

Operationalizing Node.js for Server Side Rendering
As Airbnb builds more of its Frontend around Server Side Rendering, we took a look at how to optimize our server configurations to support it.

At Airbnb, we have spent years steadily migrating all Frontend code to a consistent architecture where entire web pages are written as a hierarchy of React components hydrated with data from our API. The role Ruby on Rails plays in getting the web to the browser is reduced every day. In fact, soon we will be transitioning to a new service that will deliver fully formed, server rendered web pages entirely in Node.js. This service will render most of the HTML for all of the Airbnb product. This rendering engine differs from most of the backend services we run by virtue of not being written in Ruby or Java. But it also differs from the sort of common I/O intensive Node.js service that our mental models and common tooling are built around.
When you think of Node.js, you envision your highly asynchronous application efficiently and effectively serving hundreds or thousands of connections simultaneously. Your service is pulling data from all over town and applying at most light processing
to make it palatable to its many, many clients. Maybe you are handling a whole bunch of long lived WebSocket connections. You are happy and confident with your lightweight concurrency model that is perfectly suited for the task.
Server
side rendering (SSR) breaks the assumption that led to that vision. It is compute intensive. User code in Node.js runs in a single thread, so for compute operations (as opposed to I/O), you can execute them concurrently, but not in parallel. Node.js
is able to handle large amounts of asynchronous I/O in parallel, but runs into limits on compute. As the compute portion of the request increases relative to I/O, concurrent requests will have an increasing impact on latency because of contention
for the CPU¹.
Consider Promise.all([fn1, fn2]). If fn1 or fn2 are promises that are resolved by I/O you can achieve parallelism like this:

If fn1 and fn2 are compute, they will instead execute like this:

One operation will have to wait on the other to conclude before it can run, as there is only a single execution thread.
For server side rendering, this comes up when a server process handles multiple concurrent requests. Concurrent requests will be delayed by the other requests that are being processed:

In practice, requests are often composed of many different asynchronous phases, even if still mostly compute. This can result in even worse interleaving. If our request consists of a chain like renderPromise().then(out => formatResponsePromise(out)).then(body => res.send(body)),
we could have request interleaving like

In which case, both requests end up taking twice as long. This problem becomes worse as concurrency increases.
Additionally, one of the common goals of SSR is to be able to use the same or similar code on both the client and the server.
A big difference between these environments is that the client context is inherently single tenant, while the server context is multi-tenant. Techniques that work easily on the client side like singletons or other global state will result in bugs,
data leaks, and general chaos under concurrent request load on the server.
Both of these issues only become a problem with concurrency. Everything will often work just fine under lower levels of load or in the cozy single tenancy of your development environment.
This results in a situation that is quite different from canonical examples of Node applications. We're using the JavaScript runtime for its library support and browser characteristics, rather than for its concurrency model. In this application, the asynchronous concurrency model imposes all of its costs for none or few of its benefits.
Lessons from Hypernova
Our new rendering service, Hyperloop, will become the primary service that users of the Airbnb web site interact with. As such, its reliability and performance is absolutely critical to the user experience. As we move to running production on the
new, we are incorporating the lessons we have learned from our earlier SSR service, Hypernova.
Hypernova works differently from our new
service. It is a pure renderer. It’s called from our Rails monolith, Monorail, and returns only the HTML fragments for specific rendered components. In many cases, the “fragment” is the vast majority of the page, with Rails providing just the
outer layout. In legacy cases, the pieces on the page can be stitched together using ERB. In either case, however, Hypernova handles no data fetching of its own. The data is provided by Rails.
That said, Hyperloop and Hypernova share similar operational characteristics as concerns compute, and as a service running in production with significant traffic, Hypernova provides a good test ground for understanding how its replacement will behave in production.
