

参考资料:
缘由
Go语言极其精简, 不像其他语言有那么多花花肠子, 秉承着一个目的尽量只有一种解决方法的哲学. 导致于我们有可能在一篇文章中就阐述清楚它的基本语法.
文中的内容是阅读Golang官方文档时的笔记和理解, 所以基本囊括了官方入门教程的知识点.
对照代码注释和打印的日志说明可以加深理解.
Q: 为什么是长文, 而不是分成一章章?
A: 一篇长文慢慢滚动着看, 更容易不知不觉看完...逃...
目录
- 环境安装及配置
- 你的第一个程序
- 初始化顺序\命名规范
- 几句话说明白指针
- slice的基础使用
- map的基础使用
- 函数及闭包
- 结构体的函数扩展
- Interface接口
- error的使用
- goroutine:Go程
- channel信道
- select协程切换
- 编写测试
- 文件\文件夹创建,读取,移动,复制,写入,遍历
- Web服务器
- 多CPU并行
环境安装及配置 (解决墙内问题)
安装Go
前往https://golang.org/dl/ 下载并安装特定平台的Go安装包
Linux使用命令下载安装包
wget https://golang.org/doc/install?download=go1.10.2.linux-amd64.tar.gz
配置环境变量
在.bash_profile中加入:
export GOROOT=/usr/local/go
export GOPATH=/Users/ym/golang
配置VSCode环境
下载VSCode: https://code.visualstudio.com/
这里IDE选用VSCode, 其他IDE也是一个思路
安装VSCode Golang插件
安装IDE依赖的Golang库
介于大陆的网络环境, 需要手动安装以下Golang库
如果是Mac用户也可以下载我已经下载好的环境,放在GoPath中, 链接:https://pan.baidu.com/s/1ew_hGhu1hs9BVIH97rgWNQ 密码:vytk
喜欢手动党, 可前往https://www.golangtc.com/download/package手动下载以下包, 然后执行, 其中涉及lint和tool的包(golang.org的包)只要下载一次
## 语法检测包
go install golang.org/x/lint/golint
go install golang.org/x/tools/cmd/guru
go install golang.org/x/tools/cmd/gorename
go install github.com/nsf/gocode
