

How to Write Distributed TensorFlow Code
分布式机器学习策略
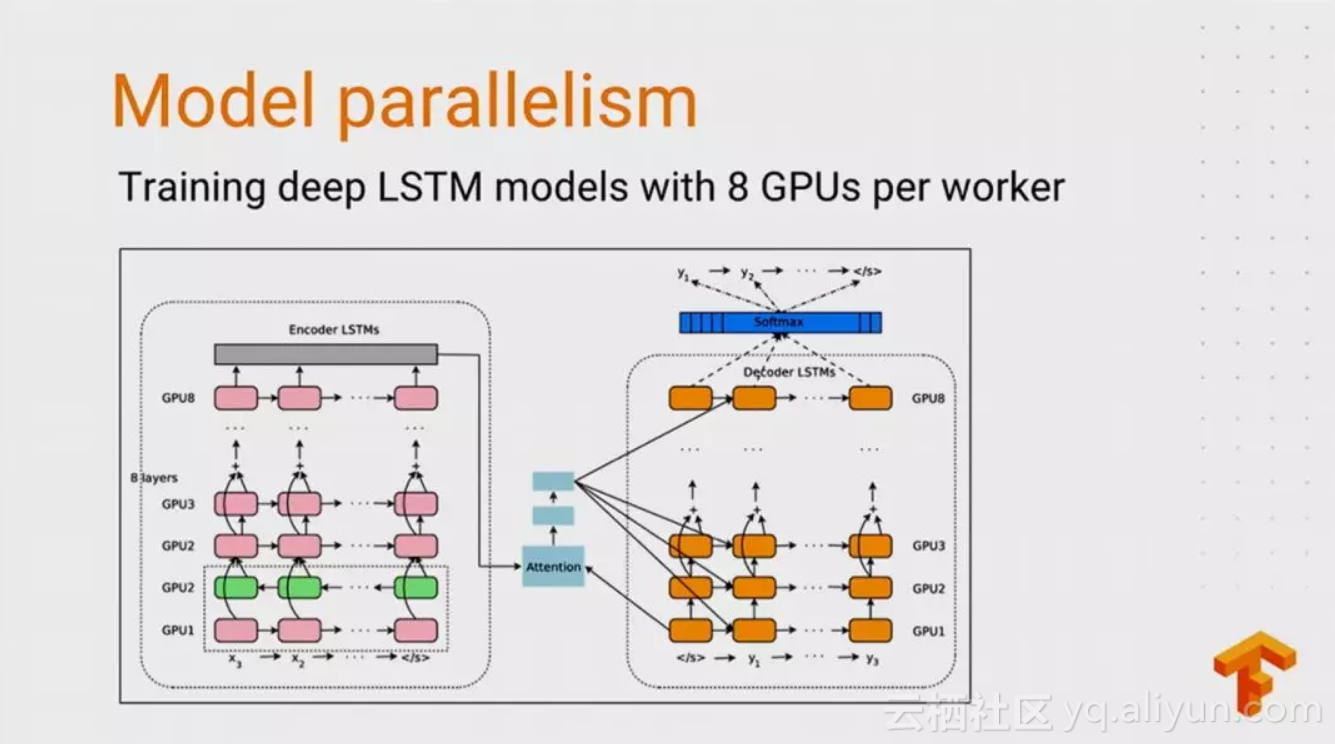
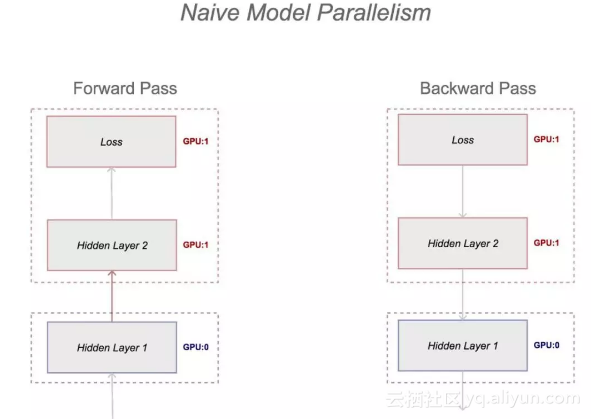
模型并行化
当模型过大以至于一台及其的内存承受不住时,可以将计算图的不同部分放到不同的机器中,模型参数的存储和更新都在这些机器中进行。
一个最基本的方法是:把网络第一层放在一台机器上,第二层放在另一台机器上。然而,这样并不好,在前向传播时,较深的层需要等待较浅的层,在发现传播时,较浅的层需要等待较深的层。当模型中有并行的操作时(如GooLeNet),这些操作可以在不同的机器上运行,避免这样的瓶颈。
数据并行化
整个计算图被保存在一个或多个参数服务器(ps)中。训练操作在多个机器上被执行,这些机器被称作worker。这些worker读取不同的数据(data batches),计算梯度,并将更新操作发送给参数服务器。
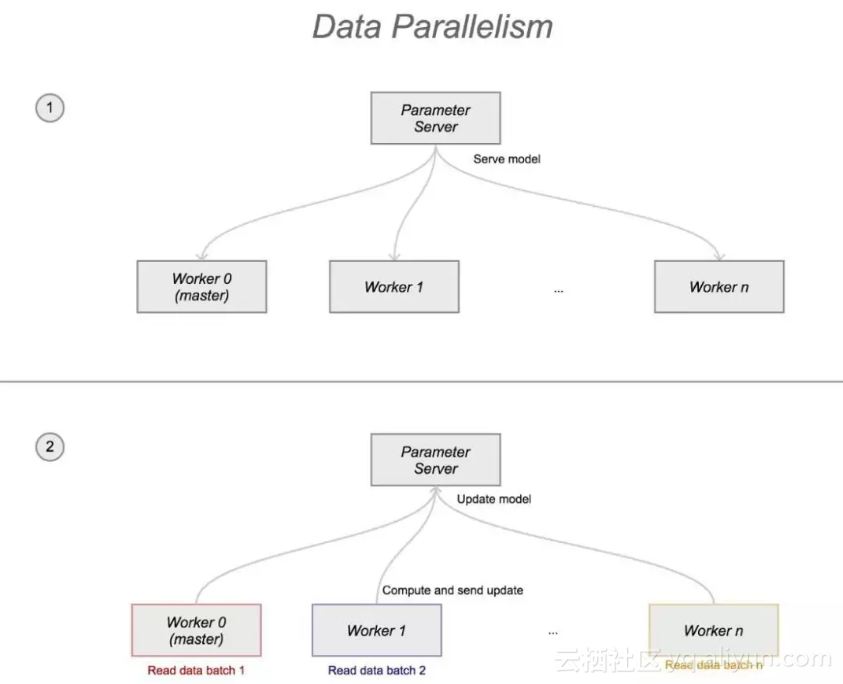
数据并行化有两种主要的方案:
 同步训练: 所有的worker服务器同时读取参数,执行训练操作,等待所有的worker服务器都完成当前训练操作后,梯度被平均后变成一个单独的更新请求并被发送到参数服务器中。所以在任何时候,每个worker服务器看到的计算图参数都是相同的。异步训练:
worker服务器会异步地从参数服务器中读取参数,执行训练操作,并将更新请求异步地发送。在任何时间,两台worker服务器可能会看到参数不同的计算图。
同步训练: 所有的worker服务器同时读取参数,执行训练操作,等待所有的worker服务器都完成当前训练操作后,梯度被平均后变成一个单独的更新请求并被发送到参数服务器中。所以在任何时候,每个worker服务器看到的计算图参数都是相同的。异步训练:
worker服务器会异步地从参数服务器中读取参数,执行训练操作,并将更新请求异步地发送。在任何时间,两台worker服务器可能会看到参数不同的计算图。本文会聚焦于如何在数据并行化模型中使用异步训练方案。
构建数据并行化模型
如前面所述,我们的系统会包含三种类型的节点:
一个或多个参数服务器,用来存放模型 一个主worker,用来协调训练操作,负责模型的初始化,为训练步骤计数,保存模型到checkpoints中,从checkpoints中读取模型,向TensorBoard中保存summaries(需要展示的信息)。主worker还要负责分布式计算的容错机制(如果参数服务器或worker服务器崩溃)。 worker服务器(包括主worker服务器),用来执行训练操作,并向参数服务器发送更新操作。也就是说最小的集群需要包含一个主worker服务器和一个参数服务器。可以将它扩展为一个主worker服务器,多个参数服务器和多个worker服务器。
最好有多个参数服务器,因为worker服务器和参数服务器之间有大量的I/O通信。如果只有2个worker服务器,可能1个参数服务器可以扛得住所有的读取和更新请求。但如果你有10个worker而且你的模型非常大,一个参数服务器可能就不够了。
在分布式TensorFlow中,同样的代码会被发送到所有的节点。虽然你的main.py、train.py等会被同时发送到worker服务器和参数服务器,每个节点会依据自己的环境变量来执行不同的代码块。
分布式TensorFlow代码的准备包括三个阶段:
-
定义tf.trainClusterSpec和tf.train.Server
-
将模型赋给参数服务器和worker服务器
-
配置和启动tf.train.MonitoredTrainingSession
1. 定义tf.trainClusterSpec和tf.train.Server