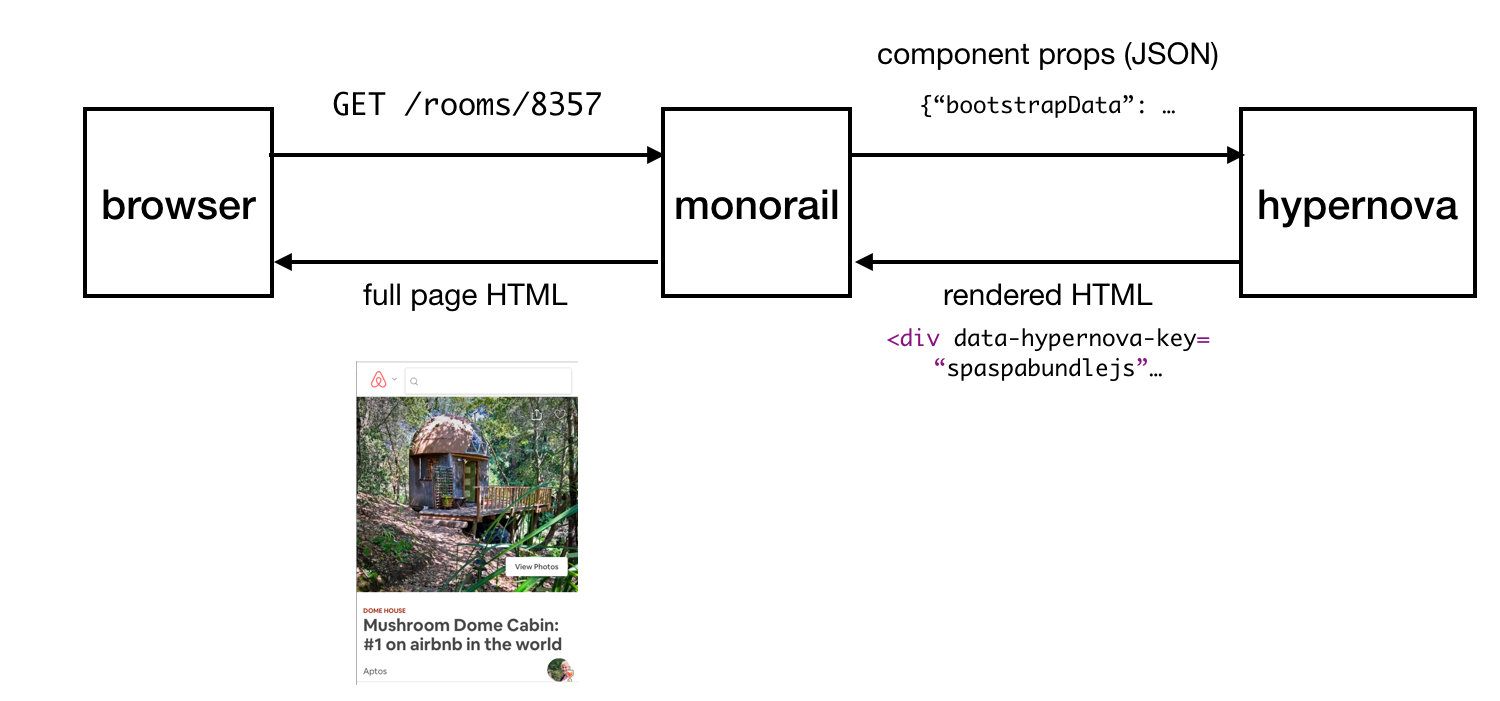
Requests come in from the user to our main Rails app, Monorail, which pieces together the props for the React components it wishes to render on any given page and makes a request with those props and component names to Hypernova. Hypernova renders the components with the props to generate HTML to return to Monorail, which then embeds it into the page template and sends the whole thing back down to the client.

In the case of failure (either due to error or timeout) on hypernova rendering, the fallback is to embed the components and their props on the page without the rendered HTML, allowing them to (hopefully) be client rendered successfully. This has led
us to consider hypernova an optional dependency, and we are able to tolerate some amount of timeouts and failures. We set timeouts on the call to approximately the observed p95 of the service at the time we were tweaking the values. Unsurprisingly,
we were operating with a baseline of just below 5% timeouts.
On deploys during peak daily traffic loads, we would see up to 40% of requests to Hypernova timing out in Monorail. From Hypernova, we would see error rate spikes of a lower
magnitude of BadRequestError: Request aborted on deploys. These errors also existed at a baseline rate that pretty effectively hid all other application/coding errors.

