-square
经常被用作衡量“贡献度”或“解释程度”,比如,用过去30的第三产业产值去回归过去30年的GDP,我们就知道第三产业对于国民生产总值的贡献了。
抽样散点图
用散点图将两个变量点在一个XY的坐标系中,是最直观的反应相关关系的手段,但由于我们都号称自己是做大数据的,数据特别多,所以只好做抽样了,否则图上就全是点,没法看了。
秩相关
秩相关在很多情况下可能大家接触的比较少,秩相关的从直观来理解就是是两个连续型变量的对于样本分别进行排序,排序的结果可能差不多。秩分布相关其实是秩相关的一种特殊情况。
在大多数金融业务的场景下,我们想知道的其实就是秩相关。常见的依相关的例子并不出现在两个连续型随机变量之间,而通常是一个二元的变量和一个连续型的或其他类型的变量。
针对两个连续型随机变量,评估秩相关的主要手段是非参数假设检验。
参数检验和非参数检验
假设检验是数理统计中的一个非常重要的分支,它遵循这样一个朴素的思维方法,即“提出假设->根据假设进行推导->获得结论->接受或推翻假设”。拿大家都知道的死神小学生柯南来举一个例子,他通常的解决一个案件的流程是这样的:
1、在某个时间点,看到线索或听到线索或灵感浮现,他大概知道了谁是凶手。这个过程叫做提出假设。
2、当我认为某人是凶手时,根据这个人的行为特征或作案条件,他会知道,在某个时间地点,会留下一个什么样的痕迹。这就是提出假设检验的统计量。
3、到那个地方去找证据。这个就根据原假设计算相应的统计量。
4、证据找到了,那就说明假设是对了;否则便是假设错了。这就是接受原假设或拒绝原假设,转而接受备择假设。
那非参数检验和参数检验的差别主要就是,参数检验就是我们对连续型随机变量的分布是有一个假设的,如正态分布,指数分布等等,在进行推理和计算的过程中,我们是依据这个前提的,这样做的好处是如果我们前提是对的,那么我们再验证假设的过程中会更准确,但前提如果本身就是错的,那我们的结论可能会错的更离谱;非参数检验就是那些没有前提假设的那些假设前提,好处是我们的推理会更具有普适性,坏处就是可能在具体的情景下,会丧失一定的准确性。
特别需要注意的是,我们这里介绍的是连续型随机变量之间的秩相关.
依分布相关
在解释分布之前,我们先要讲两个概念
分布函数(英文Cumulative DistributionFunction, 简称CDF),是概率统计中重要的函数,正是通过它,可用数学分析的方法来研究随机变量。分布函数是随机变量最重要的概率特征,分布函数可以完整地描述随机变量的统计规律,并且决定随机变量的一切其他概率特征。
统计学中,经验分布函数是与样本经验测度相关的分布函数。该分布函数是在n个数据点中的每一个上都跳跃1 / n的阶梯函数。其在测量变量的任何指定值处的值是小于或等于指定值的测量变量的观测值的数。
(百度百科)经验分布函数是对样本中生成点的累积分布函数的估计。根据Glivenko-Cantelli定理,它以概率1收敛到该基础分布。同时也存在一些结果来量化经验分布函数与潜在的累积分布函数的收敛速度。
分布函数和经验分布函数的差别就有点像某宝卖家版和买家实拍版的差别,分布函数是理论模型,经验分布函数就是实际观察出的模型。在讨论模型表现的时候,大家都知道要看KS,但很少有知道为了计算KS,我们要首先计算经验分布函数。
为了从分布的角度考察他们的相关性,通常的做法是将这两个变量先做“标准化”(也叫“归一化”)处理,原理也很简单,就是对这两变量分别减去自己的均值然后除以方差。在经过这样的处理后,再通过计算KS来判定两个变量依分布相关的程度。所以,我们这里的相关,其实也是在归一化后口径下的依分布相关。
KS(Kolmogorov-Smirnov)统计量
Kolmogorov-Smirnov是比较一个频率分布f(x)与理论分布g(x)或者两个观测值分布的检验方法。其原假设H0:两个数据分布一致或者数据符合理论分布。D=max| f(x)-g(x)|,当实际观测值D>D(n,α)则拒绝H0,否则则接受H0假设。
KS检验与t-检验之类的其他方法不同是KS检验不需要知道数据的分布情况,可以算是一种非参数检验方法。当然这样方便的代价就是当检验的数据分布符合特定的分布事,KS检验的灵敏度没有相应的检验来的高。在样本量比较小的时候,KS检验最为非参数检验在分析两组数据之间是否不同时相当常用。
