这一章主要说下python对内置对象管理采取的一些技巧。
整数对象池
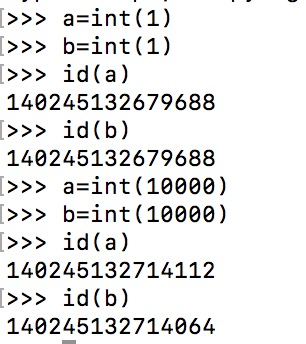
像平时编程过程中,我们经常会使用整形数据,如果按照引用技术的方式,每次对象使用完,调整计数值并进行回收。对于常用的数据,这种做法很损害执行效率。所以在python中引入整形对象池管理机制进行整形对象的管理。
python中整型的定义如下所示:



大整数和小整数
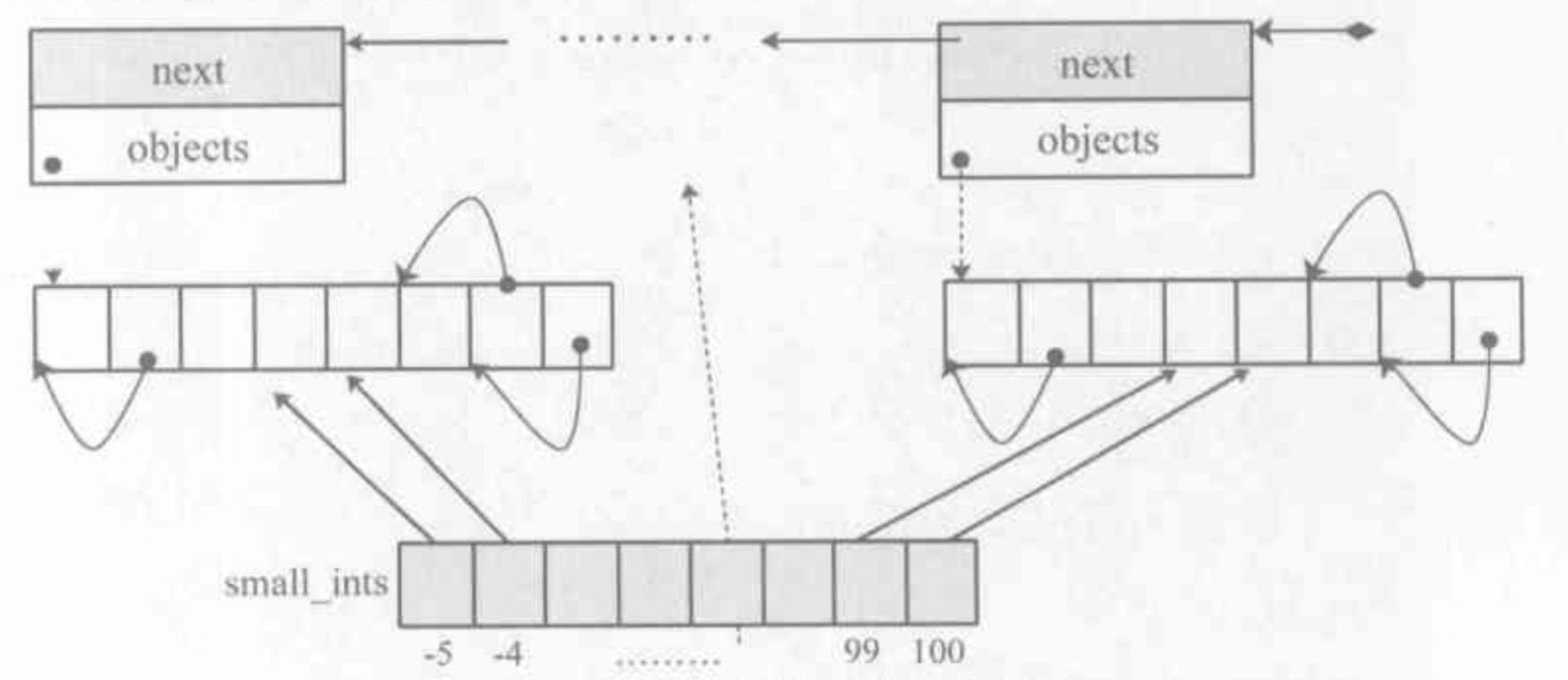
整数的大小其实都是靠主观判断的。python 默认小整数的范围在[-5, 257],这部分的整数是会存放到内存池缓存,其他整数在python中会存放在一个公共区域。
以下的数据结构是维护python整型内存结构。用单向链表进行维护
#define BLOCK_SIZE 1000
#define BHEAD_SIZE 8
#define N_INTOBJECTS ((BLOCK_SIZE-BHEAD_SIZE)/sizeof(PyIntObject))
struct _intblock {
struct _intblock* next;
PyIntObject objects[N_INTOBJECTS];
}
typedef struct _intblock PyIntBlock;
static PyIntBlock *block_list = NULL;
static PyIntBlock *block_free = NULL;
python整形的创建过程分为两步:
- 如果小整数对象池机制被激活了,则尝试使用小整形对象池 small_ints
- 否则使用通用整形对象池(这个时候需要从某块block中的objects中找到一块空闲的PyINtObject大小的空间)
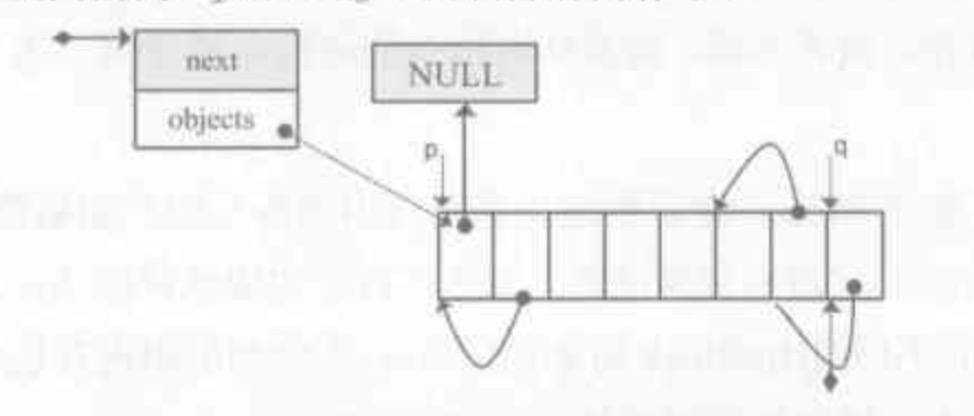
static PyIntObject* fill_free_list(void){
PyIntObject *p, *q;
p = (PyObject*) PyMem_MALLOC(sizeof(PyIntBlock));
((PyIntBlock*)p) ->next = block_list;
block_list = (PyIntBlock *)p;
p = &((PyIntBlock*)p)->objects[0];
q = p+N_INOBJECTS;
while(--q > p){
