

batchPDF
a node programing that fetch key infomation from more than two thousand pdf documents,and output in excel
需求描述:处理同一目录下的2000个pdf文件,提取每个文件中的一些关键信息(单位名称,统一社会信用代码,行业类别),并整理数据导出为excel表格。
最近在看node文件处理,恰好发现校友群里有个土木专业的同学提出这么一个问题,当时的第一想法就是我也许可以做,然后就找到了那个同学问清楚了明确需求,并且要了部分pdf文件,开始做...... 我的第一想法就是,首先读取目录下的文件,然后对每个文件内容,进行正则匹配,找出目的信息,然后再导出。事实上也是这么回事,基本上分为三步:
- 读取文件
- 解析文件,匹配关键字。
- 导出excel
读取文件
node读取pdf文件,引入了'pdf2json':
npm install pdf2json --save
使用这个包,可以将pdf解析为json格式,从而得到文件的内容
const PDFParser = require('pdf2json');
const src = './pdf';
var pdfParser = new PDFParser(this, 1);
pdfParser.loadPDF(`${src}/${path}`);
pdfParser.on('pdfParser_dataError', errData =>reject( new Error(errData.parserError)));
pdfParser.on('pdfParser_dataReady', () => {
let data = pdfParser.getRawTextContent();
});
使用正则表达式匹配出关键字
目标是找出每个文件中的“单位名称”、”统一社会信用代码“、“行业类别”,仔细分析上一过程中输出的结果:
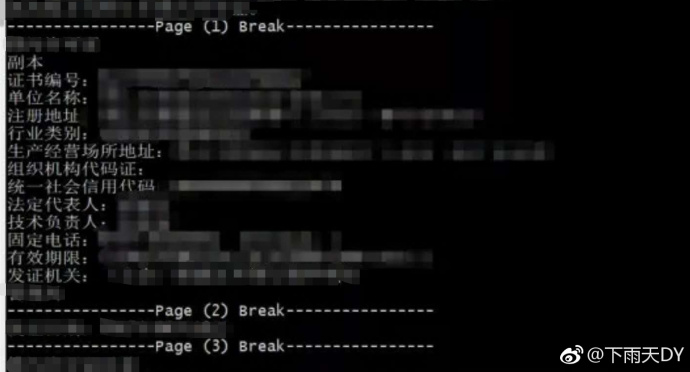
因为要处理的文件内容格式都非常严谨,我们所要获取的信息都在第三页,解析出的json数据中,目标文本分布在page(1)和page(3)中,且目标文本格式都是key:value的格式,每一个文本都换行,所以处理起来就方便多了,最终匹配的是以“单位名称:”开头的一个或者多个非空字符,由于要匹配三个值,所以用(red|blue|green)这种方式来查找目标值。
let result = data.match(/(统一社会信用代码|单位名称|行业类别):[\S]*/g);
match匹配最终得到一个数组:
result = ['统一社会信用代码:xxx','单位名称:xxx','行业类别:xxx']
导出为excel表格
网上有很多js代码将table导出为excel的代码,这里使用了'node-xlsx',安装:
npm install node-xlsx --save
使用这个是因为简单,并且也符合需求,上手快。
const xlsx = require('node-xlsx');
var buffer = xlsx.build([{name: 'company', data: list}]);
fs.writeFileSync('list.csv', buffer, 'binary');
三行代码就搞定了,就得到了一个csv格式的excel,剩下的处理就是对list的处理了,传入的list需为一个二维数组,数组的第一项为表头,其他项为每一行对应得数据,也为数组格式。整理的list如下:
[
['序号','统一社会信用代码','单位名称','行业类别'],
['xxx','xxx','xxx','xxxx']
]
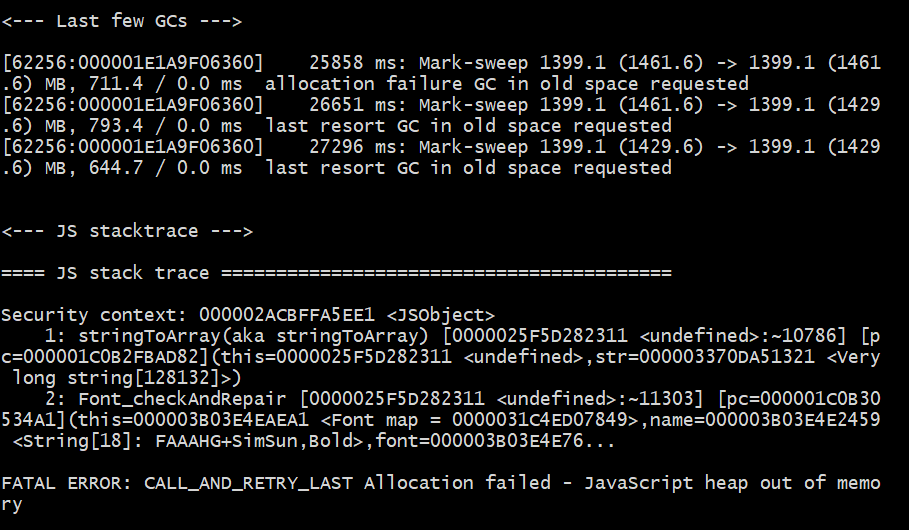
解析PDF的过程为异步,所以在批量处理大量文件的情况下,要考虑内存泄漏问题,每次只处理五个,处理完成之后再去处理剩余的文件,直到全部完成处理,输出为excel。 当文件数量超过30个,报错信息如下:
FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory
出现问题的原因:
- 网上有一种回答是:解析的是一个大的文件,转换为json后,相当于操作一个巨大的对象,所以会报错,但是文件数量小的时候,解析是正常的,所以这种假设可以排除。
- 内存溢出,程序执行所需要的内存超出了系统分配给内存大小
解释:由于node是基于V8引擎,在node中通过javascript使用内存时只能使用部分内存,64位系统下约为1.4GB,32位系统下约为0.7GB,当执行的程序占用系统资源过高,超出了V8对node默认的内存限制大小就会报上图所示错误。
如果是编译项目,V8提供的默认内存大小不够用,可以去修改 --max-old-space-size,但是我目前的需求是处理2000多个pdf文件,解析为json,所以使用的内存大小是不确定的,不能采取这种方案。