还有一个与KS相类似的统计量是C统计量,C统计量其实就AUC的马甲。这个我们再介绍AUC的时候会详细介绍。
另外,为了更直观的观测两个连续型变量的依分布相关,可以将两个经验分布函数绘在同一张图上进行比较。
二元变量和连续型变量的关系
二元变量和连续型变量的相关关系是“谨慎的“使用数据驱动的风控模型中的核心技术;同时,这里的连续型变量是泛指所有类型的变量,因为我们之前讲到的所有二元型,连续型,序数型,无序列表型都可以通过分组,离散化,虚拟化等技术手段转化为一个理论上的连续型变量。
为了支撑所谓的“大数据风控”其实需要我们需要将这个特殊的相关关系转化为如下几个范畴的内容:
从数学的角度评估一个二元变量和一个连续型变量
因为从风险管理的角度,我们最关心的就是用户是否逾期,这个就是我们所说的“一个二元变量”。
这里的“连续型“变量可能是一个内部评分,也有可能是一个外部评分,更有可能是某个可以量化的用户特征。我们要做的是用各种数学指标去评估这个变量对逾期是否显著(siginificant),这里的数学指标可能是一堆数据,一个表格,用来深度理解这个二元关系,当然也可能是将这个1-1的关系简化成一个数字,用来进行比较和排序,如我们所熟知的KS,IV等。
通过各种方法生成或找到一个显著的连续型变量
这个就是我们通常所说的狭义的“建模“了,这里要做的主要是三件事
一是从海量的数据中先把这些可能显著的特征提取出来;
二是从那些海量的特征中找到那些可能显著的特征;
三是将可能显著的特征或弱显著特征聚合成一个显著特征(评分)
从业务的角度评估一个二元变量和一个连续型变量的效用
当我们发现了一个从数学上对于逾期显著的变量时,新的任务就是判断这个变量是否适合放入我们的风险规则,以及如何将这个新的评分或者特征放入我们已经存在的规则体系中。如果说上面的两个任务更像是搞科研的话,那么这个任务就是科技成果转化,科研成果只有转化成生产力才能真正为企业带来收益,否则你说资本家银行账户里也没有闲钱啊。

这里主要讨论的是“从数学的角度评估一个二元变量和一个连续型变量”。在我们整个的流程中,可能会用到的评估方法如下:
IV
gini系数
相关系数
entropy
KS
AUC
混淆矩阵指标族
ROC曲线
Lorenz曲线
模型影响力指标族
IV
全称是Information Value,中文意思是信息价值,或者信息量。反应的是单一特征对目标变量的显著性,但由于IV的数值本身没有比较显著的物理意义,因此IV的主要作用就是根据显著性对特征进行排序。
需要注意的是,由于在各种指标下每个特征的排序可能不会完全一致,而且由于目前尚无严格的理论证明各种指标的最优适用范围,因此使用多个指标对特征进行排序,然后取并集,是我们在筛选特征时常用的手段,避免漏掉一些特征,影响模型表现。
IV的主要计算手段就是跟据特征的不同取值分组,然后在每个分组中计算子IV,然后将每个组中的子IV求和,每个分组中的子IV计算公式如下:
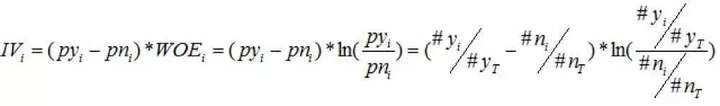
从直观上去理解,每个子IV有如下特征:
子IV总是大于等于零的;
当该分组中好坏的比例与总体好坏的比例相同时,则子IV为0;
当该分组中好坏的比例与总体好坏的比例偏离越大,则子IV越大;
那么将所有子IV相加以后的特征IV越大,也就意味着这个特征的不同取值从总体来说对好坏的区分越大。
一般人对于IV的认知也就到此了,但是为了显示出张老师还是肚子里还是有点墨水,也不总是搬运工和抖机灵,下面我们真对IV来做一些深入的探讨。
IV的计算是取决于分组的方式的,不同的分组方式所计算出的IV是会有一些怎样的差异?
IV是由各个分组的子IV求和来的,那么IV必然就会有一些由求和代来的特性,那么一个偏科分子和各门功课都还行的同学,谁会在计算IV的时候占优势?
接着,在如果我用子IV的平均数或者中位数来代替子IV求和,设计出IV改1和IV改2,那么用这两个新指标计算出来的IV,在特征显著性筛选方面会有什么异同?或者说为什么我们不用IV改1或IV改2来计算IV?
我们是否可以通过对那些有足够支撑的子IV的排序,找到特别有区分能力的特征的取值?这么做是否有意义?