go install github.com/uudashr/gopkgs/cmd/gopkgs
go install github.com/ramya-rao-a/go-outline
go install github.com/acroca/go-symbols
go install github.com/rogpeppe/godef
go install github.com/sqs/goreturns
# 调试包, 安装了才可以打断点
go install github.com/derekparker/delve/cmd/dlv
你的第一个Go程序
设定程序路径
要编译并运行简单的程序,首先要选择包路径(我们在这里使用 github.com/user/hello),并在你的工作空间内创建相应的包目录:
$ mkdir $GOPATH/src/github.com/{你的github账户}/hello
创建main.go文件
在该目录中创建名为 main.go 的文件, 目录如图:
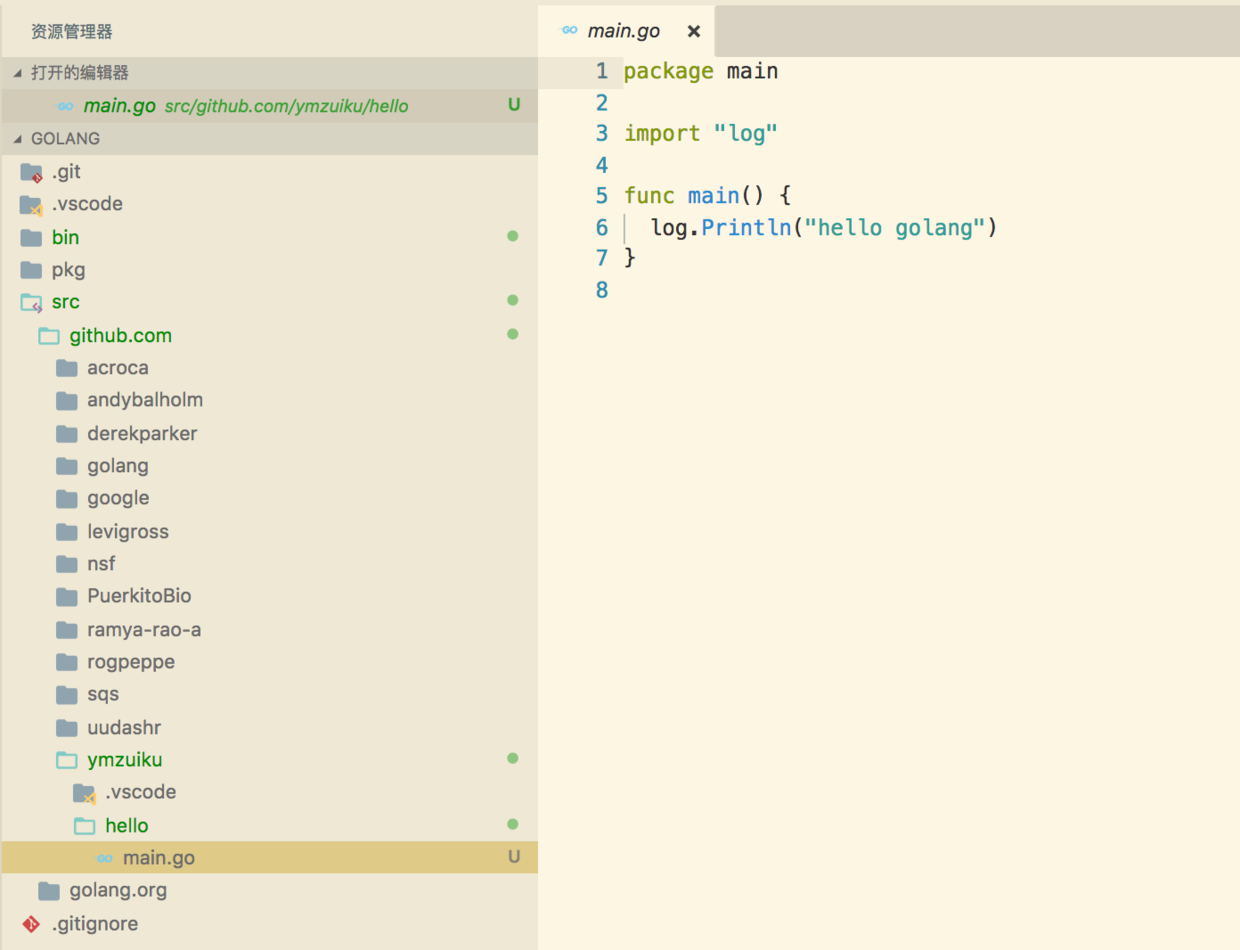
其内容为以下Go代码:
package main
import "log"
func main() {
log.Println("hello golang")
}
编译hello程序
现在你可以用 go 工具构建并安装此程序了, 此命令会编译一个程序至$GOPATH/bin/hello:
$ go install github.com/{你的github账户}/hello
你可以在系统的任何地方运行此命令。go 工具会根据 GOPATH 指定的工作空间
执行hello程序
$ hello
输出如图
编译Linux版本
该命令会在当前路径下生成一个Linux系统的可执行文件, 把文件拷贝到Linux下执行即可
cd your-project
GOOS=linux GOARCH=amd64 go build -o hello hello.go
初始化顺序\命名规范
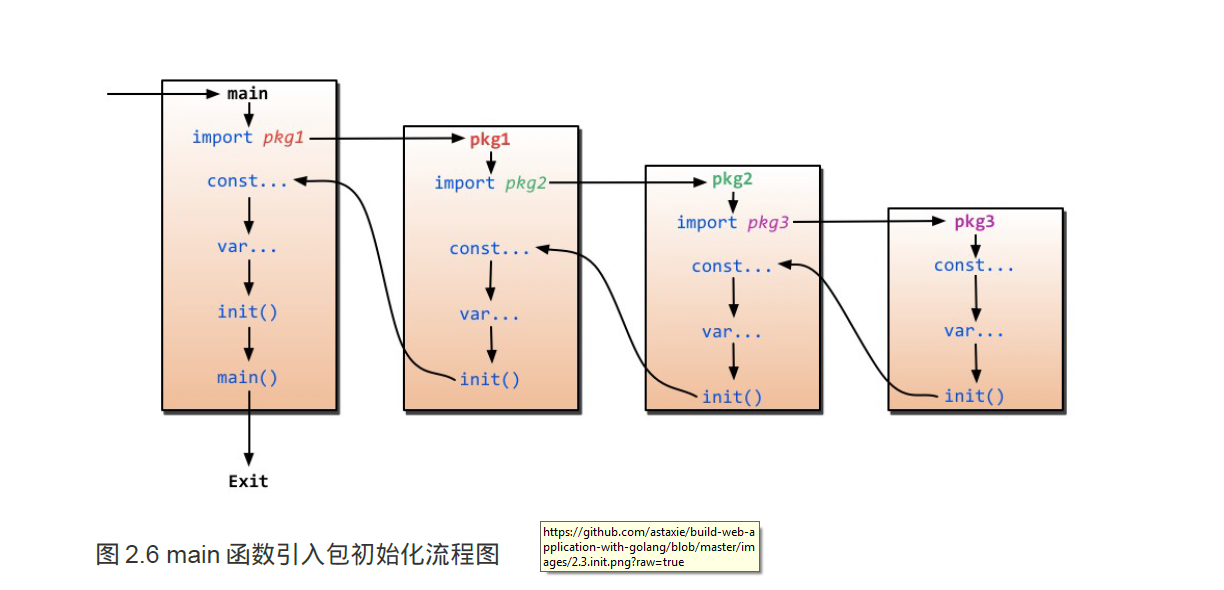
初始化顺序
先执行import包的每个文件的变量, 然后是init方法, 最后执行main函数, 当main函数执行结束程序退出
函数\变量\结构体 命名
某个名称在包外是否可见,取决于其首个字符是否为大写字母
Go中约定使用驼峰记法 MixedCaps 或 mixedCaps。
由于结构体在大多数地方会被引用, 所以通常是大写开头
接口名
按照约定,只包含一个方法的接口应当以该方法的 名称加上-er后缀 或类似的修饰来构造一个施动着名词,如 Reader、Writer、 Formatter、CloseNotifier 等.