As an optional dependency, this behavior wasn't a high priority and viewed as more of an annoyance. We were reasonably satisfied to explain the timeouts and the errors as the result of slow start behaviors like more expensive initial GC on start, lack of JIT, filling of caches, reticulation of splines, etc. There was hope that new releases of React or Node would provide sufficient performance improvements to mitigate the slow start.
I suspected that this was likely to be the result of bad load balancing or capacity issues during deploys, where we saw increased latency because we were running multiple basically 100% compute requests simultaneously on the same process. I added a middleware to log the number of requests being handled at the same time by any given process, as well as logging any cases where we were running more than one request at a time.
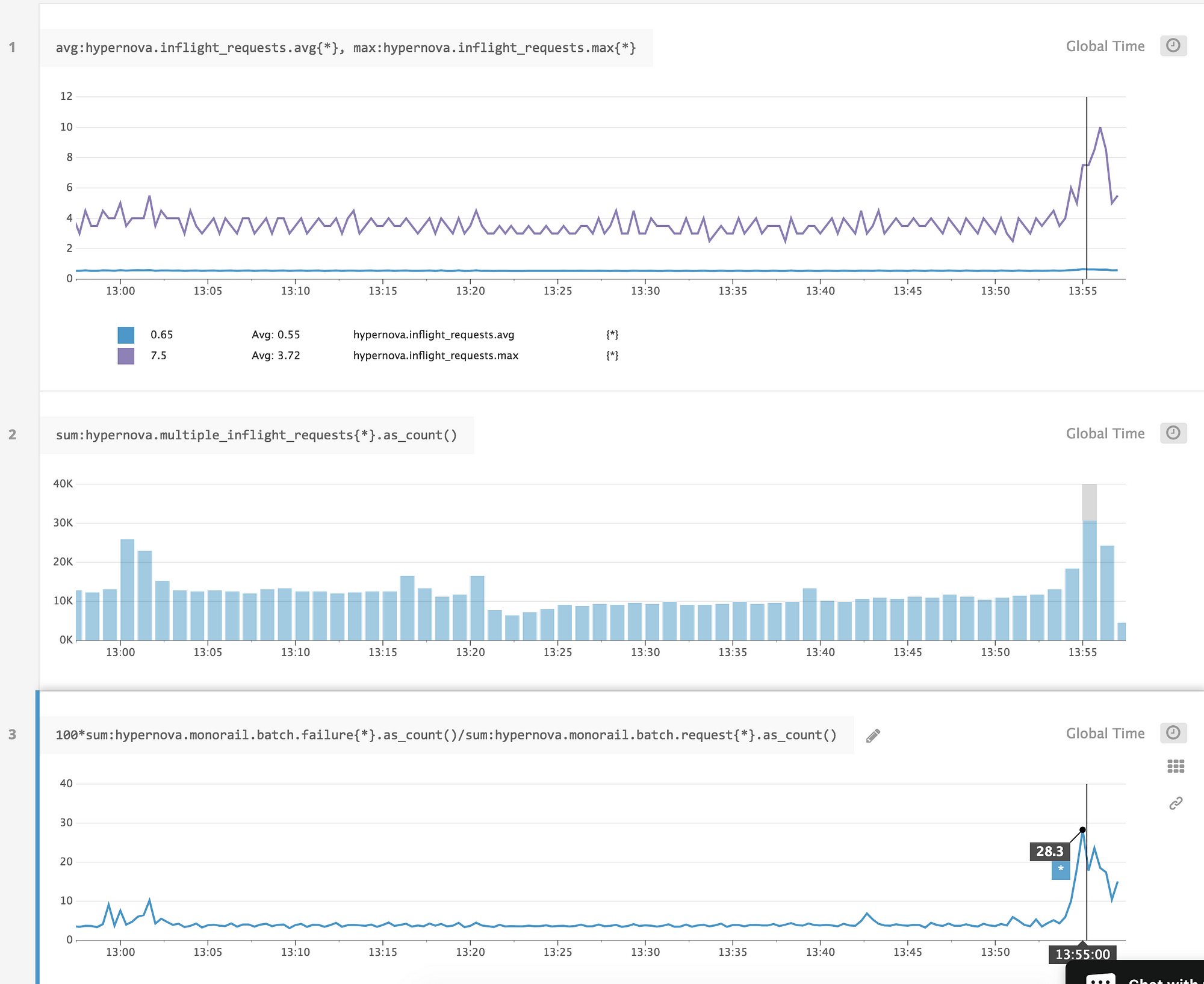
We had blamed startup latency for latency that was actually caused by concurrent requests waiting on each other for use of the CPU. From our performance metrics, time spent waiting to execute because of other running requests is indistinguishable from time spent executing the request. This also means that increased latency from concurrency would appear the same as increased latency from new code paths or features—things that actually increase the cost of any individual request.
