

本文首发自集智专栏
过拟合可能是机器学习中最烦人的问题。下面我们就谈谈什么是过拟合?怎么发现过拟合?以及防止出现过拟合的6种方法。
什么是过拟合?
过拟合是指模型为了得到一致假设而使假设变得过于严格,也就是说模型对训练数据的学习有点过头。模型并没有学习数据的整体分布,而是学习了每个数据点的预期输出。
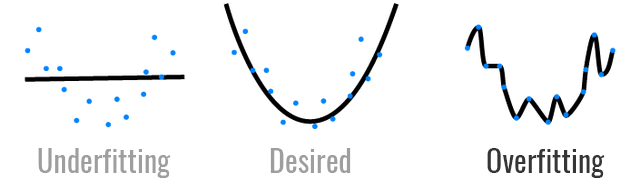
这就好比你在做数学题的时候,你只记准了某些特定问题的答案是什么,但不知道解题的公式。这就造成模型无法泛化。如同一个人在他熟悉的领域畅通无阻,而一旦迈出这个领域就不知所措了。

过拟合问题比较棘手的是,猛一看好像模型的性能很好,因为它在训练数据上出现的错误很小。然而,一旦让模型去预测新的数据,它就掉链子了。
怎样发现过拟合
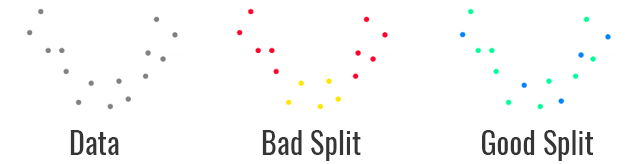
如上所说,过拟合的一个典型特征就是模型不能泛化。如果想测试模型是否具有泛化能力,一个简单的方法就是将数据集分成两部分:训练集和测试集。
- 训练集包含80%的可用数据,用于训练模型。
- 测试集包含剩余的20%可用数据,用于测试模型在它从未见过的数据上的准确率。
实际上分成三部分效果会更好:60%的训练数据集,20%的测试数据集和20%的验证数据集。
通过分割数据集,我们可以用每个数据集去检验模型的性能,以深入了解模型的训练过程,找出什么时候发生了过拟合。下图展示了不同的情况。