请不要使用I开头作为接口命名 如IRead, IWrite
重新声明与再次赋值
f, err := os.Open(name)
该语句声明了两个变量 f 和 err。在几行之后,又通过
d, err := f.Stat()
注意,尽管两个语句中都出现了 err,但这种重复仍然是合法的:err 在第一条语句中被声明,但在第二条语句中只是被再次赋值罢了
在满足下列条件时,已被声明的变量 v 可出现在:= 声明中:
- 本次声明与已声明的 v 处于同一作用域中(若 v 已在外层作用域中声明过,则此次声明会创建一个新的变量§),
- 在初始化中与其类型相应的值才能赋予 v, 且 在此次声明中至少另有一个变量是新声明的
空白符
若你只需要该遍历中的第二个项(值),请使用空白标识符,即下划线来丢弃第一个值:
for _, value := range array {
sum += value
}
几句话说明白指针
总结
- 指针对象是用来存储内存地址的数据类型
- &符号获取对象的内存地址
- *符号根据内存地址获取值, 只有指针对象可以使用该符号
指针
仔细看代码注释, 应该描述得足够明细了
package main
import "fmt"
func main() {
// 重点句子1: 指针对象是用来存储内存地址的数据类型
// 重点句子2: &符号获取对象的内存地址
// 重点句子3: *符号根据内存地址获取值, 只有指针对象可以使用*符号
var p *int // 创建了一个int类型的指针对象
// fmt.Println(p) //此时 p 是 <nil>
// 创建一个int变量
var v = 20
fmt.Println(v) // 50 v得到了新值:50
fmt.Println(&v) // 0xc4200160a8 v的内存地址没有变化
// fmt.Println(*v) // 错误, v是一个int对象,不是一个指针对象
p = &v // &符号得到了v的内存地址, 赋值给指针p
// 此时 p指针已经有了一个内存地址了
fmt.Println(p) // 0xc4200160a8 这个是v的内存地址
fmt.Println(&p) // 0xc420016028 这个是p指针的内存地址, 一般用不到
fmt.Println(*p) // *符号会根据p所保存的内存地址,获取到该内存地址指向的值,即v的值
// 修改对象的值
v = 50
fmt.Println(v) // 50 v得到了新值:50
fmt.Println(&v) // 0xc4200160a8 v的内存地址没有变化
fmt.Println(p) // 0xc4200160a8 p还是这个v的地址,没有修改
fmt.Println(*p) // 50 *符号得到内存地址的值, v已经修改了,
// 通过指针修改对象的值
*p = 100
fmt.Println(v) // 100 v得到了新值:100
fmt.Println(&v) // 0xc4200160a8 v的内存地址没有变化
fmt.Println(p) // 0xc4200160a8 p还是这个v的地址,没有修改
fmt.Println(*p) // 100 *符号得到内存地址的值, v已经修改了,
}
结构体和指针
package main
import "fmt"
// Vertex 声明一个结构体
type Vertex struct {
X int
Y int
}
func main() {
// 实例化一个结构体
var v = Vertex{1, 2}
// 实例化一个结构体指针
var p *Vertex
// 把结构体的内存地址复制给指针
p = &v
// 以上三行一般情况下省略为:
// 实例化一个结构体指针
// var p = &Vertex{1, 2}
// 对比上一段普通指针的几种情况
fmt.Println(v) // {1, 2} 这是结构体值
fmt.Println(p) // &{1, 2} 这是结构体指针和普通指针的区别 直接显示对象地址 而不是0x123456的内存地址
fmt.Println(*p) // {1, 2} 结构体对象的值
fmt.Println(&p) // 和普通指针一样, *p是指针对象的内存地址, 和结构体无关系
fmt.Println(p) // &{1, 2} 这是结构体指针和普通指针的区别 直接显示对象地址 而不是0x123456的内存地址
// 根据上面这行的特性
fmt.Println(p.X) //1 可以直接访问结构体指针里的对象
fmt.Println(&v.X) //0xc420096010 v.X的内存地址
fmt.Println(&p.X) //0xc4200160b0 &p.X的内存地址和 v.X是一样的,因为它们是同一个对象
}
slice的基础使用
数组的长度不可改变,切片长度是可变的, 相当于可变数组
package main
import (
"log"
"sort"
)
func main() {
// 声明一个数组, 数组需要指定长度
var arr = [10]string{}
// 声明一个切片, 不需要指定长度
var slice = []string{}
log.Println(arr) // [ ]
log.Println(slice) // []
// 使用make方法创建切片, 初始大小为0, 最大大小为10, 设定一个足够大的最大值, 会使得切片获得更高的性能
var a = make([]string, 0, 10)
// 给切片a添加一个对象
a = append(a, "dog")
// 给切片添加多个对象
a = append(a, "cat", "fish", "bird", "menkey")
// 合并两个切片, {}...是解构数组
a = append(a, []string{"dog2", "cat2", "fish2", "bird2", "menkey2"}...)
