

【背景】
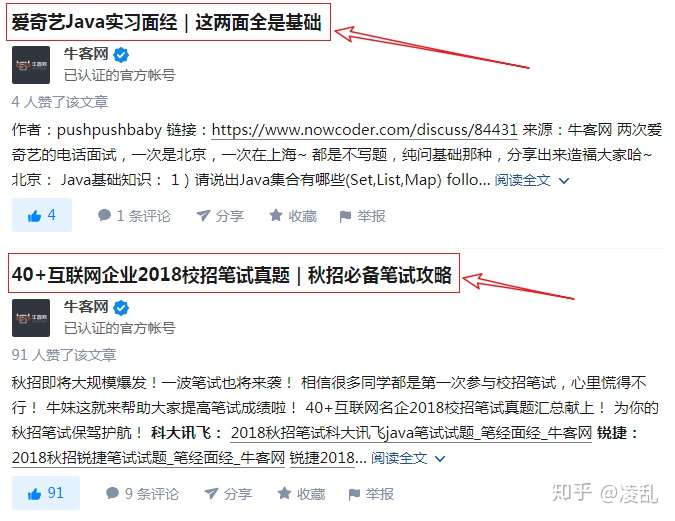
前段时间,阅读知乎上一些用户写的文章的时候觉得阅读起来比较麻烦,不符合我的阅读感受。比如下边这个,我想阅读牛客网的文章(如图1所示),我会通过标题先进行筛选,但是这样滚动下滑太麻烦了,所以想着不如将标题信息爬下来,另外,点赞数和评论数也顺便抓取下来,这样还能看该用户被点赞数最多的文章是哪一篇。说干就干!
【思路】
利用selenium抓取知乎用户的文章页面源码,接着用pyquery库来解析文章相关信息,并将其保存到MongoDB数据库中,通过MongoDB Compass这个可视化工具可以可视化的操作数据库,还可以进行数据的导入导出。
【涉及知识点】
- 基本库的使用
- selenium库、pyquery库、pymongo库的使用
- CSS selector的使用
- 正则表达式
【预装库及软件】
- 首先确保自己的电脑安装了MongoDB数据库。
- MongoDB Compass软件自己视情况而定,如果常用命令行操作数据库的话,这个可以不安装,对我们的数据抓取没有影响。
- 确保你的Python3环境中有下边几个库,pymongo、selenium和pyquery要自己安装,可以直接用pip进行安装。
import re
import time
import pymongo
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from pyquery import PyQuery as pq
【网页分析】
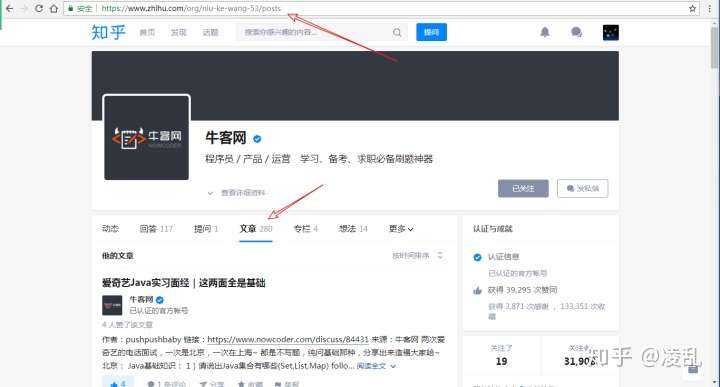
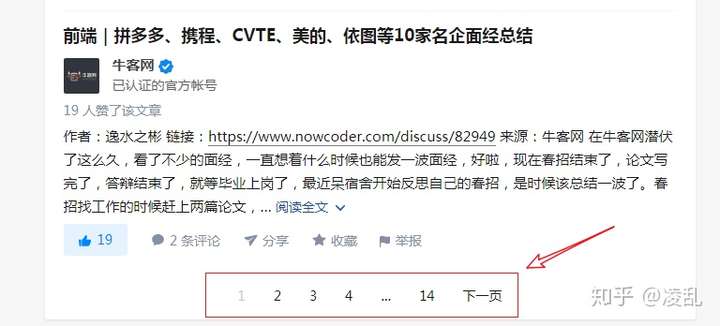
- 首先找到知乎用户牛客网的文章列表的链接(如图2所示),可以看到总共280篇文章。拉到页面底部可以看到文章列表共有14页(如图3所示)。
- 当我们点下一页,页面跳转到第二页时,可以看到网页链接变成“/org/niu-ke-wang-53/posts?page=2”,这样的话,我们可以通过改变传入参数“page”的值来请求这14个页面。
- 我们使用selenium来模拟浏览器打开网页,这里使用 WebDriverWait 来等待页面加载完网页之后再进行别的处理工作。还可以注意到这样一件事,页面加载完成的时候页面是没有全部显示的,随着鼠标向下滚动才加载出来页面的全部信息。通过如下代码可以模仿鼠标向下滚动到页面底部。
browser.execute_script("window.scrollTo(0, document.body.scrollHeight)")
- 加载出来页面之后就可以抓取信息了。信息提取这部分主要有函数“get_posts()”来负责。我选择抓取了文章标题、文章链接、文章作者、文章作者主页链接、点赞人数以及评论数。
- 最后由函数“save_to_mongo()”来将信息存储进MongoDB数据库中。
- 用下边的代码来取代“browser = webdriver.Chrome()”可以实现浏览器不打开,在后台进行抓取工作。
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
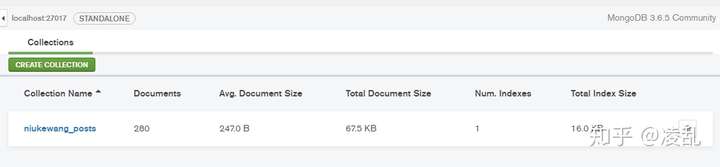
- 最后打开MongoDB Compass软件可以看到“Documents”值为280,总共抓取了280篇文章的信息。
【代码实现】
MONGO_URL = 'localhost'
MONGO_DB = 'zhihu'
MONGO_COLLECTION = 'niukewang_posts'
MAX_PAGE = 14
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
# browser = webdriver.Chrome()
wait = WebDriverWait(browser, 10)
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
def index_page(page):
"""
抓取索引页
:param page: 页码
"""
print('正在爬取第', page, '页')
try:
url = 'https://www.zhihu.com/org/niu-ke-wang-53/posts?page=' + str(page)
