

基本概念
检索是在一组记录集合中找到关键码值等于 给定值的某个记录,或者找到关键码 值符合特定条件的某些记录的过程。
检索的效率非常重要
- 尤其对于大数据量
- 需要对数据进行特殊的存储处理
提高检索效率的方法
- 预排序
- 建立索引
- 空间换时间
- 散列技术
- 当散列方法不适合于基于磁盘的应用 程序时,我们可以选择 B 树方法
平均检索长度(ASL)
- 关键码的比较:检索运算的主要操作
- 平均检索长度(Average Search Length)
- 检索过程中对关键码的平均比较次数
- 衡量检索算法优劣的时间标准
- ASL = 单个检索元素出现的概率X检索长度 的总合
线性表的检索
顺序检索
- 针对线性表里的所有记录,逐个进行关键 码和给定值的比较
- 若某个记录的关键码和给定值比较相等,则 检索成功
- 否则检索失败(找遍了仍找不到)
- 存储:可以顺序、链接
- 排序要求:无
template <class Type>
class Item {
private:
Type key;
public:
Item(Type value):key(value) {} Type getKey() {return key;}
void setKey(Type k){ key=k;}
};
vector<Item<Type>*> dataList;
template <class Type> int SeqSearch(vector<Item<Type>*>& dataList, int length, Type k) {
int i=length;
dataList[0]->setKey (k); // 将第0个元素设为待检索值,设监视哨
while(dataList[i]->getKey()!=k) i--;
return i;
}
顺序检索优缺点
- 优点:插入元素可以直接加在表尾 Θ(1)
- 缺点:检索时间太长 Θ(n),成功(n+1)/2,失败n+1(设置了监视哨)
二分检索
template <class Type> int BinSearch (vector<Item<Type>*>& dataList, int length, Type k){
int low=1, high=length, mid;
while (low<=high) {
mid=(low+high)/2;
if (k<dataList[mid]->getKey())
high = mid-1;
else if (k>dataList[mid]->getKey())
low = mid+1;
else return mid;
}
return 0;
}
二分法检索性能分析
- 成功/失败的平均检索长度为:log(n+1)
- 优点:平均与最大检索长度相近,检索速度快
- 缺点:要排序、顺序存储,不易更新(插/删)
分块检索思想
- “按块有序”
- 设线性表中共有 n 个数据元素,将表分成b块
- 前一块最大关键码必须小于后一块最小关键码
- 每一块中的关键码不一定有序
- 顺序与二分法的折衷
- 既有较快的检索
- 又有较灵活的更改
分块检索性能分析
- 当块内元素数目s=根号n时,性能最佳,ASL = 根号n
- 优点:
- 插入、删除相对较易
- 没有大量记录移动
- 缺点:
- 增加一个辅助数组的存储空间
- 初始线性表分块排序
- 当大量插入/删除时,或结点分布不均匀时, 速度下降
- 当 n=10,000 时
- 顺序检索 5,000 次
- 二分法检索 14 次
- 分块检索 100 次
集合的检索
集合的检索:确定一个值是不是某个集合的元素
用位向量来表示集合bitset
对于密集型集合(数据范围小,而集合中有效元素个数比较多)
bitset设置集合元素
typedef unsigned long ulong; enum {
// unsigned long数据类型的位的数目
NB = 8 * sizeof (ulong),
// 数组最后一个元素的下标
LI = N == 0 ? 0 : (N - 1) / NB
};
ulong A[LI + 1];// 存放位向量的数组
template<size_t N>
mySet<N>& mySet<N>::set(size_t P, bool X) {
if (X) // X为真,位向量中相应值设为1
A[P / NB] |= (ulong)1 << (P % NB);