// 查看切片长度
log.Println(len(a))
// 查看切片的最大长度
log.Println(cap(a))
// 截取切片
a = a[1:6] // 保留a[1], a[2], [3], a[4], a[5]
// 切片删除 a[2], a...是解构数组
a = append(a[:2], a[2+1:]...)
// 切片插入元素 a[2] = "newA2"
var temp = append(a[:2], "newA2")
a = append(temp, a[2+1:]...)
// 切片升序排序
a = append(a, "apple")
sort.Strings(a)
log.Println(a) //[apple cat dog2 fish newA2]
// 切片降序排序
sort.Sort(sort.Reverse(sort.StringSlice(a)))
log.Println(a) //[apple cat dog2 fish newA2]
// 切片的拷贝
tempCopy := make([]string, len(a))
copy(tempCopy, a)
// 切片的遍历
for i, v := range a {
log.Println(i, v)
}
// 切片的去重
a1 := []string{"dog", "cat", "dog", "dog", "fish", "fish"}
a2 := []string{}
for _, v1 := range a1 {
canAdd := true
for _, v2 := range a2 {
if v1 == v2 {
canAdd = false
}
}
if canAdd {
a2 = append(a2, v1)
}
}
log.Println("去重:", a2) //去重: [dog cat fish]
// 切片交集
b_one := []string{"dog", "cat", "dog", "dog", "fish", "fish"}
b_two := []string{"monkey", "fish", "dog"}
b2 := []string{}
for _, v1 := range b_one {
canAdd := false
for _, v2 := range b_two {
if v1 == v2 {
canAdd = true
}
}
if canAdd {
b2 = append(b2, v1)
}
}
log.Println("交集:", b2) //交集: [dog cat fish]
// 切片指针
// 切如果动态修改了大小, go会创建一个新的切片, 地址就变化了, 如果要获得一直获得内存地址, 可以使用切片指针
var b []string
var p = &b
*p = append(*p, "dog")
log.Println(*p)
*p = append(*p, "cat")
log.Println(*p)
}
map的基础使用
map的声明
package main
import "log"
// Vertex 大写开头的为Public对象, 必须写注释说明, golint会做检测
type Vertex struct {
Lat, Long float64
}
func main() {
// 使用 make 声明一个map, 键为string, 值为Vertex类型
var m = make(map[string]Vertex)
m["dog"] = Vertex{50, 100}
log.Println(m) //map[dog:{50 100}]
log.Println(m["dog"]) //{50 100}
// 也可使用有初始值的map[k]v声明
var m2 = map[string]Vertex{
"dog": Vertex{100, 150},
"cat": {200, 250}, // 可以忽略结构体的类型名
}
m2["fish"] = Vertex{300, 350}
log.Println(m2) // map[fish:{300 350} dog:{100 150} cat:{200 250}]
}
map的操作
package main
import (
"log"
)
// Vertex 大写开头的为Public对象, 必须写注释说明, golint会做检测
type Vertex struct {
Lat, Long float64
}
func main() {
// 也可使用有初始值的map[k]v声明
var m = map[string]Vertex{
"dog": {100, 150},
"cat": {200, 250},
}
// 插入或修改元素
m["fish"] = Vertex{300, 350}
// 获取元素, ok是来检测对象是否存在
var ele, ok = m["fish"]
log.Println(ele, ok) //Vertex{300, 350}, true
ele2, ok := m["monkey"]
log.Println(ele2, ok) //Vertex{0, 0}, false
// 删除
delete(m, "fish")
// 合并map
m2 := map[string]Vertex{
"dog2": {1000, 1500},
"cat2": {2000, 2500},
}
for k, v := range m2 {
m[k] = v
}
// map遍历
for k, v := range m {
log.Println("key:", k, "value:", v)
}
log.Println(m)
}
函数及闭包
Golang中, 函数是一等公民, 以下简要描述函数的使用
函数的声明
package main
import (
"log"
)
// 函数的创建
func say() {
log.Println("hello func")
}
func main() {
// 函数的运行
say()
// 函数也是值
add := func(x, y float64) float64 {
return x + y
}
log.Println(add) // 0x10b0cd0
log.Println(add(3, 4)) // 7
}
// 参数, 返回值
func sub1(a float64, b float64) float64 {