GINI
Gini系数我们更多的是从新闻里听到评价一个国家收入差距的指标,但gini系数的算法,其实也是一种用来判别特征对于目标变量显著程度的指标,只不过gini系数在一般变量评估及传统的建模流程中不常用,但gini系数是一种叫做CART(classification and regression tree)的决策树算法,对于离散型目标变量进行分叉时的主要依据,而CART正是大名鼎鼎的GBDT所使用的决策树。
其实像gini数据一样,很多经典的统计指标和方法在早期都是被生物学家、人口学家、经济学家所发明的,正是因为生物学、人口学、经济学是那个时代的“大数据”啊。
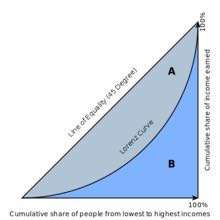
赫希曼根据洛伦茨曲线提出的判断分配平等程度的指标。设实际收入分配曲线和收入分配绝对平等曲线之间的面积为A,实际收入分配曲线右下方的面积为B。并以A除以(A+B)的商表示不平等程度。这个数值被称为基尼系数或称洛伦茨系数。如果A为零,基尼系数为零,表示收入分配完全平等;如果B为零则系数为1,收入分配绝对不平等。收入分配越是趋向平等,洛伦茨曲线的弧度越小,基尼系数也越小,反之,收入分配越是趋向不平等,洛伦茨曲线的弧度越大,那么基尼系数也越大。另外,可以参看帕累托指数(是指对收入分布不均衡的程度的度量)。
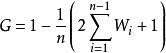
这个数值计算方法,是我们在实践中通常用的方法,类似于我们用经验分布函数来代替分布函数,用以计算KS。
为了让大家更好的理解基尼系数,我们来看几个数字;
(百度百科)中国国家统计局基尼公布基尼系数2012年为0.474,2013年为0.473,2014年为0.469,2015年为0.462,2016年为0.465,根据西南财经大学教授甘犁主持,西南财经大学中国家庭金融调研中心发布统计报告称2010年为0.61。
在现实中,日本是全球基尼系数最低的国家之一。据共同社2013年10月11日报道,日本厚生劳动省周五公布的2011年调查报告显示,日本国内基尼系数为0.2708,创历史新高。据报道,自1984年以来,日本的基尼系数持续上升,此次调查为0.2708,较2008年的数据增加0.0218,创历史新高。厚劳省认为,收入较低的老年人及单身者家庭的增加导致差距扩大。据悉,基尼系数是国际上用来综合考察一国或地区居民内部收入分配差异状况的一个重要分析指标,基尼系数越接近1就表示收入分配差距越大。在日本,基尼系数的调查每三年左右实施一次,此次是第16次。日本的基尼系数一般在0.25左右,德国为0.3左右,而美国的基尼系数已经超过0.4的警戒线。
我不评价这些数字的准确性,只是做了一些实验,告诉大家GINI系数分别是0.61,0.45,0.27的时候收入的差距到底是怎么样的?
我取100个人,一共让他们赚5500快,那么收入有如下三种分配方式:
1. 100个人的收入是从1一直到100,是不是感觉差距已经很明显了,如果放在现实社会中,收入最高的1%已经是收入最低的1%的人收入的100倍了,但其实这100个人的gini系数只有0.33,而日本只有0.27;
2. 100个人中,最富有的一个人挣了2700,剩下的99个人一共挣了2800块,平均一个人差不多28块。这种情况下,这个整体的GINI系数是0.48;