注意,如果想让这种方法凑效,你需要确保每个数据集都能代表你的数据。一个比较好的实践方法是分割数据集之前先打乱(shuffle)数据集的顺序。
过拟合虽然很难缠,但是也有一些方法能让我们预防,下面分别从3个角度分享6种防止过拟合的方法。
如何防止过拟合(从模型&数据角度)
首先,我们可以试着查看整个系统的各个组件寻找解决方法,也就是说改变我们所用的数据。
1 获取更多数据
你的模型可以存储很多很多的信息,这意味着你输入模型的训练数据越多,模型就越不可能发生过拟合。原因是随着你添加更多数据,模型会无法过拟合所有的数据样本,被迫产生泛化以取得进步。 收集更多的数据样本应该是所有数据科学任务的第一步,数据越多会让模型的准确率更高,这样也就能降低发生过拟合的概率。
2 数据增强&噪声数据
收集更多的数据会比较耗时耗力。如果没有时间和精力做这个,应该尝试让你的数据看起来更多元化一些。利用数据增强的方法可以做到这一点,这样模型每次处理样本的时候,都会以不同于前一次的角度看待样本。这就提高了模型从每个样本中学习参数的难度。
关于数据增强的方法,参见集智的这篇回答
另一个好方法是增加噪声数据:
- 对于输入:和数据增强的目的相同,但是也会让模型对可能遇到的自然扰动产生鲁棒性。
- 对于输出:同样会让训练更加多元化。
注意:在这两种情况中,你需要确保噪声数据的量级不能过大。否则最后你获取的输入信息都是来自噪声数据,或者导致模型的输出不正确。这两种情况也都会对模型的训练过程带来一定干扰。
3 简化模型
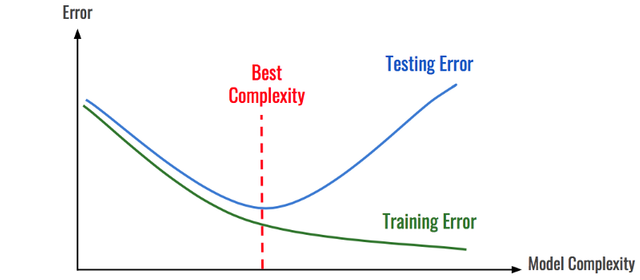
即时你现在手中获取了所有需要的数据,如果你的模型仍然过拟合训练数据集,可能是因为模型过于强大。那么你可以试着降低模型的复杂程度。
如前所述,模型只能过拟合部分数据。通过不断降低模型的复杂度(比如随机森林中的估计量,神经网络中的参数),最终达到一个平衡状态:模型足够简单到不产生过拟合,又足够复杂到能从数据中学习。这样操作时一个比较方便的方法是根据模型的复杂程度查看模型在所有数据集上的误差。
简化模型的另一个好处是能让模型更轻便,训练速度更快,运行速度也会更快。
如何防止过拟合(从训练过程角度)
模型出现过拟合的第二个地方可能是在训练阶段,应对方法包括调整损失函数或训练过程中模型运行的方式。
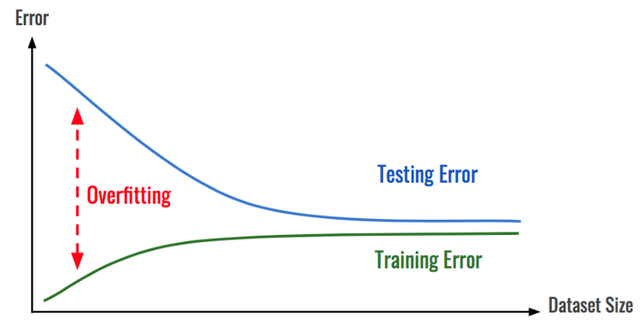
提前终止
大部分情况下,模型会首先学习数据的正确分布,然后在某个时间点上开始对数据过拟合。通过识别模型是从哪些地方开始发生转变的,那么就可以在过拟合出现之前停止模型的学习过程。和前面一样,通过查看随着时间推移的训练错误,就可以做到这一点。
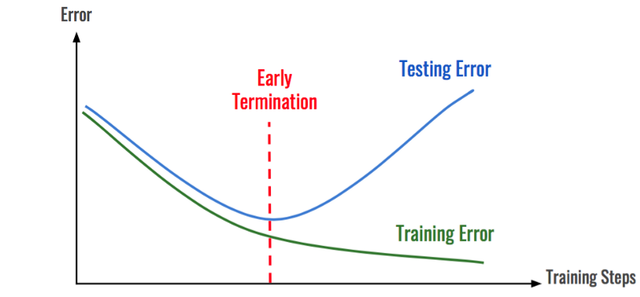
如何防止过拟合(从正则化角度)
正则化是指约束模型的学习以减少过拟合的过程。它可以有多种形式,下面我们看看部分形式。
L1和L2正则化
正则化的一个最强大最知名的特性就是能向损失函数增加“惩罚项”(penalty)。所谓『惩罚』是指对损失函数中的某些参数做一些限制。最常见的惩罚项是L1和L2:
- L1惩罚项的目的是将权重的绝对值最小化
- L2惩罚项的目的是将权重的平方值最小化
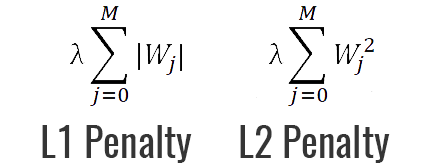
对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。下图是Python中Lasso回归的损失函数,等式中加号后面一项α||w||1即为L1正则化项。
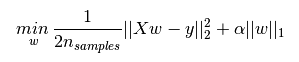
下图是Python中Ridge回归的损失函数,等式中加号后面一项α||w||22即为L2正则化项。
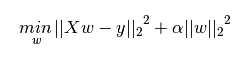
一般回归分析中回归w表示特征的系数,从上面等式可以看到正则化项是对系数做了处理(限制)。
结合等式,我们可以做出如下说明:
- L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1 。L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
- L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2。
有了惩罚项以后,模型就被迫对其权重做出妥协,因为它不能再任意让权重变大。这样就能让模型更泛化,从而帮助我们对抗过拟合。
L1惩罚项另一个优点是它能进行特征选择,也就是说它可以让一部分无用特征的系数缩小到0,从而帮助模型找出数据集中最相关的特征。缺点就是通常它在计算上不如L2惩罚项高效。
下面是权重矩阵的情形。注意L1矩阵是稀疏的权值矩阵,有很多0值,而L2矩阵则有相对较小的权值。
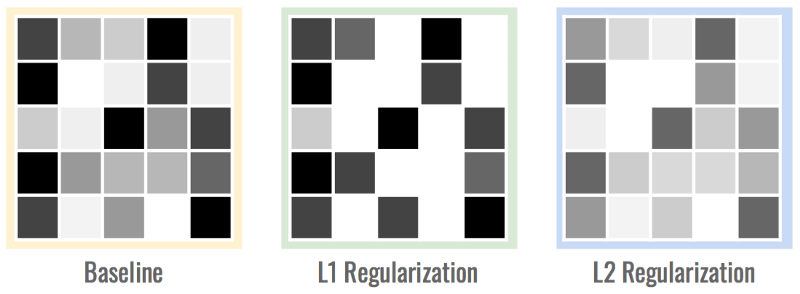
除了利用L1正则化和L2正则化防止模型过拟合之外,在训练阶段向参数中添加噪声数据也能促进模型的泛化。
如何防止过拟合(应对深度学习模型)
对于深度学习模型中的过拟合问题,我们可以从两个角度出发:Dropout和Dropconnect。 由于深度学习依赖神经网络处理从一个层到下一个层的信息,因而从这两方面着手比较有效。其理念就是在训练中随机让神经元无效(即dropout)或让网络中的连接无效(即dropconnect)。
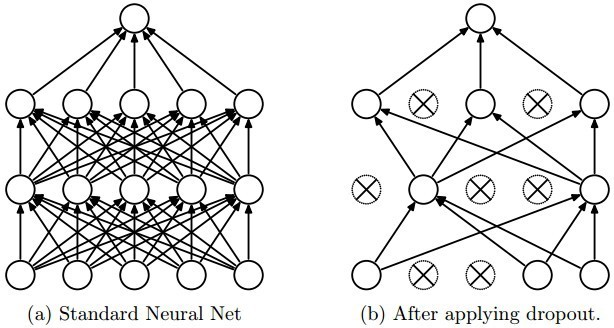
这样就让神经网络变得冗长和重复,因为它无法再依赖具体的神经元或连接来提取具体的特征。等完成模型训练后,所有的神经元和连接会被保存下来。试验显示这种方法能起到和神经网络集成方法一样的效果,可以帮助模型泛化,这样就能减少过拟合的问题。
结语
过拟合是我们在训练机器学习模型过程中遇到的一个大问题,如果不知道怎么应对,确实会让人很头疼。借助前面提到的这些方法,相信应该能帮你在训练机器学习模型过程中有效的防止模型过拟合。
参考资料:戳这里
0806期《人工智能-从零开始到精通》限时折扣中!
谈笑风生 在线编程 了解一下?
(前25位同学还可领取¥200优惠券哦)