return b - a
}
// 参数声明合并, 多个返回值
func sub2(a, b float64) (float64, bool) {
c := b - a
ok := true
if c >= 0 {
ok = false
}
return c, ok
}
// 带命名的返回值
func sub3(a, b float64) (c float64, ok bool) {
// c 和 o k不需要再声明, 因为返回值里已经声明了
c = b - a
ok = true
if c >= 0 {
ok = false
}
return c, ok
}
闭包
引用官方的解释:
Go 函数可以是闭包的。闭包是一个函数值,它来自函数体的外部的变量引用。 函数可以对这个引用值进行访问和赋值;换句话说这个函数被“绑定”在这个变量上。
例如,函数 adder 返回一个闭包。每个闭包都被绑定到其各自的 sum 变量上。
package main
import "log"
// 函数的返回值是一个函数
func adder(start int) func(int) int {
sum := start
return func(x int) int {
sum += x
return sum
}
}
func main() {
// pos, neg 都是一个闭包
// 有权访问另一个函数作用域内变量的函数都是闭包
pos, neg := adder(5000), adder(10)
log.Println(pos(10), neg(10)) // 5010 20
}
给你可以对已有类型扩展方法
package main
import (
"log"
)
// MyString - add log
type MyString string
func (f MyString) log() {
log.Println(f)
}
func main() {
f := MyString("hello MyString")
f.log()
}
结构体的函数扩展
Go 没有类。然而,仍然可以在结构体类型上定义方法。
结构体的函数扩展可以帮助我们实现类似面向对象的"类的封装"
给结构体扩展方法
package main
import (
"log"
)
// Vertex -
type Vertex struct {
X, Y float64
}
// Scale - 正确的例子
func (v *Vertex) Scale(f float64) {
v.X = v.X * f
v.Y = v.Y * f
}
// Small - 错误的例子
func (v Vertex) Small(f float64) {
v.X = v.X / f
v.Y = v.Y / f
}
func main() {
// Scale 使用了 *Vertex 指针, 避免在每个方法调用中拷贝值(如果值类型是大的结构体的话会更有效率
// 其次,方法可以修改接收者指向的值
v1 := &Vertex{3, 4}
v1.Scale(5)
log.Println(*v1) // {15 20}
// Small 方法没有使用指针, 函数里头的v是拷贝值, 每次修改的都是新的拷贝值, 所以v2没有被修改
v2 := Vertex{3, 4}
v2.Small(2)
log.Println(v2) // {3, 4}
}
Interface接口
接口 interface
接口声明了方法集合
如果某个结构体实现了接口内的所有方法, 就可以把该结构体赋值给接口
接口可以帮助我们实现类似面向对象的"类的继承"
package main
import (
"log"
)
// Abser 接口定义了方法集合
type Abser interface {
Abs() float64
}
// Vertex -
type Vertex struct {
X, Y float64
}
// Abs -
func (v *Vertex) Abs() float64 {
return v.X*v.X + v.Y*v.Y
}
func main() {
// 创建一个 Abser 接口变量 a
var a Abser
// 由于 *Vertex 实现了Abs(), 所以他实现了接口a的所有方法, 可以赋值给接口a
a = &Vertex{3, 5} // 正确, *Vertex 上实现了Abs()
// b = Vertex{3, 4} // 运行错误, Vertex 上没有实现Abs()
log.Println(a.Abs()) // 34
}
隐式接口
相当于合并了 其他接口的定义
package main
import (
"log"
"os"
)
// Reader 定义一个接口
type Reader interface {
Read(b []byte) (n int, err error)
}
// Writer 定义一个接口
type Writer interface {
Write(b []byte) (n int, err error)
}
// 隐式接口, 相当于合并了 其他接口的定义
type ReadWriter interface {
Reader
Writer
}
func main() {
var w ReadWriter
w = os.Stdout
log.Println(w) // &{0xc420098050}
log.Println(w.Read) // 0x10b1690
}
泛型: 使用接口作为函数的参数
package main
import "log"
// Point -
type Point struct {
x, y float64
}
// 接口作为参数
func anyParams(v interface{}) {
// 判断 v 是否可以转换为 int 类型
if f, ok := v.(int); ok {
log.Println(f)
}
// 判断 v 是否可以转换为 string 类型
if f, ok := v.(*Point); ok {
log.Println(f.x + f.y)
}
}
func main() {
anyParams(2) // 2
anyParams(&Point{100, 150}) // hello T
}
参数和返回值都是接口的例子
package main
import "log"
// 接口作为参数, 接口作为返回值