q->ob_type = (struct _typeobject *)(q-1);
}
q->ob_type = NULL;
return p+N_INOBJECTS -1;
}
(free_list = fill_free_list()) == NULL,这里将objects组织成链表并赋予free_list变量
v = free_list;
free_list = (PyIntObject *)v->ob_type;
这个过程是将free_list 指向下一个空闲空间,v则是分配出去的空间
这里使用ob_type去连接每一个int

字符串优化
python中具有可变长度对象和不可变长度对象。对于不可变长度对象,我们没办法对其进行添加删除操作。
由于字符串本身具备不可变的特征,使得字符串可以作为字典的key值。string的定义如下所示:
typedef struct {
PyObject_VAR_HEAD
long ob_shash;
int ob_sstate;
char ob_sval[1]; /*字符指针*/
} PyStringObject
ob_sstate表明该string有无被intern机制处理,ob_shash是缓存hash值,避免重复计算。
初始化关键代码
op = (PyStringObject*)PyObject_MALLOC(sizeof(PyStringObject) + size)
PyObject_INIT_VAR(op, &PyString_Type, size);
op->ob_shash = -1;
op->ob_sstate = SSTATE_NOT_INTERN
if(str!=null){
memcpy(op->ob_sval, str, size)
}
op->ob_sval[size] = '\0';
...
return (PyObject*)op;
intern机制:
目的让系统中只存在唯一的字符串对于的PyStringObject。

python针对单字符的做了类似小整形的处理,存在一个 static PyStringObject *characters[UCHAR_MAX+1]
list对象
typedef struct {
PyObject_VAR_HEAD
PyObject ** ob_item;
int allocated;
}
allocated维护元素列表可容纳的总数。
创建
PyObject* PyList_New(int size){
....