browser.get(url)
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, '.Pagination .PaginationButton--current'), str(page)))
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.Profile-mainColumn .List .List-item')))
browser.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(3)
get_posts()
except TimeoutException:
index_page(page)
def get_posts():
"""
提取文章数据
"""
html = browser.page_source
doc = pq(html)
items = doc('#Profile-posts .List-item').items()
for item in items:
urlstr = item.find('.ContentItem.ArticleItem').attr('data-zop')
pattern = re.compile('"itemId":(.*?),')
urlid = re.findall(pattern, urlstr)
commentstr = item.find('.ContentItem-actions .ContentItem-action.Button--plain').text()
pattern = re.compile('(\d+)')
commentnum = re.findall(pattern, commentstr)
if len(commentnum) == 0:
commentnum.append('0')
niukewang_posts = {
'title': item.find('.ContentItem-title').text(),
'url': 'https://zhuanlan.zhihu.com/p/'+urlid[0],
'authorname': item.find('.ContentItem-meta .AuthorInfo-content .UserLink-link').text(),
'authorurl': 'https:'+str(item.find('.ContentItem-meta .AuthorInfo-content .UserLink-link').attr('href')),
'like': int(item.find('.ContentItem-actions .LikeButton').text()),
'commentnum': int(commentnum[0])
}
print(niukewang_posts)
save_to_mongo(niukewang_posts)
def save_to_mongo(result):
"""
保存至MongoDB
:param result: 结果
"""
try:
if db[MONGO_COLLECTION].insert(result):
print('存储到MongoDB成功')
except Exception:
print('存储到MongoDB失败')
def main():
"""
遍历每一页
"""
for i in range(1, MAX_PAGE + 1):
index_page(i)
browser.close()
if __name__ == '__main__':
main()
【成果展示】
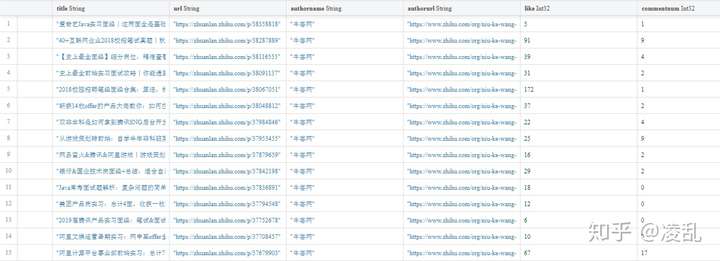
下载好的信息按照条目存放到了本地MongoDB数据库里(如图5所示)。
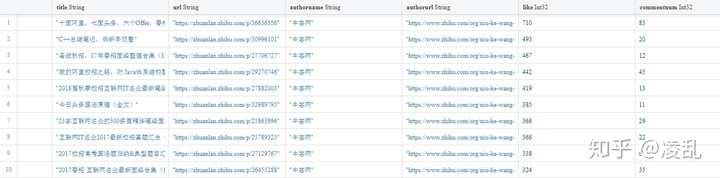
用点赞数作为关键词进行降序排列(如图6所示),其中,点赞数最多的是“十面阿里,七面头条,六个Offer,春招结束”这篇文章,有710个赞和83条评论。
【后记】
写文章的初衷也算是将自己的学习成果传播给大家,来帮助大家学习,所以对我写的这篇文章有什么问题的欢迎询问,同时,有错误的地方也欢迎批评指正~
后边写的多的话,会将代码一一整理出来放到GitHub上,分享给大家~