func anyBack(v interface{}) interface{} {
if f, ok := v.(int); ok {
end := f * f
return end
} else if f, ok := v.(string); ok {
end := f + f
return end
}
return v
}
func main() {
b1 := anyBack(200)
log.Println(b1) // 40000
b2 := anyBack("hello")
log.Println(b2) // hellohello
}
error的使用
习惯使用error类型, 并且做好判断, 能很大程度上提高程序的健壮性
养成习惯, 不然等运行时错误不好捕获
package main
import (
"errors"
"log"
)
// Sqrt -
func Sqrt(x float64) (float64, error) {
if x < 0 {
return 0, errors.New("x小于0了")
}
return x * x, nil
}
func main() {
if v, err := Sqrt(-5); err != nil {
log.Println(err)
} else {
log.Println(v)
}
}
goroutine: Go程
goroutine称之为Go程是因为现有的术语—线程、协程、进程等等均无法准确传达它的含义
goroutine是通过Go的runtime管理的一个轻量级线程管理器
goroutine是Go并行设计的核心
go语句开启一个goroutine
package main
import (
"log"
"time"
)
func say(s string) {
for i := 0; i < 5; i++ {
log.Println(i, s, &s)
}
}
func main() {
// go 语句执行一个函数, 即开启一个goroutine线程
go say("goroutine")
say("sync")
// 这里如果不使用time.Sleep, main函数很快就执行完了
// 子线程还未执行完,整个主线程就结束了, 就不会打印goroutine
time.Sleep(500 * time.Millisecond)
}
打印的内容:
2018/06/03 15:11:23 0 sync 0xc42000e1e0
2018/06/03 15:11:23 1 sync 0xc42000e1e0
2018/06/03 15:11:23 0 goroutine 0xc42009e000
2018/06/03 15:11:23 1 goroutine 0xc42009e000
2018/06/03 15:11:23 2 goroutine 0xc42009e000
2018/06/03 15:11:23 3 goroutine 0xc42009e000
2018/06/03 15:11:23 2 sync 0xc42000e1e0
2018/06/03 15:11:23 3 sync 0xc42000e1e0
2018/06/03 15:11:23 4 sync 0xc42000e1e0
2018/06/03 15:11:23 4 goroutine 0xc42009e000
channel: 信道
channel 信道的创建
ci := make(chan int) // 整数类型的无缓冲信道
cj := make(chan int, 0) // 整数类型的无缓冲信道
cs := make(chan *os.File, 100) // 指向文件指针的带缓冲信道
channel 是带缓冲和阻塞的信道
默认情况下,在另一端准备好之前,发送和接收都会阻塞。这使得 goroutine 可以在没有明确的锁或竞态变量的情况下进行同步。
ch := make(chan int)
ch <- v // 将 v 送入 channel ch。
v := <-ch // 从 ch 接收,并且赋值给 v。
(“箭头”就是数据流的方向。)
goroutline配合channel, 以实现多线程的同步操作
向缓冲 channel 发送数据的时候,只有在缓冲区满的时候才会阻塞。当缓冲区清空的时候接受阻塞。
package main
import (
"log"
"time"
)
// 声明一个函数,
func add(a int, c chan int) {
log.Println("准备往管道添加:", a)
c <- a
}
func main() {
a := []int{1, 2, 3, 4, 5, 6}
// 声明了一个管道, 管道长度为0
c := make(chan int)
// 做两个循环, 开启多个协程
for _, v := range a[:len(a)/2] {
go add(v, c)
}
for _, v := range a[len(a)/2:] {
go add(v, c)
}
// 上面的chan是阻塞的, 每当这里取出一个值, 上面的协程才会继续再执行一次
var x, y, n int
for i := 0; i < len(a)/2; i++ {
n = <-c
log.Println("从管道取出:", n, "并加入到x中")
x += n
n = <-c
log.Println("从管道取出:", n, "并加入到y中")
y += n
}
time.Sleep(500 * time.Microsecond)
log.Printf("x:%d, y:%d, sum:%d", x, y, x+y)
}
打印的内容(执行的顺序每次不一, 但是sum的总和是一致的):
2018/06/03 15:50:14 准备往管道添加: 6
2018/06/03 15:50:14 从管道取出: 6 并加入到x中
2018/06/03 15:50:14 准备往管道添加: 2
2018/06/03 15:50:14 从管道取出: 2 并加入到y中
2018/06/03 15:50:14 准备往管道添加: 5
2018/06/03 15:50:14 从管道取出: 5 并加入到x中
2018/06/03 15:50:14 准备往管道添加: 1
2018/06/03 15:50:14 准备往管道添加: 3
2018/06/03 15:50:14 从管道取出: 1 并加入到y中