3. 100个人中,最富有的一个人挣了3500,剩下的99个人一种才挣了2700块,平均一个人也就20块。这种情况下,这个整体的GINI系数是0.63.
其实从上面的例子可以看到,决定GINI系数或收入差距的并不是最富有的人比最穷的人高了多少倍,即使在最后一个例子,也就不到200倍;决定GINI系数或是收入差距的是,最富有的人占有的社会的总财富的比例,而在这三个例子里面,分别是不到2%,50%和差不多64%。尤其是第三个例子,最富有的1%占有了总收入的64%,这个还是挺夸张的,这已经不是2:8法则了吧。
Entropy(熵)
Entropy这个指标在我们做模型的时候用的的确不多,但在决策树中,这个指标代表了一类非常重要的分类或叫做分叉思想,也就是通过分叉(根据某个指标的阈值将总体分成几个子集)降低整体人群的混乱度。从ID3开始,C4.5以及之后的演化版本,用的都是它。
Entropy其实就是我们在中学化学课本中学过的熵,所有的化学反应,其实都是由纯净到混乱的过程,过程中释放能量,整个系统的熵(混乱度)在增加。
我们这里的熵其实准确的叫法就是信息熵,在我们提取信息的过程中,是信息熵在不断的减小。举个简单的例子,当我们把50个白球和50个黑球混在起后,这个时候看起来是很乱的,对于这个简单的系统,此时的熵是很大的;当我们手工挑10个白球出来,放成另一堆后,这时新的两堆球的熵的和是小于之前的一大堆球的。
来看一下信息熵的计算公式
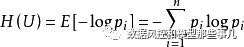
这个公式其实看起来跟我们之前讲过的IV的公式是有点像的,下面我们就通过IV和信息熵的对比,来更好的理解一下信息熵:
IV是信息量,那么其实信息量越大,包含的信息越多;而信息熵则相反,熵越小包含的信息量越大,这个应该是非常好理解的。
跟IV相比,entropy有一个非常重要的特性,就是可加性。也就是说,当我把人群分成两部分以后新的系统的整体entropy就等于两个子集的entropy之和,但IV却不具有这个性质,根据IV的公式,新的系统IV是跟原来一样的,那么我们就没有办法通过IV的变化来判定使用这个指标后的效果。从这个意义上说,IV是一个先验的总体指标,主要用来做横向比较,也就是说IV能带给我们的信息是,这个指标比那个指标有用;但entropy其实是一个阈值敏感的结果指,也就是说,entropy能告诉我,当我用了某个指标,且指定了分类阈值后,样本的熵将会下降多少,用个学术名词,这个就叫做“信息增益”。对于熟悉一般逻辑回归建模流程和决策树分叉流程的同学看到这里应该就明白了,为什么在这两个场景下,我们会分别用IV和entropy了。
混淆矩阵指标族
今天我们要讨论的话题是混淆矩阵指标族(confusion matrix),之所以叫指标族,是因为有很多指标都是由混淆矩阵计算而来的。
要注意的是,在这里我们讲一个二分类变量和连续型变量(模型平台)的相关关系,因此为了计算模型评分对于坏客户(二分类)的混淆矩阵,我们要做的第一步就是找到一个阈值把这个连续的可以用来排序的指标转化为一个二元指标(这个过程类似与我们之前讲过的虚拟化);随之而来的问题就是,这个阈值怎么找?在几乎所有的分析包中,这个阈值都是根据如下方法来确定的。