It was also becoming more apparent that the BadRequestError: Request aborted error wasn't readily explained by general slow start performance. The error comes from the body parser and specifically happens in the case that the client has
aborted the request before the server has been able to fully read the request body. The client gives up and closes the connection, taking away the precious data that we needed to proceed with processing the request. It's much more likely that
this would happen because we started handling a request, then had our event loop blocked by another request's rendering, and then went back to finish from where we had been interrupted only to find that the client had gone away. The request payloads
for Hypernova are also quite large at a few hundred kilobytes on average, making nothing better.

We decided to solve this by using two off-the-shelf components with which we had a large amount of existing operational experience: a reverse proxy (nginx) and a load balancer (haproxy).
Reverse Proxying and Load Balancing
To take advantage of the multiple CPU cores present on our hypernova instances, we run multiple processes of hypernova via the built in Node.js cluster module. As these are independent processes, we are able to handle concurrent requests in parallel.

The problem here is that each node process is effectively occupied for the entire duration of the request including reading the request body from the client (monorail). While we can read multiple requests in parallel in a single process, this leads to interleaving of compute operations when it comes time to do the render. The utilization of the node processes becomes coupled to the speed of the client and network.
The solution² is to use a buffering reverse proxy to handle communication with the clients. For this, we use nginx. Nginx reads the request from the client into a buffer and passes the full request to the node server only after it has been completely read. This transfer happens locally on the machine over loopback or unix domain sockets, which are faster and more reliable than communication between machines.

With nginx handling reading the requests, we are able to achieve higher utilization of the node processes.

We also use nginx to handle some requests without ever having to go to the Node.js processes. Our service discovery and routing layer uses low cost requests to /ping to check connectivity between hosts. Handling this entirely in nginx
eliminates a substantial source of (albeit cheap) throughput to the Node.js processes.
The next piece is load balancing. We need to make smart decisions about which Node.js processes should receive which requests. The cluster module distributes requests via round-robin³, where each process is given a request⁴ in turn. Round robin is great when there is low variance in request latency like in:
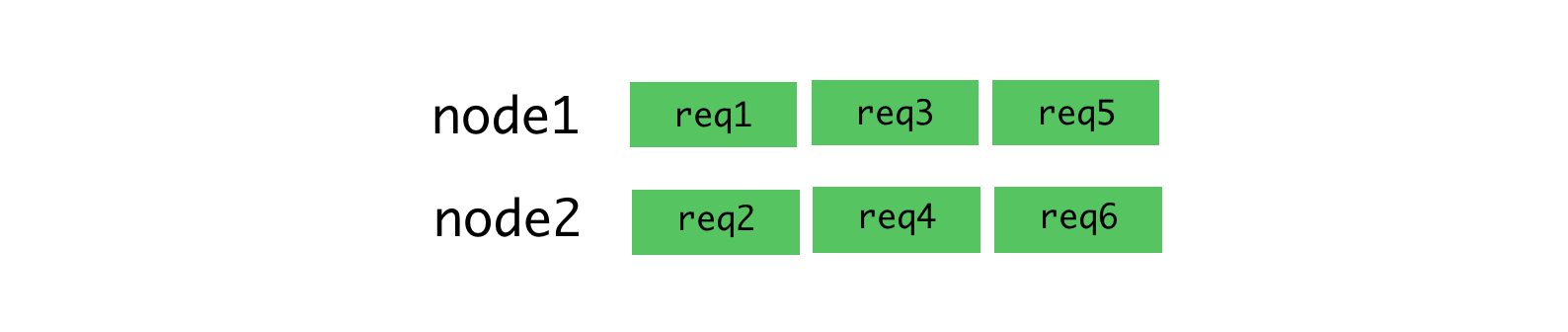
It is less great when there are different types of requests that can take radically different amounts of time to handle. Later requests on a process have to wait for all previous requests to finish, even if there is another process that has capacity to handle them.