// P对应的元素进行按位或运算
else A[P / NB] &= ~((ulong)1 << (P % NB)); // X为假,位向量中相应值设为0
return (*this);
}
bitset集合的交运算“&”
template<size_t N>
mySet<N>& mySet<N>::operator&=(const mySet<N>& R) { // 赋值交
for (int i = LI; i >= 0; i--) A[i] &= R.A[i];
return (*this);
}
// 从低位到高位
// 以ulong元素为单位按位交
template<size_t N>
mySet<N> operator&(const mySet<N>& L, const mySet<N>& R) { //交
return (mySet<N>(L) &= R);
}
集合其他表示法
红黑树(后面会讲)
查阅Bloom Filter(布隆过滤器)的应用
散列表的检索
- 当检索是直接面向用户的操作时,问题规模 n 很大时,上述两种检索的时间效率可能 使得用户无法忍受
- 最理想的情况
- 根据关键码值,直接找到记录的存储地址(类似于数组下标)
- 受此启发,计算机科学家发明了散列方法(Hash, 有人称“哈希”)
- 不需要把待查关键码与候选记录集合的某些记录进 行逐个比较
- 根据关键码值,直接找到记录的存储地址(类似于数组下标)
散列函数
- 散列函数:把关键码值映射到存储位置的函数, 通常用 h 来表示
- Address = Hash ( key )
- 散列函数的选取原则
- 运算尽可能简单
- 函数的值域必须在表长的范围内
- 尽可能使得关键码不同时,其散列函数值亦不相同
几个重要概念
- 负载因子 α=n/m
- 散列表的空间大小为 m
- 填入表中的结点数为 n
- 冲突
- 某个散列函数对于不相等的关键码计算出了相同的散列地址
- 在实际应用中,不产生冲突的散列函数极少存在
- 同义词
- 发生冲突的两个关键码
常用散列函数选取方法
1. 除余法
- 除余法:用关键码 x 除以 M (往往取散列表长 度),并取余数作为散列地址。
- 散列函数为: h(x) = x mod M
- 通常选择一个质数作为 M 值
- 函数值依赖于自变量 x 的所有位,而不仅仅是最右边 k 个低位
- 增大了均匀分布的可能性
- 例如,4093
2. 乘余取整法
- 先让关键码 key 乘上一个常数 A (0<A<1),提取乘积的小数部分
- 例如 A = 0.6180339(黄金分割)
- 然后,再用整数 n 乘以这个值,对结果向下取 整,把它作为散列地址
- 散列函数为:
- hash ( key ) = [n * ( A * key % 1 ) ]
- “A * key % 1”表示取 A * key 小数部分:
- A * key % 1 = A * key - [A * key]
3. 平方取中法
先通过求关键码的平方来扩大差别,再取其中的几位或其组合作为散列地址
- 例如,
- 一组二进制关键码:(00000100,00000110,000001010,000001001,000000111)
- 平方结果为:(00010000,00100100,01100010,01010001,00110001)
- 若表长为 4 个二进制位,则可取中间四位作为散列地址:(0100,1001,1000,0100,1100)
4. 数字分析法
- 设有 n 个 d 位数,每一位可能有 r 种不同的 符号
- 这 r 种不同的符号在各位上出现的频率不一定 相同
- 可能在某些位上分布均匀些,每种符号出现的几率 均等
- 在某些位上分布不均匀,只有某几种符号经常出现
- 可根据散列表的大小,选取其中各种符号分布均匀的若干位作为散列地址
- 数字分析法仅适用于事先明确知道表中所有关键码每一位数值的分布情况
- 它完全依赖于关键码集合
- 如果换一个关键码集合,选择哪几位数据要重新决定
5. 基数转换法
- 把关键码看成是另一进制上的数后
- 再把它转换成原来进制上的数
- 取其中若干位作为散列地址
- 一般取大于原来基数的数作为转换的基数,并且两个基数要互素
- 例如,给定一个十进制数的关键码是(210485)10,把 它看成以 13 为基数的十三进制数 (210485)13 ,再把 它转换为十进制