第一步,看一下在样本中T和F的比例,这个是真实的坏人和好人的比例;
第二部,通过排序算法从低分到高分(假设低分是坏人),找到那个使P/N=T/F的值,这个值有可能是一个数值或分位数;
第三步,用这个阈值,将评分转化为P和N;
以上这个方法是非常标准的算法,可以广泛应用在各行各业,但是具体我们行业,我觉得用这个办法确定阈值,然后计算相应指标,如召回率之类的,其实不是一个好的衡量模型用的指标,混淆矩阵指标族,多用在分析模型对整体策略的影响时使用,而不是用在比较模型的好坏。
介绍完基本概念,我们开始进入正题。
当我们样本打好TF和PN的标记后,我们可以将整个样本分为四种类型:
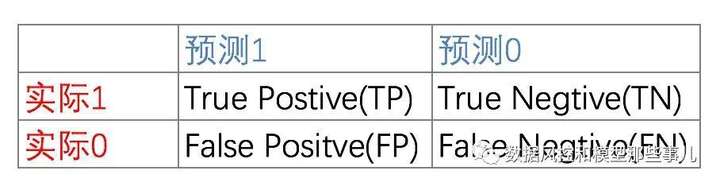
这四种类型有两种类型我们的判断是对的,一个可以赚钱,一个可以防止损失;另外两种状态我们判断错了,一个浪费本金,一个浪费营销费用。
因此,从混淆矩阵衍生出来的指标一般分两大类,正向指标和反向指标,正向指标就是把TP或FN之一或者之和放在分子,把总数、FP、TN等放在分母,总之正向指标越大,越说明模型好(由于模型的作用主要是将好坏分开,所以在很多统计学或机器学习的相关地方,我们一般称呼为分类器,aka,Classifier);反向指标同理。
类似的指标还有:
False Negative Rate(假负率 , FNR) FNR = FN /(TP + FN);
True Positive Rate(真正率 , TPR)或灵敏度(sensitivity) TPR = TP /(TP + FN)
其实在真正的实际业务中,我们计算与混淆矩阵相关的指标,通常是个循环的过程,即,预先定义一个阈值,根据阈值进行成本核实,计算相应指标,然后调整阈值,重新进行成本核算。知道找到一个能最大满足业务指标的阈值。
Lorenz Curve、KS、ROC Curve、AUC
即使是同一个模型,在我们计算混淆矩阵的相关指标时,如果阈值取的不同,结果也都是不一样的。本篇要讲的四个概念就是将混淆矩阵这个依赖于阈值的指标,转化为了两张图和两个全局指标。全局指标最大的好处就是可以脱离开应用场景,单独使用,因此特别适合模型比较和评估;但反过来说,这些指标也特别容易将建模人员引入歧途,为了指标而建模,忘记了具体业务和应用场景。
KS(Kolmogorov-Smirnov)统计量
Kolmogorov-Smirnov是比较一个频率分布f(x)与理论分布g(x)或者两个观测值分布的检验方法。其原假设H0:两个数据分布一致或者数据符合理论分布。D=max| f(x)-g(x)|,当实际观测值D>D(n,α)则拒绝H0,否则则接受H0假设。
KS检验与t-检验之类的其他方法不同是KS检验不需要知道数据的分布情况,可以算是一种非参数检验方法。
通常在计算KS的时候是这么做的,在样本量足够的时候,我们会按照评分将样本根据评分结果排序后,分为20等分,然后计算下面这个表格。
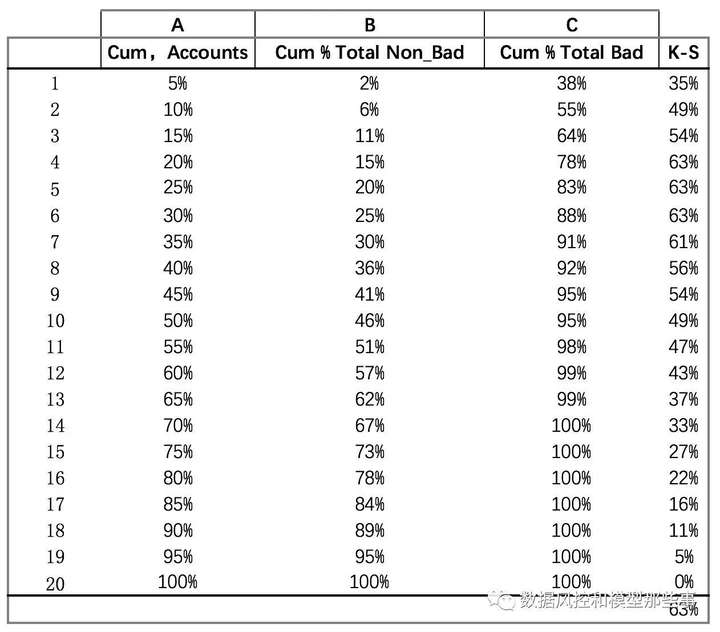
我们将A和C两列画在一张图中,就形成了如下图所示的Lorenz Curve。其中A是横轴,C是纵轴。
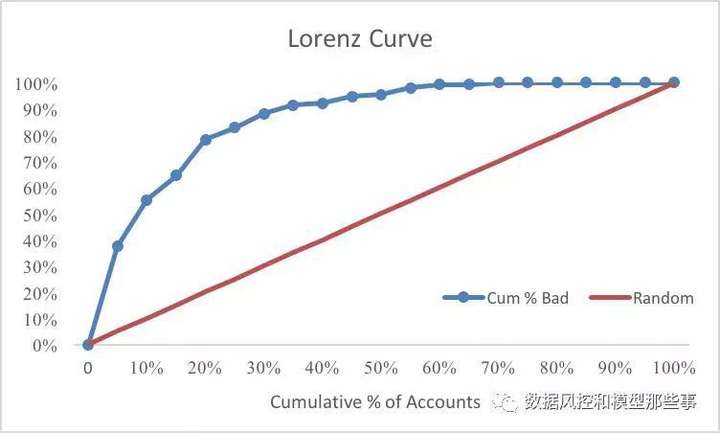