if(num_free_list) {
num_free_list --;
op = free_lists[num_free_list];
_Py_NewReference((PyObject*)op);
}else{
op = PyObject_Gc_New(PyListObject, &PyList_Type);
}
if (size<=0){
op->ob_item = NULL;
}else{
op->ob_item = (PyObject **)PyMem_MALLOC(nbytes);
memset(op-ob_item, 0, nbytes);
}
op->ob_size = size;
op->allocated = size;
return (PyObject*) op;
}
num_free_list的来源
static void list_dealloc(PyListObject* op){
int i;
if(op->ob_item != NULL){
i = op->ob_size;
while(--i>0){
Py_XDECREF(op->ob_item[i])
}
PyMem_FREE(op->ob_item);
}
if(num_free_lists < MAXREFLISTS && PyList_CheckExtract(op)){
free_lists[num_free_lists++] = op;
}else{
op->ob_type->tp_free((PyObject*)op);
}
}
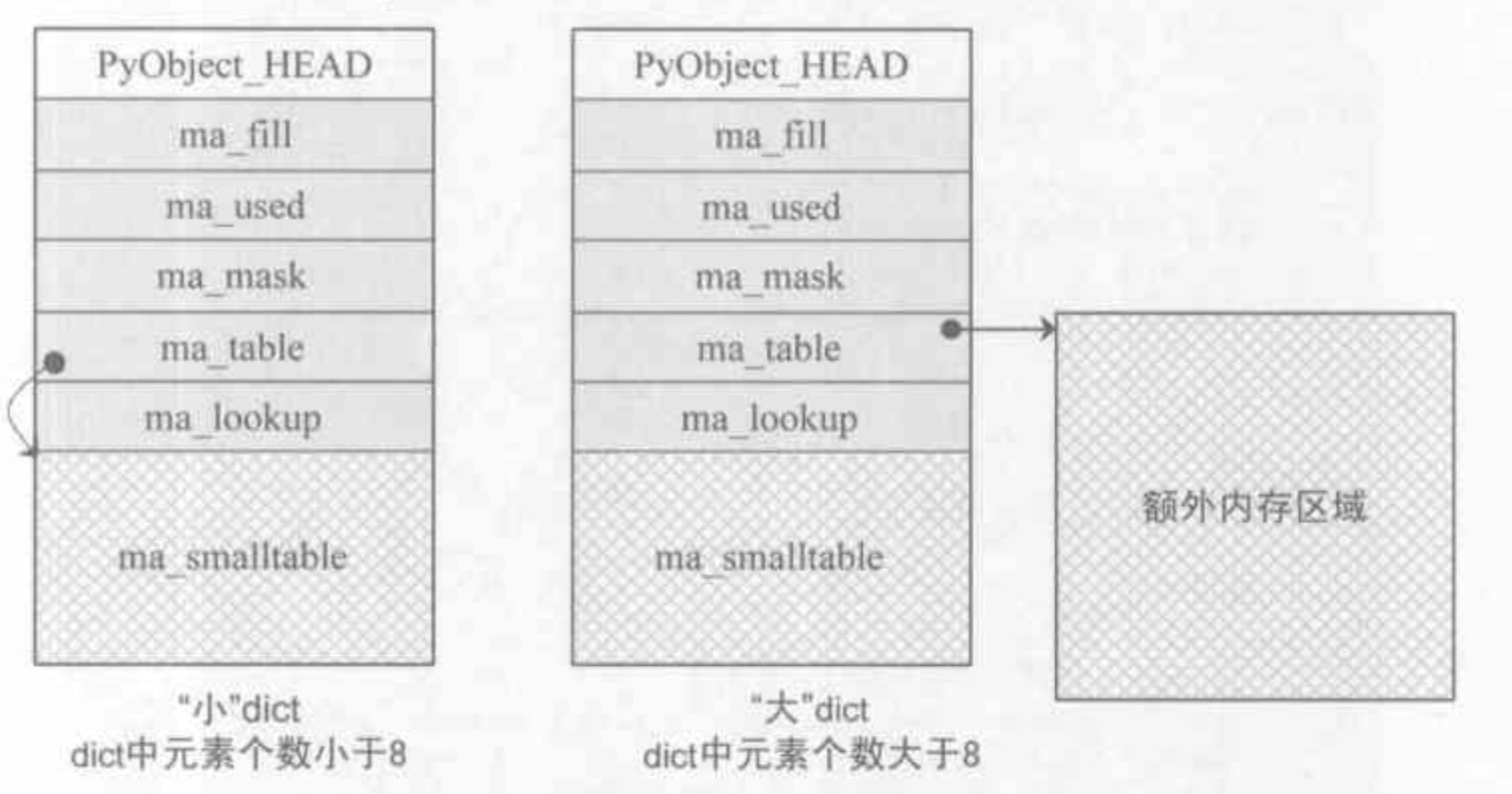
dict
在c++的STL的map是采取RB-tree去实现一个哈希结构,这样子它的查询开销为O(log2N).而python实现dict是采取散列表。
使用散列表会存在冲突的可能性,像大学学的数据结构中有谈及两种常规的解决冲突的方式。链表法和开放定址法。python使用后者进行冲突解决。当然二次探测存在一个问题,当删除的时候会存在断链的问题,这个时候需要有一个机制继续保持探测链的完整。所以python对删除的key采取设置其状态,使着不可用。
typedef struct {
Py_ssize_t me_hash;
PyObject* me_key;
PyObject* me_value;
} PyDictEntry
Entry表达三种状态是这样表达的:
当key和value都为null,代表Unused状态
当key为dummy,value为null 代表Dummy状态
当key有值且value不为null 代表Active状态
#define PyDict_MINSIZE 8
typedef struct _dictobject PyDictObject;
struct _dictobject{
PyObject_HEAD
Py_ssize_t ma_fill;
Py_ssize_t ma_used;
Py_ssize_t ma_mask;
PyDictEntry *ma_tables;
PyDictEntry *(*ma_lookup)(PyObject *mp, PyObject *key, long hash);
PyDictEntry ma_smalltable[PyDict_MINSIZE];
}
当key的数量小于PyDict_MINSIZE,使用ma_smalltable存储,超过之后使用ma_tables对于的空间