6. 折叠法
- 关键码所含的位数很多,采用平方取中法计算太复杂
- 折叠法
- 将关键码分割成位数相同的几部分(最后一部分的位数可 以不同)
- 然后取这几部分的叠加和(舍去进位)作为散列地址
- 两种叠加方法:
- 移位叠加 — 把各部分的最后一位对齐相加
- 分界叠加 — 各部分不折断,沿各部分的分界来回折叠,然 后对齐相加,将相加的结果当做散列地址
7. ELFhash字符串散列函数
- 用于 UNIX 系统 V4.0 “可执行链接格式”( Executable and Linking Format,即ELF )
int ELFhash(char* key) {
unsigned long h = 0;
while(*key) {
h = (h << 4) + *key++;
unsigned long g = h & 0xF0000000L;
if (g) h ^= g >> 24;
h &= ~g;
}
return h % M;
}
ELFhash函数特征
- 长字符串和短字符串都很有效
- 字符串中每个字符都有同样的作用
- 对于散列表中的位置不可能产生不平均的分布
散列函数的碰撞处理
开散列法
- 表中的空单元其实应该有特殊值标 记出来
- 例如 -1 或 INFINITY
- 或者使得散列表中的内容就是指针,空单元则内容为空指针
- 把相同的hash值的不同key指向一个链表
闭散列方法
- d0=h(K)称为 K 的基地址
- 当冲突发生时,使用某种方法为关键码K生成一个散列地址序列d1,d2,... di ,... , dm-1
- 所有 di (0<i<m) 是后继散列地址
- 形成探查的方法不同,所得到的解决冲突的方法也不同
- 插入和检索函数都假定每个关键码的探查序列中至少有一个存储位置是空的
- 否则可能会进入一个无限循环中
- 也可以限制探查序列长度
可能产生的问题——聚集
- “聚集”(clustering,或称为“堆积”)
- 散列地址不同的结点,争夺同一后继散列地址
- 小的聚集可能汇合成大的聚集
- 导致很长的探查序列
几种常见的闭散列方法
- 线性探查
- 二次探查
- 伪随机数序列探查
- 双散列探查法
1.线性探查
基本思想:
- 如果记录的基位置存储位置被占用,那么就在表中 下移,直到找到一个空存储位置
- 依次探查下述地址单元:d+1,d+2,......,M-1,0, 1,......,d-1
- 用于简单线性探查的探查函数是: p(K,i) = i
- 线性探查的优点
- 表中所有的存储位置都可以作为插入新记录的候选位置
2. 二次探查
-
探查增量序列依次为:12,-12,22 ,-22,..., 即地址公式是 d2i-1 = (d +i2) % M d2i = (d – i2) % M • 用于简单线性探查的探查函数是 p(K,2i-1) = ii p(K,2i) = - ii
-
例:二次探查 使用一个大小 M = 13的表
- 假定对于关键码 k1 和 k2,h(k1)=3,h(k2)=2
- 探查序列
- k1的探查序列是 3、4、2、7 、...
- k2的探查序列是 2、3、1、6 、...
- 尽管 k2 会把 k1 的基位置作为第 2 个选择来探查, 但是这两个关键码的探查序列此后就立即分开了
3. 伪随机数序列探查
• 探查函数 p(K,i) = perm[i - 1]
- 这里perm是一个长度为M–1的数组
- 包含值从1到M–1的随机序列
// 产生n个数的伪随机排列
void permute(int *array, int n) {
for(int i=1; i<=n; i++)
swap(array[i-1], array[Random(i)]);
}
上述三种探查方法的问题-二级聚集
- 消除基本聚集
- 基地址不同的关键码,其探查序列有所重叠
- 伪随机探查和二次探查可以消除
- 二级聚集 (secondary clustering)
- 两个关键码散列到同一个基地址,还是得到同样的 探查序列,所产生的聚集
- 原因探查序列只是基地址的函数,而不是原来关键 码值的函数
- 例子:伪随机探查和二次探查
4. 双散列探查法
- 避免二级聚集
- 探查序列是原来关键码值的函数 ,而不仅仅是基位置的函数
- 双散列探查法
- 利用第二个散列函数作为常数
- p(K, i) = i * h2 (key)
- 探查序列函数
- d = h1(key)