其实B跟C在统计学中有个专有名词,也就是我们前文讲过的“经验分布函数”,那个这两个分布函数背后的随机变量是什么呢?
分别是Bad Accounts的评分和Good Accounts的评分,KS定义中的D=max| f(x)-g(x)|,f(x)和g(x)就是指的这两个随机变量的分布函数。
为了把这个过程更加形象化(如下两张图)。第二张图的那个绿色的线就是两个函数差的变化趋势,以及差对应的最大值63%。我们这里采用的是数值计算方法,因此的同样的样本和模型,在计算方法不同时,会有微小的不同。
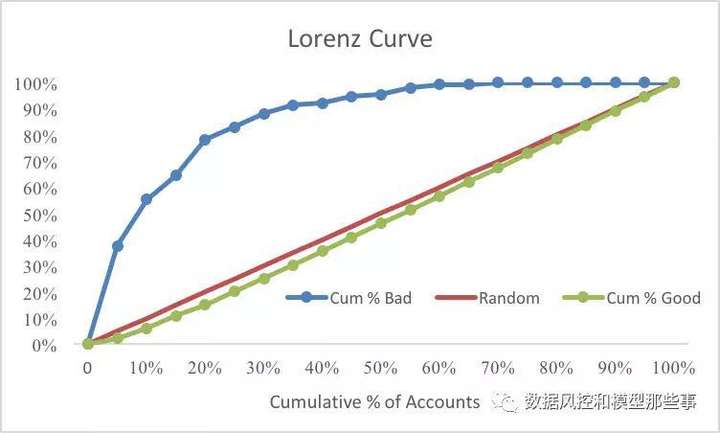
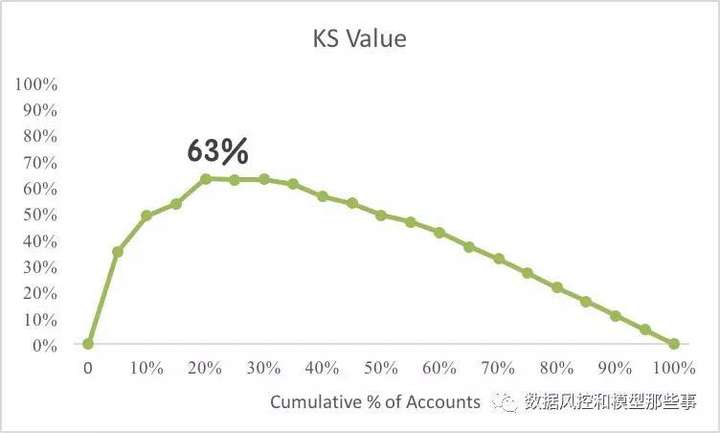
有了Lorenz曲线,我们就知道,当用模型拒绝X%的人时,可以拒绝掉Y%的坏人,而这个正是我们上文讲过的TPR,也就是说Lorenz Curve其实就是把TPR随不用阈值的变化过程动态的展示给我们,而KS其实也可以理解成max|TPR-FNR|。需要注意的是,KS出现的位置,并不一定是我们应用模型时的阈值,也就是说KS高的模型,不是一定能带给我们更好风险规则结果。反过来说,在我们选择模型时,还是要根据我们具体的应用规则来选择,不能机械的使用KS。
当我们把Lorenz Curve的横轴换成B列(也就是FPR),那么LorenZ Curve 就变成ROC Curve了(有时横纵坐标会互换)。
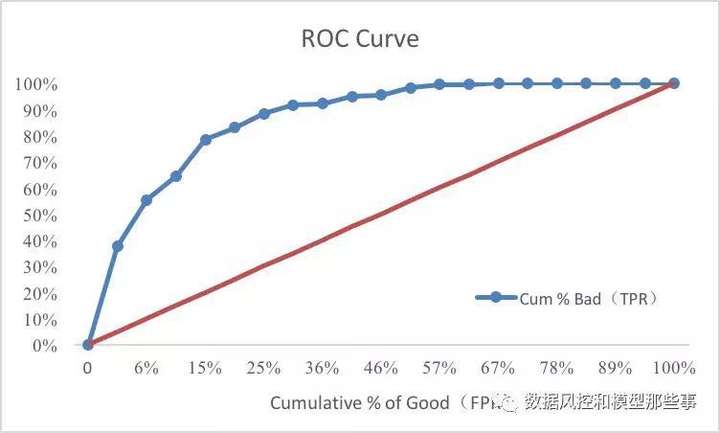
AUC(Area under the Curveof ROC),顾名思义就是那个曲线下的面积了。但AUC是个面积,因此学过高数的同学都知道,要计算这种曲线的面积要用到积分,也就是我们用切片的方法去逼近这个积分,这种计算的运算复杂度是很高的。这个问题先放在这里,我们讲另外一个概念。
用SAS 做过Logistic Regression的同学一定对下图不陌生:
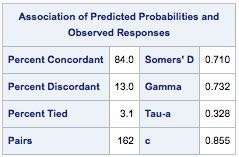
右边是一列统计量,可以先不理会,我们说左边。如果说我们的样本里有M个Bad,N个Good,那个我们会有M*N的比较对,在我们有了模型评分(风险越高评分越高)以后,就会有如下三种情况:
评分和M、N的结果一致,M中的记录对用的评分高于N中记录对应的评分(Concordant);
评分和M、N的结果不一致(Discordant);
M、N对应的评分相等(Tie)
这三种Pair加起来正好是100%的M*N,所以表格中的84,13,3.1就是这个意思(四舍五入过)。而右下角的C统计量就等于
% of Concordant+0.5 * % of Tie
计算C统计量的算法复杂度是比计算AUC的复杂度要低,巧的是C统计量恰好就等于AUC,因此通常用计算C的方法来计算AUC。
关于为什么C=AUC我们这里就不详细证明了,但是大家可以直观理解一下,ROC曲线将这面积为1的区域分为了两部分,在曲线下面的每一个点,其实就是对应了Concordant的情况和一半的Tie。
这种将数论(C统计量的研究领域)和解析几何(ROC的研究领域)相结合解决数学问题的例子在数学史上比比皆是,远到费马大定理的证明,近到现在的区块链中应用的加密算法,深刻着影响着我们的生活。
这个评分到底该不该用?
