

最近在搜索更详细的关于JS事件处理的资料。发现国内的大部分blog都是相互抄袭。而MDM对于这里的解释也并不多。翻阅了部分文章,发现这篇文章很有价值。故译之。虽然文章写于2013年,但是依然具有很高参考价值
原文:The JavaScript Event Loop: Explained
这篇文章是讲什么的?
对于目前Web浏览器上最流行的脚本语言JavaScript。这篇文章为你提供了该语言基本的事件驱动模型的讲解,它与那些典型的有求必应的语言比如Ruby, Python, Java不同。在这篇文章中,我会为你解释这些JavaScript中并发模型的核心概念,包括事件循环,消息队列来帮助你提高对这门已经使用过,但是还没有彻底理解的语言更深入的理解。
谁适合读这篇文章?
这篇文章面向那些已经开始似乎用JavaScript语言从事Web开发的工程师,或者是计划从事这项工作的人员。如果你已经非常熟悉JavaScript的事件循环机制,那么你会觉得这篇文章的内容对于你来说已经再熟悉不过了。对于那些没有对事件循环充分了解的人,我希望这篇文章能够帮助到你,这样才能让你更好的理解你每天面对的代码。
非阻塞 I/O(Non-blocking I/O)
再JavaScript几乎所有的I/O都是非阻塞的。包括HTTP请求,数据访问,读写磁盘。一个单线程在运行时去处理这些操作,提供一个回调函数,然后接着去做其它的事情。当操作完成了,这个回调函数提供的消息会被推送到队列中。在某个时间点,消息从队列中被移除,紧接着回调函数就被触发了。
虽然这个交互模型对于很多开发者来说已经非常熟悉了 -- 比如 mousedown 和 click 事件的处理,- 但是这与那种典型服务器端同步的请求处理不同。
让我们对比一下向 www.google.com 发出请求后将返回的代码输出到控制台。首先,Ruby 的话:
response = Faraday.get 'http://www.google.com'
puts response
puts 'Done!'
执行路径大概是这个样子的:
get方法被执行,然后执行线程开始等待,直到收到响应- 从
Google收到响应并且返回到回调并存储到一个变量中 - 变量的值(返回的响应结果)输出到控制台中
Done被输出到控制台
让我们利用 Node.js 中完成一样的事情看看:
request('http://www.google.com', function(error, response, body) {
console.log(body);
});
console.log('Done!');
看起来一个显著的不同和不同的行为:
- 请求函数被执行,传递一个匿名函数作为一个回调执行函数,在收到响应后执行
Done被马上输出到控制套- 有时候,响应返回了,我们的回调函数也执行力,响应的主体被输出到了控制台
事件循环
将请求的响应以回调函数的方式处理,允许 JavaScript在等待异步操作成功返回并执行回调函数之前可以做一些其他的事情。但是,在内存中怎么执行这些回调的呢?执行顺序是什么样的呢?什么导致他们被调用的呢?
JavaScript 的运行环境有一个用于存储消息和用于关联回调函数的消息队列。这些消息以事件被注册的顺序进行排列(比如鼠标点击事件或者是 HTTP 请求响应事件)。比如用户点击一个按钮,如果没有该事件的回调函数被注册,那么就没有消息加入队列。
在循环中,队列轮询下一个消息(每一次轮询被当作是一个 tick),如果有消息,那么就执行消息对应的回调。
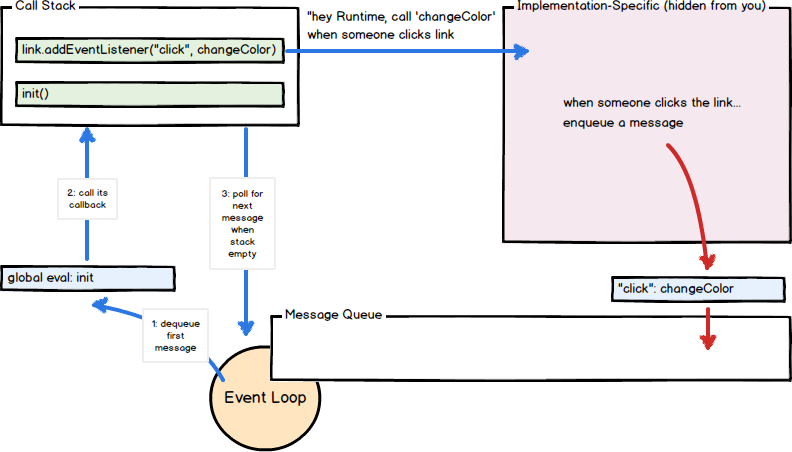
回调函数的调用作为调用堆栈的初始帧,由于JavaScript是单线程的,消息轮询和处理会被停止,直到堆栈内的回调函数全部返回。后续函数调用(同步)向堆栈添加新的调用(例如初始化颜色)。
function init() {
var link = document.getElementById("foo");
link.addEventListener("click", function changeColor() {
this.style.color = "burlywood";
});
}
init();
在这个例子中,当用户点击页面元素,然后一个onclick 事件被触发,一个消息被压入队列中。当消息被压入队列,他的回调函数changeColor被执行。当changeColor返回的时候(也可能是抛出异常),事件循环就继续执行。只要changeColor被指定为onclick的回调函数,后面在该元素的点击会导致更多的消息(以及相关changeColor回调的消息)被压入队列。