A better distribution of these requests would look like this:
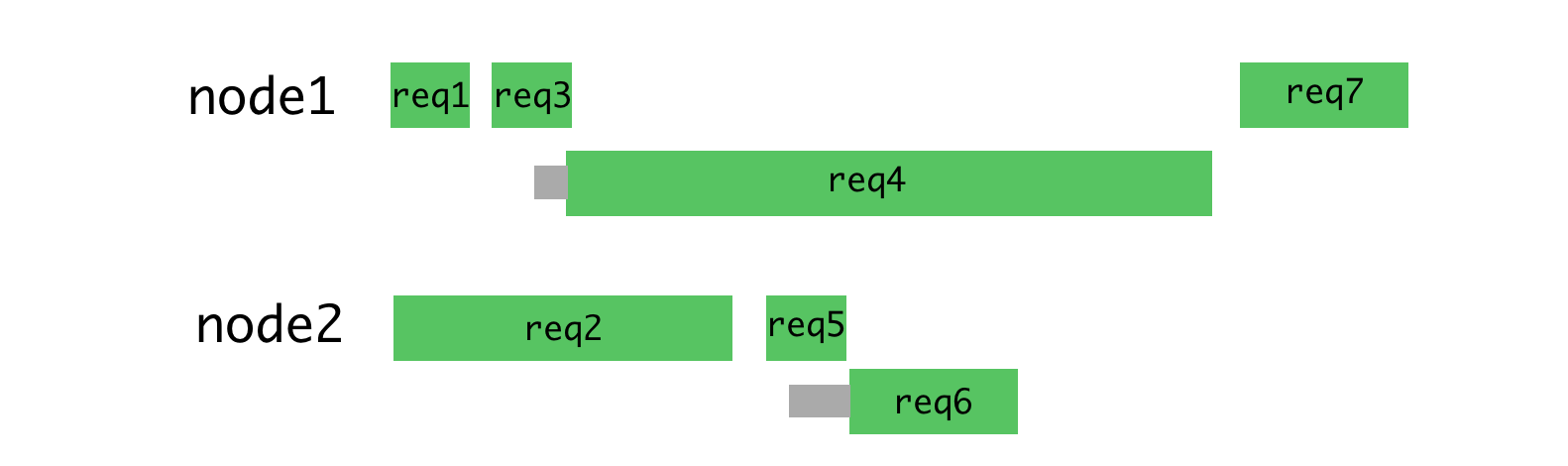
As this minimizes waiting and allows responses to be returned sooner.
This can be achieved by holding requests in a queue and only assigning them to a process once the process is no longer occupied with another request. We use haproxy for this.