不管是引入一个外部评分还企业内部研发了一个新的内部评分,基于这个新评分制定相应的策略、再到新策略的上线是一个非常漫长、复杂和涉及多部门协作的事情。但是做为一个一线的模型人员或者数据测试人员来说,后面这个过程的变数很大的、时间和人力成本都很高,不可能每评估一个模型都把全流程走一遍;从另一个方面,如前面一直强调的,那些数学指标更多的是参考价值,毕竟数学和业务中间还是有一段距离。那么,是否有什么简易的方法能够相对合理,又比较快速的评估模型的效能是非常重要的。我下面会分别介绍一个速算评估法和一个完整全面的评估流程。前一个适合新业务和快速评估,后者更适合一个成熟的公司,对于一些相对重大调整的评估流程。
速算评估法
速算评估法其实就是参照如下这个公式:

这个公式的核心原理是用降低的坏账去抵消获客成本的提升,然后用一个经验值来估计模型的生命周期,从而推断出模型的潜在价值。里面一堆字母大家可能看的比较晕,下面来逐一解释。另外呢,这个公式完全是作者原创总结的,但不排除由于孤陋寡闻别人写了,作者没看到过,欢迎大家讨论。同时这个公式中涉及的参数,每一个风险部门的同学至少应该对于本公司的相应数据应该是有所了解的。
CPA(Cost Per Acquisition)
这个是就是单一申请人的获客成本。e.g. 现在大部分的线上贷款平台的获客成本都是按照CPA来计费的,差不多从几块到十几块都有,但是这个CPA其实在大多数情况下指的是注册,而从注册到完成申请大概的漏斗率是70-80%(一般情况,个体差别很大),因此这个公式里的CPA其实是:注册CPA/申请完成漏斗率。
AR(Approve Rate)& AR0
AR也就是目前的审批通过率,而AR0是一个新的通过率,这个通过率是我们在应用了新模型后的通过率,大家不用担心这个新的通过率应该如果确定,因为根据公式,我们要把在一个小范围内所有通过率的采样点都要算一下。
ARl & ARu (l :lower bound,u:upper bound)
这个就是上面说的通过率的范围,根据企业的经营策略总有一个可以容忍的通过率的上下限。上面说到的AR0,其实就是要在这两个数之间,用一定的步长来遍历所有可能的通过率。
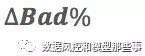
这个就是在AR0通过率下的TN/(TN+FN)和在AR通过率下TN/(TN+FN)的差,这数可正可负。
此处需要注意的是,这里没有考虑模型中Y的具体定义,如果Y是一个比较深度的逾期则问题不大,如果说Y是早期逾期(early delinquent),则要稍微考虑一下用roll rate做调整,如果不做调整的话,可能会under-estimate模型的正面影响。
AC(Average Credit)
平均放款额度。平均的放款额度*逾期率的差,也就在新模型和阈值体系下,能够减少的损失。
CD(Cost of Data) & HR (Hit rate)
CD就是购买外部数据的费用,或由于模型中额外引入了需要付费的数据而产生的成本。这个成本是在审批时产生的,因此要考虑通过率的放大作用,如果是纯内部数据或未引进新的数据,此项费用为0;HR是在我们引入外部模型时才会生效,因为外部的模型是有查得率问题的,当查得率过低时,会影响我们工作的产出。
MA (Monthly Applicants) & LPW (Length of Performance Window)
MA是用来估计我们模型每个月能够生效的人群,而LPW纯粹是根据我的经验,来根据模型Y值的表现窗来确定一个模型能够有效,稳定的时间,e.g. Y=1 是6个月内曾经60DPD or worse,那么这个模型比较有效实际用时间也就6个月左右。一般最小1个月,最长12个月。对于外部的评分,经验值是大厂6-12,小厂3-6。
在评估一个外部评分,或比较若干个模型的时候,个人感觉用这个速算公式的计算公式的结果来比较,会比单纯的比较模型数学指标,要更适合“风控审批”这个业务场景。而且这个计算过程看似复杂,其实是非常适合用计算机代码来实现的,方便的时候,我会适时公布这个计算这个公式的python代码。
综合评估流程
一个相对来说完整流程一般来说包括如下三个大的模块:
预评估;
测试评估;
运营监控
预评估:
预评估阶段的主要任务是通过历史数据的分析、数据测试(如果引入外部测试数据)对新的模型(数据字段)、策略进行预先的评估,这个阶段完全是由分析师在线下完成的,不涉及到任何的生产环境。这个模块主要按照顺讯完成以下几项工作。
对数据进行测试
现在所有的金融机构在测试外部机构的数据测试的时候都会做外部测试但是大家做外部测试的方法却都不太一样,个人以为做数据测试时主要要考察如下两方面:
真实性测试。
也就是说我们要准备一些样本,我们是能够完全了解真实情况的人(一般是内部员工,当然这个要做好隐私保护和沟通),因此这个样本不会太多,但是这个测试能给我们一个对数据直观的了解;
