

| 不积跬步,无以至千里;不积小流,无以成江海。——荀子 |
 管理 posts - 66,comments - 3,trackbacks - 0
管理 posts - 66,comments - 3,trackbacks - 0
|
||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | 1 | 2 | 3 | 4 |
欢迎交流,邮箱:junlinhe@yeah.net
 昵称:hejunlin
昵称:hejunlin园龄: 2年10个月
粉丝:3
关注: 7 +加关注
搜索
常用链接
我的标签
- deep learning(34)
- CNN(18)
- leetcode(13)
- tensorflow(13)
- 动态规划(8)
- paper reading(7)
- 线性代数(3)
- machine learning(3)
- math(1)
- object detection(1)
- 更多
随笔档案
- 2018年5月 (4)
- 2018年4月 (11)
- 2018年3月 (1)
- 2018年2月 (5)
- 2018年1月 (8)
- 2017年12月 (4)
- 2017年11月 (7)
- 2017年10月 (11)
- 2017年9月 (15)
文章分类
最新评论
- 1. Re:卷积神经网络中的参数计算
- @小白羀号可以这么理解。卷积核的深度与输入的通道数是一样的...
- --hejunlin
- 2. Re:卷积神经网络中的参数计算
- 卷积核也有深度吗
- --小白羀号
- 3. Re:[Kaggle] dogs-vs-cats之模型训练
- 您好,想请教一下~我按照上面的方法在Pycharm编译器上进行编译,但是训练的次数达不到预设的值,想请问一下我应该怎么解决这个问题呀?
- --Eyesxjg
阅读排行榜
- 1. 卷积神经网络中的参数计算(7091)
- 2. 似然函数、最大似然估计简单理解(3178)
- 3. 机器学习中常见的几种损失函数(2579)
- 4. [翻译] Tensorflow模型的保存与恢复(2360)
- 5. TensorFlow-Slim使用方法说明(1603)
评论排行榜
推荐排行榜
似然函数、最大似然估计简单理解
摘抄自维基百科:
https://zh.wikipedia.org/wiki/%E4%BC%BC%E7%84%B6%E5%87%BD%E6%95%B0
https://zh.wikipedia.org/wiki/%E6%9C%80%E5%A4%A7%E4%BC%BC%E7%84%B6%E4%BC%B0%E8%AE%A1
似然函数(Likelihood function、Likelihood)
在数理统计学中,似然函数是一种关于统计模型中的 参数的函数,表示模型参数中的似然性。似然函数在统计推断中有重大作用,如在 最大似然估计和费雪信息之中的应用等等。“似然性”与“或然性”或“ 概率”意思相近,都是指某种事件发生的可能性,但是在 统计学中,“似然性”和“或然性”或“概率”又有明确的区分。概率用于在已知一些参数的情况下,预测接下来的观测所得到的结果,而似然性则是用于在已知某些观测所得到的结果时,对有关事物的性质的参数进行估计。
在这种意义上,似然函数可以理解为条件概率的逆反。在已知某个参数B时,事件A会发生的概率写作:
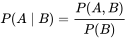
利用贝叶斯定理,
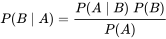
因此,我们可以反过来构造表示似然性的方法:已知有事件A发生,运用似然函数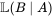 ,我们估计参数B的可能性。形式上,似然函数也是一种条件概率函数,但我们关注的变量改变了:
,我们估计参数B的可能性。形式上,似然函数也是一种条件概率函数,但我们关注的变量改变了:
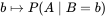
注意到这里并不要求似然函数满足归一性: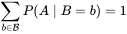 。一个似然函数乘以一个正的常数之后仍然是似然函数。对所有
。一个似然函数乘以一个正的常数之后仍然是似然函数。对所有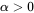 ,都可以有似然函数:
,都可以有似然函数:
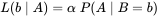
最大似然估计(maximum likelihood estimation ,MLE)
给定一个概率分布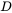 ,已知其概率密度函数(连续分布)或概率质量函数(离散分布)为
,已知其概率密度函数(连续分布)或概率质量函数(离散分布)为
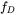 ,以及一个分布参数
,以及一个分布参数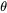 ,我们可以从这个分布中抽出一个具有
,我们可以从这个分布中抽出一个具有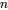 个值的采样
个值的采样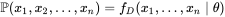
但是,我们可能不知道的值,尽管我们知道这些采样数据来自于分布 。那么我们如何才能估计出 呢?一个自然的想法是从这个分布中抽出一个具有 个值的采样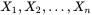 ,然后用这些采样数据来估计.
,然后用这些采样数据来估计.
一旦我们获得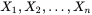 ,我们就能求得一个关于的估计。最大似然估计会寻找关于的最可能的值(即,在所有可能的取值中,寻找一个值使这个采样的“可能性”最大化)。这种方法正好同一些其他的估计方法不同,如的
非偏估计,非偏估计未必会输出一个最可能的值,而是会输出一个既不高估也不低估的值。
,我们就能求得一个关于的估计。最大似然估计会寻找关于的最可能的值(即,在所有可能的取值中,寻找一个值使这个采样的“可能性”最大化)。这种方法正好同一些其他的估计方法不同,如的
非偏估计,非偏估计未必会输出一个最可能的值,而是会输出一个既不高估也不低估的值。
要在数学上实现最大似然估计法,我们首先要定义似然函数:
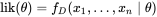
并且在的所有取值上通过令一阶导数等于零,使这个函数取到最大值。这个使可能性最大的
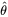 值即称为的最大似然估计。
值即称为的最大似然估计。
注意
- 这里的似然函数是指
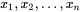 不变时,关于的一个函数。
不变时,关于的一个函数。 - 最大似然估计函数不一定是惟一的,甚至不一定存在。
----------------------------------------
另外,可以看这篇文章,有比较详细的例子介绍:
深入浅出最大似然估计(Maximum Likelihood Estimation)
posted on 2017-12-04 10:59 hejunlin 阅读(3180) 评论(0) 编辑 收藏 刷新评论刷新页面返回顶部 注册用户登录后才能发表评论,请 登录 或 注册, 访问网站首页。 【推荐】超50万VC++源码: 大型组态工控、电力仿真CAD与GIS源码库!
【推荐】腾讯云新注册用户域名抢购1元起
【大赛】2018首届“顶天立地”AI开发者大赛
 最新IT新闻:
最新IT新闻:· 格力电器前董事长朱江洪:我对格力做芯片信心不大
· 成立三年宣告上市,拼多多的高速与缓行
· Linux Mint 19 “Tara”发布
· 微软内部邮件确认神秘“便携式”Surface
· 体验了星巴克在北京的第一家旗舰店,我想对喜茶一点点彻底说再见
» 更多新闻...
 最新知识库文章:
最新知识库文章:· 如何提升你的能力?给年轻程序员的几条建议
· 程序员的那些反模式
· 程序员的宇宙时间线
· 突破程序员思维
· 云、雾和霭计算如何一起工作
» 更多知识库文章... Copyright ©2018 hejunlin Powered By博客园 模板提供:沪江博客
