

《数学之美》上看到的,数据筛选有用,记一笔。
- 缺点:有误判,删除困难。
- 优点:占用空间小,查询快。
原理
a.添加元素:设计一个布隆过滤器
栗子:找一个Bit Array(行阵列),含有11位数字。
取一个待检测的值25
- 转二进制:11001
- 取奇数位和偶数位各自化成整数。上例中,奇数位:101,得5,偶数位:10,得2。(制造hash function)
- 对Bit Array总位数取模,也就是哈希运算。 5mod11=5,将索引5位的数置1 2mod11=2,将索引2的数置1

结果:
b.查询元素:用布隆过滤器判断一个数是否存在
假设我们有一个已知的过滤器:10100101010
我们想知道数118有没有在这个过滤器里出现过:
首先,计算118的二进制表达:y=118=1110110
h1(y)=14mod11=3
h2(y)=5mod11=5

在标中,索引3为0,索引5为1,因此我们认为118没有出现过。
c.hash function
a/b两个例子中的hash function是我们计算出来的。当我们设定hash function的时候,同样按照相同的方法计算哈希值(取模)
添加元素时,用k个hash function将它hash得到bloom filter中k个bit位,将这个k个bit位置1。
判断元素是否在集合中时,用k个hash function将它hash得到k个bit位。若这k bits全为1,则此元素在集合中;若其中任一为不为1,则此元素比不在集合中。
误判率FP的计算
布隆过滤器只有FP,没有FN,即不会漏报,但会有误报。
计算
Target:集合的大小
Target = Size(BitArray)
Dart:飞镖,也就是待计算的元素,为输入数据的量hash函数的个数
Dart = Size(NumOfInputElements*NumHashfunc)
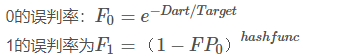
计算栗子:
假如我们有10亿的阵列,5个hash函数,然后我们输入1000万的数据
因此
Target=10^9
Dart=10^8 *5
F0=e^(-1/2)=0.607
F1=(1-F0)^5=(0.393)^5=0.00937
--------------------------------我是高调的分割线------------------------
???
redis实现布隆过滤器,利用bitmap和redis cluster构建分布式布隆过滤器???
???
???