回溯测试。做回溯测试的主要目的是要拿有足够还款表现的账户作为测试样本,要求数据提供方将数据回溯到样本真实的申请时间去匹配数据。回溯的重要性我就不过多强调了,很多公司提供的评分或黑名单产品由于在测试时没有回溯,或仅仅是号称回溯却没有回溯,在测试时可以得到很高的KS,但是将模型或评分应用到真实的业务中时却差强人意。如果说是一个新的内部评分,我们也一定要将这个新的评分,放到一个有足够还款表现的样本上,用当时的数据进行打分,这个过程就叫做Backward。
我们为什么一定要回溯。
不管是做策略分析,还是做评分模型,都有一个假设和一个前提。
一个假设:用户行为在时间维度上是保持相对稳定的。这个假设保证了用历史数据做分析得到的结论在我们应用策略和模型时还能适用。
一个前提:在应用策略和模型时,都是在用截止到应用时间点能够获得的所有信息。在这个时候是无法得知关于未来任何确定的信息的。所以我们需要研究的是“历史加现状和未来的关系”。
从上面的假设和前提,就知道在做分析、数据测试时,就是要保证这个前提。通常我们测试的时候都会取那些已知还款表现的样本,比如,这些样本都是在2017年1月通过测试的。如果在测试和分析的时候,我们不把2017年2月之后的数据剔除掉,那么我们通过分析的到的结论其实是“未来和未来关系”,而不是符合应用场景的“历史加现状和未来的关系”。
通常呢,我们把观察用户表现的那个时间段叫做表现窗,把在审批时用来决定审批结果获取数据的那个时间窗口叫做观察窗,因此有一个推论就是表现窗和观察窗是绝对不能重合的,如果说再做分析提取数据和做测试数据时,不做回溯的话,其实是用表现窗的数据去分析表现窗的数据,这样得到的结论是有很大偏差的。
评估数据效能(如果涉及到新的数据字段或评分)
在这个步骤中,我们根据回溯测试的数据,对数据字段或者评分进行评估。如果不是评分,而是一个数据字段,我们完全可以把这个数据字段看做一个自由度比较低的评分。然后我们就可以直接应用我之前的速算评估公式来进行判断了。
通过数据效能评估,我们可以大概知道这个数据或是模型,能否满足我们的基本需求,是否值得我们花精力去开发相应的规则策略及产生额外的数据购买成本。
模型与策略开发
如果数据字段的区分能力已经好到直接用到规则中,那么这个时候可以直接通过数据表现来确定阈值,将该字段放入规则中。
如果数据字段的区分能力不足以直接进入规则,那么就需要开发一个新的模型,将这个字段引入已有的A卡或者B卡中。然后再讲新的模型引入规则。
对新策略进行盈利分析。根据新的字段或模型研发出的审核策略,除了在开发流程中要考虑的通过率和逾期率的影响以外,还应该全面的评估新策略对于审核成本,获客成本,客户体验,对坏账的影响等等,考虑的因素基本就可以参照我的速算公式,但是在进行财务预测的时候要更加的严谨,各项参数还要考虑到未来的变化。
以上就是预评估阶段主要要做的事情,把这个流程完整的做完是非常复杂的,而且差不多每一个小步骤都可以展开成一个很大的话题。
测试评估:
经过了一个完整的预评估流程,说明经过历史数据的评估,已经证明将要上线的数据、模型、策略是有价值的。同时之前的预评估都是由数据部门或风险部门的分析师完成的,还未涉及到系统的开发对接。测试评估主要分两个阶段:
模拟上线阶段
通过系统对接、开发、测试(此处删去开发和测试的辛酸泪五万余字。。。。。)我们的新模型和策略已经在系统中等待调用了。但是,从谨慎的角度,在这里并不能直接将相关策略应用在真实的用户上,很多同学都知道要做冠军挑战者测试。但其实,从测试完整性和谨慎的角度,模拟上线测试是要先进行的。
模拟线上测试其实是将新策略在真实的业务环境中运行一段时间,记录相关结果,但运行结果不影响真实的业务运行。
冠军挑战者测试
通过了模拟上线测试下一步,就要开始将一小部分真实的用户切换到新的策略中了,将现有的规则(冠军)和新规则(挑战者)进行比较;同时,冠军挑战者测试并不是一次性的,而是一个动态的过程,应该根据测试的结果,不断调整冠军和挑战者的用户比例,根据产品的用户规模,这个动态的过程可快可慢,但总的方向是不断扩大挑战者测试的用户规模。
通过了冠军挑战者测试,终于可以将现有策略淘汰了,但是不是我们数据评估的过程就结束了,下面就要开始第三个模块了。
运营监控:
在新的模型、策略规则完全上线后,并不是可以当甩手掌柜了,运营监控是一个长期且没有止境的过程,直到这个新模型“退休”。
运营监控主要要做的是如下几方面的工作:
第三方数据源的稳定性。包括查得率,字段数据分布等等。
模型和策略的前端稳定性。包括模型和测试输入的数据字段(内部和外部)数值值的分布。
模型和策略的后端稳定性。包括模型表现各项数据指标的稳定性;各个规则的漏斗率等。
这里给大家举个例子
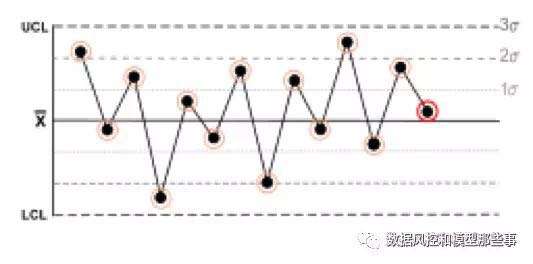
这个是某指标连续14天的变化趋势,往返上升或下降,通常在第14个点会触发我们的监控规则。
当如上三个方面的稳定性发生明显偏差时,就需要采取相应对策了,对数据源、策略、模型进行调整。
请大家别怪我啰嗦,前面讲的所有知识点,在模型的过程都会不断的调用。
本文作者:ZROBOT技术总监 @张SOMEBODY
