

此文首发于公众号「Python知识圈」,欢迎直接去公众号看
前言
大家好,这里是「Python知识圈」爬虫 系列教程。此文首发于「Python知识圈」公众号,欢迎大家去关注。此系列教程以实例项目为材料进行分析,从项目中学习 python 爬虫,跟着我一起学习,每天进步一点点。
煎蛋网站
煎蛋网.png
很多朋友都反应学 python 语言太枯燥,学不进去,其实学语言最好的方法是自己用所学的语言做项目,在项目中学习语言的用法。今天给大家带来的项目是用 python3 爬取煎蛋网妹子的图片。图片质量还不错,我放两张图片大家感受下。

007bk2ovgy1fsy6w0g6x9j30ia0rfjwd.jpg

007bk2ovgy1fsplp6cen2j30i20rwn0j.jpg
这个项目用了 requests + selenium + beautifulsoup 库对网站的图片进行抓取。接下来我就,给大家一步步解析一下,怎么用 python 爬虫爬取图片并下载的。
爬取结果
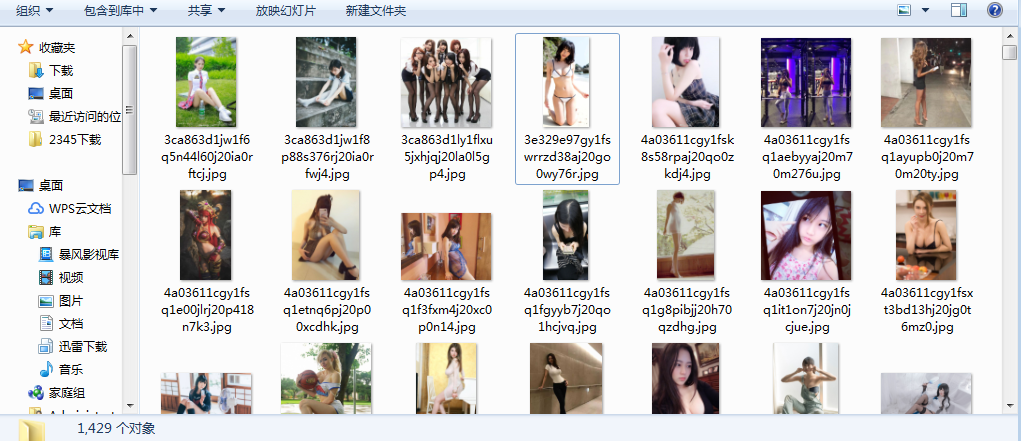
爬取成果.png
以上就是爬取的结果,通过运行 meizi.py 代码,就可以把图片保存在我指定的目录下,如果没有此目录,就用程序自动创建目录,爬取的所有图片都保存在此目录下。