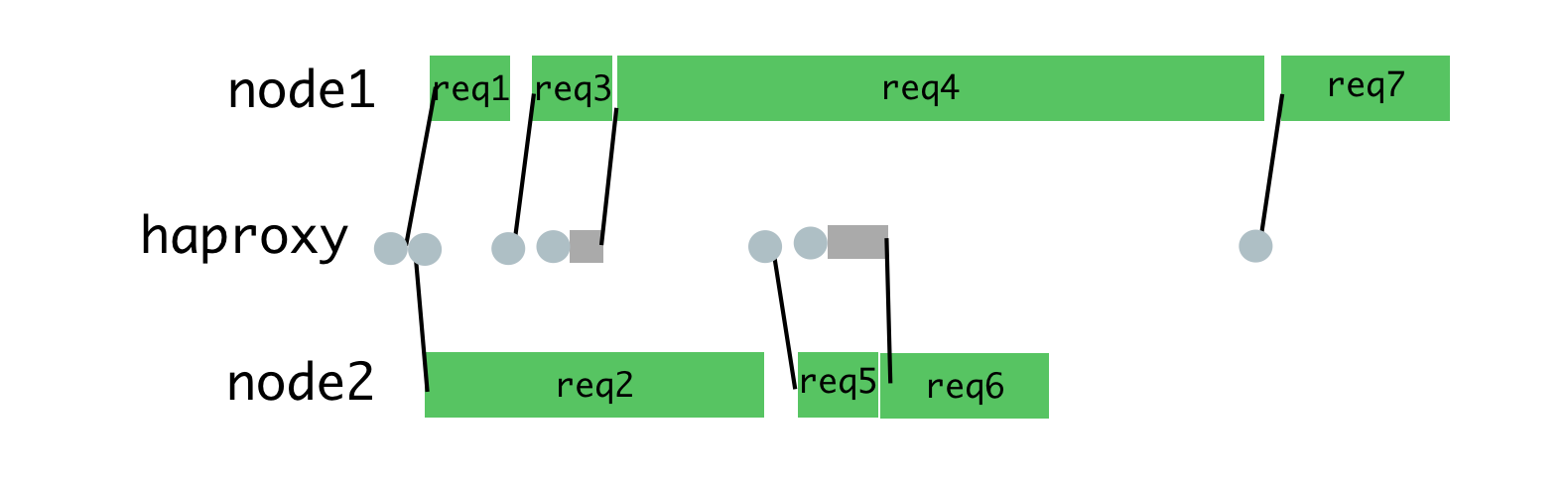
When we put this in place for Hypernova, we entirely eliminated the timeout spikes on deploy as well as the BadRequestErrors. Concurrent requests were also a major driver of high-percentile latency during normal operation, so this
also reduced that latency. One of the consequences of this is that we went from a baseline timeout rate of 5% to a timeout rate of 2% with the same configured timeout. Going from 40% failures during deploy to 2% feels like a win. Today, users
are presented with a blank loading screen far less often. Tomorrow, stability through deploys will be critical for our new renderer, which does not have Hypernova’s error fallback.
Details and Configuration
To set this up required configuring nginx, haproxy, and our node application. I have prepared a sample node app with nginx and haproxy configurations that can be used to understand this setup. These configurations are based on what we run in production, but have been simplified and modified to run in the foreground as an unprivileged user. In production, everything should be configured with your process supervisor of choice (we use runit or, increasingly, kubernetes).
The nginx config is pretty standard, with a server listening on port 9000 configured
to proxy requests to the haproxy listening on port 9001 (in our setup, we use Unix Domain Sockets). It also intercepts the /ping endpoint to serve connectivity checks directly. A departure from our internal standard nginx config
is that we've reduced the worker_processes to 1, as a single nginx process is more than sufficient to saturate our single haproxy process and node application. We are also using large request and response buffers as the props
for our components for hypernova can be quite large (hundreds of kilobytes). You should size your buffers based on your own request/response sizes.
Node's cluster module handles both load balancing and process spawning. To switch to HAProxy for load balancing, we had to create a replacement for the process management parts of cluster. This came together as pool-hall, which is slightly more opinionated about maintaining a pool of worker processes than cluster, but is entirely out of the load balancing game. The example app demonstrates using pool-hall to start four worker processes, each listening on a different port.