队列中的额外消息
如果函数在你的代码中被异步调用(比如 setTimeout),在之后的事件循环中,回调函数会以另一个消息队列的一部分被执行。比如:
function f() {
console.log("foo");
setTimeout(g, 0);
console.log("baz");
h();
}
function g() {
console.log("bar");
}
function h() {
console.log("blix");
}
f();
由于setTimeout是非阻塞的,它会在0毫秒后被执行,并且并不是作为此消息的一部分被处理。在这个例子中,setTimeout被调用,传入一个回调函数 g 和 一个超时事件 0 毫秒。当时间到了以后,一个以g为回调函数的消息将会被压入队列中。控制台会输出类似: foo, baz, blix 然后在下一次事件循环输出: bar。如果在同一个调用帧中(译者注:就是一个函数内)执行了两次 setTimeout,传入相同的值(译者注: 时间间隔)。他们会按照先后顺序执行。
Web Workers
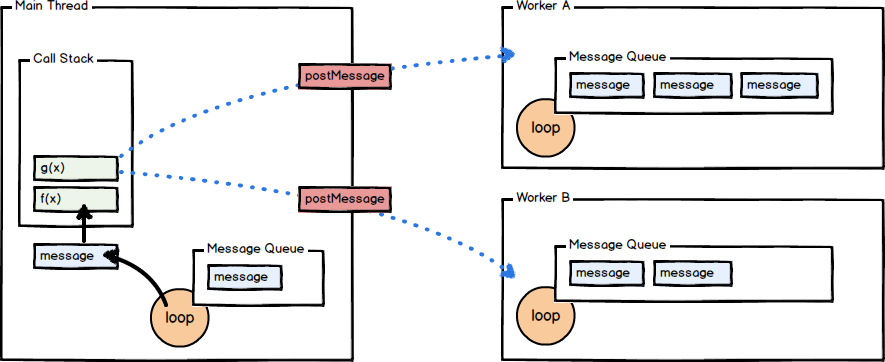
Web Worker 允许你将昂贵的操作转入到独立到线程中执行,节约主要线程去做其它事情。worker具有独立的消息队列,事件循环,和独立的内存空间。worker 与主线程通过消息来完成通讯,这看起来有点像之前的事件处理那样。
首先,我们的 worker:
// our worker, which does some CPU-intensive operation
var reportResult = function(e) {
pi = SomeLib.computePiToSpecifiedDecimals(e.data);
postMessage(pi);
};
onmessage = reportResult;
然后是我们的js代码:
// our main code, in a <script>-tag in our HTML page
var piWorker = new Worker("pi_calculator.js");
var logResult = function(e) {
console.log("PI: " + e.data);
};
piWorker.addEventListener("message", logResult, false);
piWorker.postMessage(100000);
在这个例子中,主线程衍生并启动一个worker,然后并将logResult这个回调加入到事件循环。在worker中,reportResult被注册到自己的message事件中。当worker从主线程接收到消息,worker就会返回一个消息,因此就会导致reportResult被执行。
当进行压栈的时候,一个消息会被推送到主线程,并被压入消息堆栈(然后执行回调函数)。通过这个方式,开发人员可以将cpu密集型操作委托给独立的线程,释放主线程去继续处理消息和事件。
关于闭包
JavaScript支持在回调函数中使用闭包,该回调在执行时维持对创建它们的环境的访问,即使回调执行完创建了新的调用堆栈。对于知道回调是以不同的消息被执行的要比知道回调被创建更有趣。思考下面的代码:
function changeHeaderDeferred() {
var header = document.getElementById("header");
setTimeout(function changeHeader() {
header.style.color = "red";
return false;
}, 100);
return false;
}
changeHeaderDeferred();
这个例子中,changeHeaderDeferred执行的时候包含了header变量。setTimeout被执行,100毫秒后一个消息被添加到消息队列中。changeHeaderDeferred函数返回了false,结束了这次处理 - 但是回调函数中依然保留着header的引用,所以没有被垃圾回收。当第二个消息被处理的时候,函数体外(changeHeaderDeferred)它依然保持这对header的声明。第二次处理完后,header才被垃圾回收处理。