2018/06/03 15:50:14 从管道取出: 3 并加入到x中
2018/06/03 15:50:14 准备往管道添加: 4
2018/06/03 15:50:14 从管道取出: 4 并加入到y中
2018/06/03 15:50:14 x:14, y:7, sum:21
range 和 close
发送者可以 close 一个 channel 来表示再没有值会被发送了。接收者可以通过赋值语句的第二参数来测试 channel 是否被关闭:当没有值可以接收并且 channel 已经被关闭,那么经过
v, ok := <-ch
之后 ok 会被设置为 false。
循环 for i := range c 会不断从 channel 接收值,直到它被关闭。
注意: 只有发送者才能关闭 channel,而不是接收者。向一个已经关闭的 channel 发送数据会引起 panic。 还要注意: channel 与文件不同;通常情况下无需关闭它们。只有在需要告诉接收者没有更多的数据的时候才有必要进行关闭,例如中断一个 range。
package main
import "log"
func fibonacci(n int, c chan int) {
x, y := 0, 1
for i := 0; i < n; i++ {
c <- x
x, y = y, x+y
}
// close 关闭一个 channel
// close 只能由发送者(协程的函数)执行
close(c)
}
func main() {
c := make(chan int, 10)
go fibonacci(cap(c), c)
//还要注意: channel 与文件不同;通常情况下无需关闭它们。只有在需要告诉接收者没有更多的数据的时候才有必要进行关闭,例如中断一个 `range`
for v := range c {
log.Println(v)
}
}
select 协程切换
select 可以很好的配合 goroutline 和 channel
select 语句使得一个 goroutine 在多个通讯操作上等待。
select 会阻塞,直到条件分支中的某个可以继续执行,这时就会执行那个条件分支。当多个都准备好的时候,会随机选择一个。
当 select 中的其他条件分支都没有准备好的时候,default 分支会被执行, 此时不会阻塞
下面例子中,因为select的阻塞, 即便没有添加time.Sleep(), 主线程也没有退出
package main
import "log"
func fibonacci(c, quit chan int) {
x, y := 0, 1
for {
select {
case c <- x:
x, y = y, x+y
case <-quit:
log.Println("quit")
return
}
// 如果为了非阻塞的发送或者接收,可使用 default 分支
// default:
// log.Println("默认执行")
}
}
func main() {
c := make(chan int)
quit := make(chan int)
go func() {
for i := 0; i < 10; i++ {
// 取出10次c管道中的内容
log.Println(<-c)
}
// 当执行了 quit的取操作时, select语句切换到 case <- quit语句
quit <- 0
}()
fibonacci(c, quit)
}
编写测试
Go拥有一个轻量级的测试框架,它由 go test 命令和 testing 包构成
hello.go 编写待测试的函数
package hello
import "log"
func main() {
log.Println("hello golang")
}
// 此函数一会用于测试
func add(a, b int) int {
// 故意写错, 返回的值多了1
return a + b + 1
}
在hello.go同级目录下创建hello_test.go文件:
package hello
import (
"testing"
)
func TestAdd(t *testing.T) {
got := add(20, 30)
expect := 50
if got != expect {
t.Errorf("got := add(20, 30) != 50")
}
}
执行测试命令, 此命令会遍历项目里的_test后缀文件进行执行:
go test
得到测试结果:
--- FAIL: TestAdd (0.00s)
hello_test.go:11: got := add(20, 30) != 50
FAIL
exit status 1
FAIL github.com/ymzuiku/hello 0.006s
如果把add函数的返回值改成正确的, 得到的测试结果:
PASS
ok github.com/ymzuiku/hello 0.006s
文件&文件夹创建\读取\移动\复制\写入\遍历
Go语言给予了非常实用的文件操作, 大体分为两部分:
os库 : 文件\文件夹创建,读取,移动,复制
io库 : 文件内容的写入,修改,拼接
基本文件操作
文件内容的读取
package main
import (
"io/ioutil"
"log"
)
func main() {
// 读取文件内容
file, _ := os.OpenFile("./demo_unicode.html", 2, 0666)
fileByte1, _ = ioutil.ReadAll(file);
// 读取文件内容,更简易的方法
fileByte2, _ := ioutil.ReadFile("./demo_unicode.html")
// byte转string
fileString := string(fileByte2)
log.Println(fileString)
}
文件的常规操作,复制以下代码进main.go, 执行后看看效果, 再逐行阅读代码
package main
import (
"io"
"os"
)
func main() {
// 设定工作路径, 一般在项目刚开始设定一次即可, 不要在异步过程中修改工作路径
// 默认是程序执行的路径
os.Chdir("./")
// 创建文件夹
os.MkdirAll("./aa/bb/c1", 0777)
os.MkdirAll("./aa/bb/c2", 0777)