The HAProxy config configures a proxy listening on port 9001
that routes traffic to the four workers listening on ports 9002 to 9005. The most important setting is maxconn 1 on each of the workers. This limits each worker to handling one request at a time. This can be seen in the HAProxy
stats page (which is configured to run on port 8999)
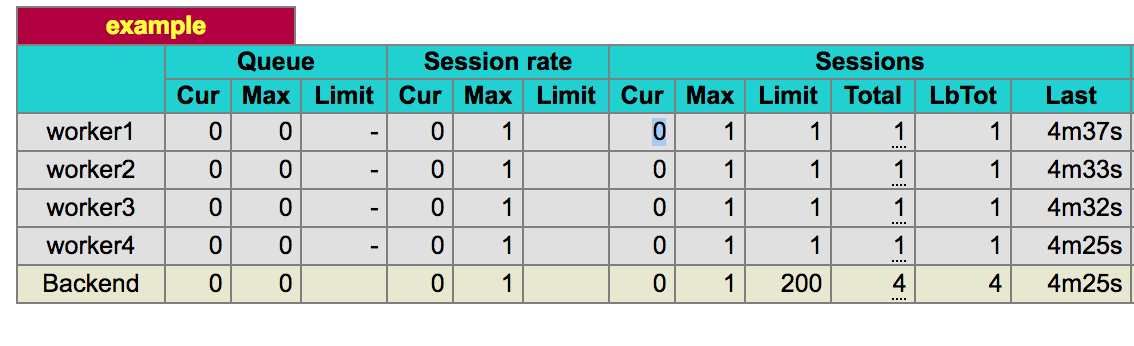
HAProxy tracks how many connections are currently open between it and each worker. It has a limit configured via maxconn. Routing is set to static-rr (static round robin), so ordinarily each worker is given a request
in turn. With the limit set, the routing proceeds with round robin, but skips over any workers that are currently at their limit of requests. If no workers are below their connection limit, the request is queued and will be dispatched to whichever
worker becomes available first. This is the behavior we want.
This configuration is probably pretty close to what you wouldd want to use. There are other interesting settings (as well as the requisite copypasta) in there. As part
of preparing this config, we conducted a number of tests under normal and anomalous conditions and derived configuration values from them. This gets into the weeds and is not strictly necessary to understand to use this set up, but it is presented
in the next section.
HAProxy Deep Dive
There was a lot riding on the HAProxy configuration working exactly as we wanted it to. It would not do us much good if it did not handle concurrent request limiting or queueing the way we expected. It was also important to understand how various
types of failures were handled (or not handled). We needed to develop confidence that this was a suitable replacement for the existing cluster setup. To verify this, we performed a series of tests.
The general shape of the tests was to use ab (Apache Benchmark) to run 10,000 requests at various levels of concurrency like
ab -l -c <CONCURRENCY> -n 10000 http://<HOSTNAME>:9000/render
Our configuration used 15 workers instead of the 4 in the example app, and we ran ab on a separate instance from the instance running the app to avoid interference between the benchmark and the system under test. We ran tests at low
load (concurrency=5), high load (concurrency=13), and queueing load (concurrency=20). Queueing load ensured that haproxy was always running a queue.
The first set of tests were just normal operation, with no funny business. The next set of tests were under graceful restart of all processes as would occur during a deploy. The final set of these tests featured me killing a subset of the processes at random as would occur if uncaught exceptions were to crash a process.
Separately, infinite loops in application code had been problem, so I ran single requests against an endpoint with an infinite loop.
These tests helped shape our configuration as well as our understanding of how it would all work.
In normal operation, maxconn 1 worked exactly as hoped, restricting each process to handling one request at a time. We don't configure HTTP or TCP health checks on backends as we found that this caused more confusion than it was worth.
It seems that health checks do not respect maxconn, though I have not verified this in the code. Our expected behavior is that a process is either healthy and able to serve or is not listening and will immediately give a connection
error (there's one major exception to this). We found these health checks to not be sufficiently controllable to be useful for our case, and elected to avoid the unpredictability of overlapping health checking regimes.
Connection errors are something that we can work with. We set option redispatch and retries 3, which allows requests that receive a connection error to be bounced to a different backend that will hopefully be more forthcoming.
Connection refused comes immediately, allowing us to get along with our business.
This only applies to connections that are refused because we happen to not be listening. The connect timeout is not particularly useful as we are dealing with local network. We initially expected to be able to set a low connect timeout to guard
against workers that have been caught in an infinite loop. We set a timeout of 100ms and were surprised when our requests timed out after 10 seconds, which was the client/server timeout set at the time, even though control never returned to
the event loop to accept the connection. This is explained because the kernel handles getting the connection to established from the client's perspective before the server calls accept.
As an interesting aside, even setting a backlog does not result in a connection not being established as the backlog length is evaluated after the server responds SYN-ACK (and is actually implemented/handled by the server dropping the ACK response back from the client). One important consequence of
this is that requests that have had their connections established cannot be redispatched/retried as we have no way to tell whether the backend processed the request or not.