我的理解:node js 很多操作都是异步执行的,而异步操作的结果就是不能确保执行完成的时间,所以当多个异步操作同时进行的时候,不能确保执行完成的顺序,但是执行的结果又是相互关联的,所以在执行的时候,会一直占用内存,而不被垃圾回收机制回收,造成内存泄漏。(也有一种可能是队列里等待执行的任务太多了。。。)
错误的代码
const PDFParser = require('pdf2json');
const fs = require('fs');
const src = './pdf';
const xlsx = require('node-xlsx');
let list = [['序号','统一社会信用代码','单位名称','行业类别']];
let index = 1;
let len = 0;
fs.readdir(src, (err, files) => {
len = files.length;
files.forEach(item => {
var pdfParser = new PDFParser(this, 1);
pdfParser.loadPDF(`${src}/${item}`);
pdfParser.on('pdfParser_dataError', errData => console.error(errData.parserError)); pdfParser.on('pdfParser_dataReady', () => {
let data = pdfParser.getRawTextContent();
let result = data.match(/(统一社会信用代码|单位名称|行业类别):[\S]*/g);
for (let i = 0 ;i < 3;++i){
result[i] = result[i].split(':')[1];
}
list.push(result);
++index;
if( index === len){
var buffer = xlsx.build([{name: 'company', data: list}]); // Returns a buffer
fs.writeFileSync('list.csv', buffer, 'binary');
}
});
});
});
但是究竟这个异步操作的并发量的上限是多少,不能确定,有一个同学尝试过,读取PDF文件的时候,上限是30,分析以上结果,进行改进,改进之后,每次执行五个异步操作,执行完成之后再继续执行下一个五个异步函数。
测试过,这种方式处理100个文件时没有问题的,对比了两种方式方法,以34个文件为测试用例:
方法 | 文件数量 | 读取时间(s) | CPU | 内存
- | :-: |:-: -: | :-: | :-: 方法一 | 34| 26.817 | 暴涨(14%-42%) | 最大(1591MB) 方法二 | 34| 19.374 | (36%)平稳 | 最大(300MB)
改进后核心代码
ConvertToJSON(path){
return new Promise((resolve,reject) => {
var pdfParser = new PDFParser(this, 1);
pdfParser.loadPDF(`${src}/${path}`);
pdfParser.on('pdfParser_dataError', errData =>reject( new Error(errData.parserError)));
pdfParser.on('pdfParser_dataReady', () => {
// 省略处理部分
resolve(result);
});
}).catch(error => {
console.log(error);
});
}
seek(callback){
let arr = this.files.splice(0,5);
let all = [];
arr.forEach(item => {
all.push(this.ConvertToJSON(item));
});
let promise = Promise.all(all);
promise.then(result => {
// 省略处理部分
return this.files.length === 0 ? callback(this.list) : this.seek(callback);
});
}
源码地址,欢迎指正。 能够帮助到别人同时自己又尝试了新鲜事物,所以觉得很开心。
参考文档:
- Node.js v8.9.3 文档
- nodejs将PDF文件转换成txt文本,并利用python处理转换后的文本文件
- node-xlsx
- nodeJs内存泄漏问题详解
- Node.js 中的 UnhandledPromiseRejectionWarning 问题
- 4种JavaScript的内存泄露及避免方法
- JavaScript 工作原理之二-如何在 V8 引擎中书写最优代码的 5 条小技巧(译)
在此鸣谢大学好友邢旭磊。
我的个人博客:下雨天DY的前端成长记