// 创建文件
os.Create("./aa/bb/c1/file.go")
// 移动文件
os.Rename("./aa/bb/c1/file.go", "./aa/bb/c2/file.go")
// 打开文件,得到一个 *File 对象, 用于后续的写入
file, _ := os.OpenFile("./aa/bb/c2/file.go", 2, 0666)
// 写入文件内容
io.WriteString(file, `
package main
func main(){
log.Println("我是由程序写入的代码")
}
`)
// 也可以直接调用file里的函数写入内容
file.WriteString("add string")
// 拷贝文件, 拷贝其实就是创建一个文件, 然后写入文件内容
src1, _ := os.Create("./aa/bb/c1/file-copy1.go")
io.Copy(file, src1) // 把文件file, 写入src1文件
// 删除文件或文件夹
os.Create("./aa/bb/c1/file-delete.go") // 创建一个文件用于删除
os.RemoveAll("./aa/bb/c1/file-delete.go")
}
文件覆盖判断 os.IsNotExist
当文件已存在时, 不管是
os.Rename(),os.Create(), 还是io.WriteString()都会对已存在的文件进行覆盖\修改,
如果需要安全的执行, 可以使用
os.Stat()配合os.IsNotExist()做判断
package main
import (
"io"
"os"
)
func main() {
os.MkdirAll("aa", 0777)
// 创建了文件 testA, 并且写入了内容
testA, _ := os.Create("aa/testA")
io.WriteString(testA, "the teatA")
// 如果需要安全判断, 可以使用 os.Stat 配合 os.IsNotExist
if _, err := os.Stat("aa/testA"); os.IsNotExist(err) {
// 当文件不存在, 才执行创建
os.Create("aa/testA")
}
os.Chmod("aa/testA", 0777)
}
遍历文件夹
遍历文件夹可以使用 ioutil库 的ioutil.ReadDir, 会得到一个数组, 数组元素有文件的属性,
package main
import (
"io/ioutil"
"log"
)
func main() {
fs, _ := ioutil.ReadDir("aa")
for _, v := range fs {
// 遍历得到文件名
log.Println(v.Name())
log.Println(v.IsDir())
}
}
权限
可以使用
os.Chmod()修改文件权限
// 所有人可读写权限
os.Chmod("aa/testA", 0666)
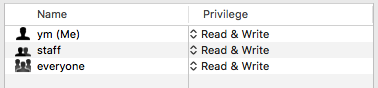
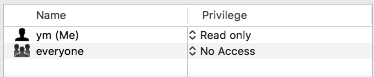
// 只读权限
os.Chmod("aa/testA", 0400)
Linux权限参考:
-rw------- (600) 只有拥有者有读写权限。
-rw-r--r-- (644) 只有拥有者有读写权限;而属组用户和其他用户只有读权限。
-rwx------ (700) 只有拥有者有读、写、执行权限。
-rwxr-xr-x (755) 拥有者有读、写、执行权限;而属组用户和其他用户只有读、执行权限。
-rwx--x--x (711) 拥有者有读、写、执行权限;而属组用户和其他用户只有执行权限。
-rw-rw-rw- (666) 所有用户都有文件读、写权限。
-rwxrwxrwx (777) 所有用户都有读、写、执行权限。
Web服务器
使用http启动一个服务
package main
import (
"io"
"log"
"net/http"
)
func hello(w http.ResponseWriter, r *http.Request) {
io.WriteString(w, "hello world")
}
func main() {
http.HandleFunc("/", hello)
log.Println("listen: http://localhost:8000/")
http.ListenAndServe(":8000", nil)
}
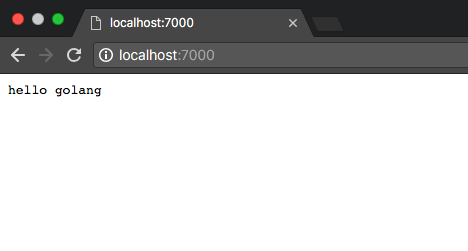
访问 http://localhost:7000 可以看到来自程序的问候
实际工作中,我们会使用Iris或者beego编写一个Web服务
多CPU并行
多CPU并行
这些设计的另一个应用是在多CPU核心上实现并行计算。如果计算过程能够被分为几块 可独立执行的过程,它就可以在每块计算结束时向信道发送信号,从而实现并行处理。
让我们看看这个理想化的例子。我们在对一系列向量项进行极耗资源的操作, 而每个项的值计算是完全独立的。
type Vector []float64
// 将此操应用至 v[i], v[i+1] ... 直到 v[n-1]
func (v Vector) DoSome(i, n int, u Vector, c chan int) {
for ; i < n; i++ {
v[i] += u.Op(v[i])
}
c <- 1 // 发信号表示这一块计算完成。
}
我们在循环中启动了独立的处理块,每个CPU将执行一个处理。 它们有可能以乱序的形式完成并结束,但这没有关系; 我们只需在所有Go程开始后接收,并统计信道中的完成信号即可。
const NCPU = 4 // CPU核心数
func (v Vector) DoAll(u Vector) {
c := make(chan int, NCPU) // 缓冲区是可选的,但明显用上更好
for i := 0; i < NCPU; i++ {
go v.DoSome(i*len(v)/NCPU, (i+1)*len(v)/NCPU, u, c)
}
// 排空信道。
for i := 0; i < NCPU; i++ {
<-c // 等待任务完成
}
// 一切完成。
}