Another interesting result from our tests on processes caught in infinite compute loops was that the client/server timeouts allow for some unexpected behavior. When a request has been sent to a process that causes it to enter into an infinite
loop, the backend's connection count is set to 1. With maxconn, this does what we want and prevents any other requests from falling into the tar pit. The connection count is decremented back to 0 after the client/server timeout
expires, which allows our one-in-one-out guarantee to be violated and also dooms the poor next request to failure. When a client closes the connection because of timeout or caprice, the connection count is not effected and our routing still
continues to work. Setting abortonclose causes the connection count to decrement as soon as the client closes. Given this, the best course of action is to set a high value for these timeouts and keep abortonclose off. Tighter timeouts can be set on the client or nginx side.
We also found a rather ugly attractor that applies in cases of high load. If a worker process crashes (which should be very rare) while the server has a steady queue, requests will be tried on that backend, but will fail to connect as there is
no process listening. HAProxy will then redispatch to the next backend with an open connection slot, which will be only the backend that previously failed (as all other backends are busy actually working). This will quickly burn through the
retries and result in a failed request because connection errors are way faster than rendering HTML. The process will repeat on the rest of the requests until the queue is completely drained. This is bad, but it is mitigated by the rareness
of process crashes, the rareness of running sustained queues (if you are constantly queuing, you are under-provisioned), and, in our specific case, the fact that this failure attractor would also attract our service discovery health checks,
quickly marking the entire instance as unhealthy and ineligible for new requests. This is not great, but it minimizes the danger. Future work could handle this through deeper HAProxy integration where the supervisor process observes the process's
exit and marks it as MAINT via the haproxy stats socket.
Another change worth noting is that server.close in node waits for existing requests to complete, but anything in the HAProxy queue will fail as the server does not know to wait for requests it has not yet received. Ensuring sufficient
drain time between when an instance stops receiving requests and when it starts the server restart process should cover this in most cases.
We also found that setting balance first , which directs most traffic to the first available worker in order (basically saturating worker1) reduced latency on our app by 15% under both synthetic and production load
vs. balance static-rr. This effect was long lived and beyond what would be easily explained by warm up. This lasted for hours after deploy. Performance degraded over longer periods of time (12 hours), likely because of memory
leaks on the hot process. This was also less resilient to spikes in traffic as the cold processes were extremely cold. We still do not have a great explanation for this.
Finally, Node's server.maxConnections setting seemed like it would be helpful here (it certainly did to me), but we found that it did not really provide much utility and did cause errors at times. This setting prevents the server
from accepting more than maxConnections by closing any new handles after seeing that it's above the limit. This check is applied in JavaScript, so it does not guard against the infinite loop case (we will correctly abort the request
once we return to the event loop…wait). We also saw connection errors caused by it under normal operations, even as we saw no other evidence of multiple requests running. We suspect this is a slight timing issue or difference of opinion between
haproxy and Node about when a connection begins and ends. The desire to have an application side guarantee of mutual exclusion is a good one as this allows developers to safely use singletons or other global state. This can be handled by implementing
a per-process queue as an express middleware.
Conclusion
Server side rendering represents a different workload from the canonical, mostly I/O workload that node excels at. Understanding the cause of anomalous behavior allowed us to address it with off the shelf components with which we had existing operational experience.
We are investing heavily in building a world class Frontend experience at Airbnb. If you enjoyed reading this and thought this was an interesting challenge, we are always looking for talented, curious people to join the team. We would love to hear from you!
Thanks to Brian Wolfe, Joe Lencioni, and Adam Neary for reviewing and iterating on this post.
Footnotes
- The resource contention is still present for asynchronous rendering. Asynchronous rendering addresses responsiveness of the process or browser, but does not address parallelism or latency. This blog post will focus on a simple model of pure compute workloads. With mixed workloads of IO and compute, request concurrency will increase latency, but with the benefit of allowing higher throughput.
- Inspired by the unicorn web server we use to serve our Rails applications. The Philosophy Behind unicorn articulates the why particularly well.
- Mostly, with some attempt to route around non-responsive processes
clusterdistributes connections, not requests, so this behaves differently, and worse, when persistent connections are used. Any persistent connection from the client is bound to a single specific worker process, which makes it even harder to distribute work efficiently.