- di = (d + i h2 (key)) % M
- 优点:不易产生“聚集”
- 缺点:计算量增大
M 和 h2(k) 选择方法
- 方法1:选择 M 为一个素数,h2 返回的值在 1 ≤ h2(K) ≤ M – 1范围之间
- 方法2:设置 M = 2m,让 h2 返回一个 1 到 2m 之间 的奇数值
- 方法3:若 M 是素数,h1(K) = K mod M
- h2 (K) = K mod(M-2) + 1
- 或者h2(K) = [K / M] mod (M-2) + 1
- 方法4: 若 M 是任意数,h1(K) = K mod p,( p 是 小于 M 的最大素数)
- h2 (K) = K mod q + 1 ( q 是小于 p 的最大素数)
闭散列表检索的算法实现
字典 (dictionary)
- 一种特殊的集合,其元素是(关键码,属性值)二元组。
- 关键码必须是互不相同的(在同一个字典之内)
- 主要操作是依据关键码来插入和查找
散列字典ADT(属性)
template <class Key,class Elem,class KEComp,class
EEComp> class hashdict {
private:
Elem* HT;//散列表
int M;//散列表大小
int currcnt;// 现有元素数目
Elem EMPTY;
int h(int x) const ; //数字散列函数
int h(char* x)const ; // 字符串散列函数
int p(Key K,int i);
public:
hashdict(int sz,Elem e) { // 构造函数
M=sz; EMPTY=e;
currcnt=0; HT=new Elem[sz];
for (int i=0; i<M; i++) HT[i]=EMPTY;
}
~hashdict() { delete [] HT; }
bool hashSearch(const Key&,Elem&) const;
bool hashInsert(const Elem&);
Elem hashDelete(const Key& K);
int size() { return currcnt; } // 元素数目
};
插入算法
散列函数 h,假设给定的值为 K
- 若表中该地址对应的空间未被占用,则把待插入记录填 入该地址
- 如果该地址中的值与 K 相等,则报告“散列表中已有 此记录”
- 否则,按设定的处理冲突方法查找探查序列的下一个地 址,如此反复下去
- 直到某个地址空间未被占用(可以插入)
- 或者关键码比较相等(不需要插入)为止
// 将数据元素e插入到散列表 HT
template <class Key, class Elem, class KEComp, class EEComp>
bool hashdict<Key, Elem, KEComp, EEComp>::hashInsert(const Elem& e)
{
int home= h(getkey(e)); // home 存储基位置 int i=0;
int pos = home; // 探查序列的初始位置
while (!EEComp::eq(EMPTY, HT[pos])) {
if (EEComp::eq(e, HT[pos])) return false;
i++;
pos = (home+p(getkey(e), i)) % M; //探查
}
HT[pos] = e;
return true;
}
检索算法
- 与插入过程类似
- 采用的探查序列也相同
- 假设散列函数 h,给定的值为 K
- 若表中该地址对应的空间未被占用,则检索失败
- 否则将该地址中的值与 K 比较,若相等则检索成功
- 否则,按建表时设定的处理冲突方法查找探查序列 的下一个地址,如此反复下去
- 关键码比较相等,检索成功
- 走到探测序列尾部还没找到,检索失败
template <class Key, class Elem, class KEComp, class EEComp> bool hashdict<Key, Elem, KEComp, EEComp>:: hashSearch(const Key& K, Elem& e) const {
int i=0, pos= home= h(K);
while (!EEComp::eq(EMPTY, HT[pos])) {
if (KEComp::eq(K, HT[pos])) {
e = HT[pos];
return true;
}
i++;
pos = (home + p(K, i)) % M;
} // while
return false;
}
删除
- 删除记录的时候,有两点需要重点考虑:
- (1) 删除一个记录一定不能影响后面的检索
- (2) 释放的存储位置应该能够为将来插入使用
- 只有开散列方法(分离的同义词子表)可以真 正删除
- 闭散列方法都只能作标记(墓碑),不能真正 删除
- 若真正删除了探查序列将断掉
- 检索算法 “直到某个地址空间未被占用(检索失败)”
- 墓碑标记增加了平均检索长度
- 若真正删除了探查序列将断掉
墓碑
- 设置一个特殊的标记位,来记录散列表中的单元状态
- 单元被占用
- 空单元
- 已删除
- 被删除标记值称为 墓碑 ( tombstone )
- 标志一个记录曾经占用这个槽
- 但是现在已经不再占用了
带墓碑的删除算法
template <class Key, class Elem, class KEComp, class EEComp>Elem hashdict<Key,Elem,KEComp,EEComp>::hashDelete(const Key& K)
{
int i=0, pos = home= h(K);
while (!EEComp::eq(EMPTY, HT[pos])) {
if (KEComp::eq(K, HT[pos])){
temp = HT[pos];
HT[pos] = TOMB; //设置墓碑
return temp;
}
i++;
pos = (home + p(K, i)) % M;
}
return EMPTY; }
带墓碑的插入操作
- 在插入时,如果遇到标志为墓碑的槽,不可以把新记录存储在该槽中吗
- 避免插入两个相同的关键码
- 检索过程仍然需要沿着探查序列下去,直到找到一个真正的空位置
带墓碑的插入操作改进版
template <class Key, class Elem, class KEComp, class EEComp> bool hashdict<Key, Elem, KEComp, EEComp>::hashInsert(const Elem &e) {
int insplace, i = 0, pos = home = h(getkey(e));
bool tomb_pos = false;
while (!EEComp::eq(EMPTY, HT[pos])) {
if (EEComp::eq(e, HT[pos])) return false;
if (EEComp::eq(TOMB, HT[pos]) && !tomb_pos)
{
insplace = pos;
tomb_pos = true;
}
pos = (home + p(getkey(e), ++ i)) % M; //有墓碑,找下一个
}
if (!tomb_pos) insplace=pos;
HT[insplace] = e;
return true;
}
散列方法的效率分析
- 衡量标准:插入、删除和检索操作 所需要的记 录访问次数
影响检索的效率的重要因素
- 散列方法预期的代价与负载因子 α= N/M 有关
- α 较小时,散列表比较空,所插入的记录比较容易 插入到其空闲的基地址
- α 较大时,插入记录很可能要靠冲突解决策略来寻 找探查序列中合适的另一个槽
- 随着 α 增加,越来越多的记录有可能放到离其 基地址更远的地方
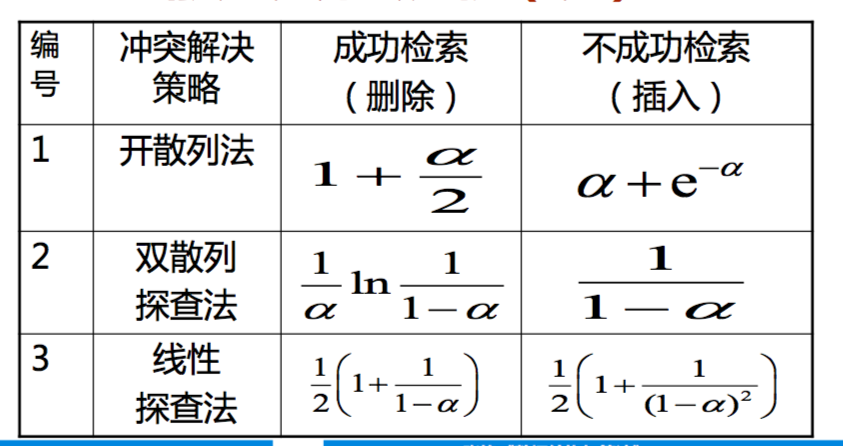
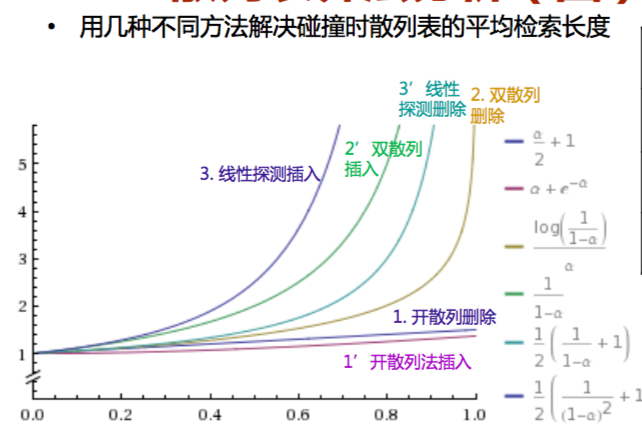
- 实际经验也表明散列表负载因子的临界值是 0.5(将近半满)
- 大于这个临界值,性能就会急剧下降
散列表算法分析结论(2)
- 散列表的插入和删除操作如果很频繁,将降低散列表的检索效率
- 大量的插入操作,将使得负载因子增加,从而增加了同义词子表的长度,即增加了平均检索长度
- 大量的删除操作,也将增加墓碑的数量,这将增加记录本身到其基地址的平均长度
- 实际应用中,对于插入和删除操作比较频繁的散列表,可以定期对表进行重新散列
- 把所有记录重新插入到一个新的表中
- 清除墓碑
- 把最频繁访问的记录放到其基地址