tf.train.ClusterSpec object将任务映射到机器,它被用在tf.train.Server的构造函数中来构造tf.train.Server,在每台机器上创建一个或多个server,并确保每台机器能知道其他的机器在做什么。它包含设备的集合(某台机器上可用的设备),以及一个tf.Session object(tf.Session object会被tf.train.MonitoredTrainingSession 用于执行计算图)。
通常情况下,一台机器上有一个任务,除非你的机器有多个GPU,在这种情况下,你会给每个GPU分配一个任务。
从TensorFlow教程中摘取:
一个tf.train.ClusterSpec表示参与分布式TensorFlow计算的进程的集合。每个tf.train.Server都在一个集群中被构建。
一个tf.train.Server实例包含了设备的集合,和一个可以参与分布式训练的tf.Session目标。一台服务器属于一个集群(由tf.train.ClusterSpec指定)
A server belongs to a cluster (specified by a ),并且对应一个任务。服务器可以和所在集群中的所有其他服务器进行通信。
2. 为worker服务器指定模型的变量和操作
用 with tf.device 命令,你可以将节点(无论是操作还是变量)指定到一个任务或工作中。例如:
tf.train.AdamOptimizer(learning_rate)
.minimize(loss, global_step = global_step)
)
不在with tf.device块内的节点,会被TensorFlow自动地分配给一个设备。
在数据并行化框架中,节点会被分配到参数服务器中,操作会被分配到worker服务器中。手动进行分配不具有扩展性(设想你有10台参数服务器,你不会想手动地为每一台分配变量)。TensorFlow提供了方便的tf.train.replica_device_setter,它可以自动地为设备分配操作。
它以一个tf.train.ClusterSpec对象作为输入,并返回一个用于传给tf.device的函数。
在我们的模型中,变量操作被存放在参数服务器中,训练操作被存放在worker服务器中。
上面定义计算图的操作变为:
(cluster_spec)): ... #model definition X = tf.placeholder(tf.float32, [100, 128,128, 3 ], name= "X" )
... #training ops definition train_step = (
tf.train.AdamOptimizer(learning_rate)
.minimize(loss, global_step = global_step)
)
3. 配置和启动tf.train.MonitoredTrainingSession
tf.train.MonitoredTrainingSession是tf.Session在分布式训练中的等价物。它负责设置一个主worker节点,它会:
初始化计算图读取和保存checkpoints导出TensorBoard展示所需信息(summaries)启动/停止会话参数:
tf.train.MonitoredTrainingSession的参数包含主节点、checkpoints路径、保存checkpoints以及导出TensorBoard展示所需信息的频率。
Server is_chief= ..., #boolean, is this node the master? checkpoint_dir= ..., #path to checkpoint
/tensorboard dir hooks = hooks #see next section ) as sess:
对于is_chief,你需要在代码中某处定义某个节点是主节点,例如你可以从集群部署系统中获取。
设置训练步数
我猜,你曾经在tf.Session块中使用了循环,并在循环中的每个迭代中,使用一个或多个sess.run指令。
这不是MonitoredTrainingSession执行的方式,所有的实例需要合理地被终止和同步,一个checkpoint需要被保存。因此,训练的步数通过一个SessionRunHook对象列表,被直接传入MonitoredTrainingSession。
向MonitoredTrainingSession对象传入一个tf.train.StopAtStepHook钩子,这个钩子定义了训练的最后一步,之后参数服务器和worker服务器会被关闭。
注意:有一些其他类型的钩子,你可以基于tf.train.SessionRunHook定义自己的钩子,这里不详细介绍了。
代码如下:
图如下:
在Clusterone中构建数据并行化模型
现在我们了解了分布式TensorFlow代码中的组件,我来提供一些在Clusterone中运行分布式TensorFlow的高层次的代码片段:
# You need to have the clusterone package installed
(pip install tensorport)
# Export logs and outputs to /logs, your data is in /data. import tensorflow as tf from clusterone import get_data_path, get_logs_path # Get the environment parameters for distributed
TensorFlow try: job_name = os.environ['JOB_NAME' ]
task_index = os.environ['TASK_INDEX' ]
ps_hosts = os.environ['PS_HOSTS' ]
worker_hosts = os.environ['WORKER_HOSTS' ] except: # we are not on TensorPort, assuming local,
single node task_index = 0 ps_hosts = None worker_hosts = None # This function defines the master, ClusterSpecs and
device setters def device_and_target (): # If FLAGS.job_name is not set, we're running
single-machine TensorFlow.
# Don't set a device. if FLAGS.job_name is None: print ("Running single-machine training" ) return (None, "" ) # Otherwise we're running distributed TensorFlow. print ("Running distributed training" ) if FLAGS.task_index is None or FLAGS.task_index == "" : raise ValueError ("Must specify an explicit
`task_index`" ) if FLAGS.ps_hosts is None or FLAGS.ps_hosts == "" : raise ValueError ("Must specify an explicit
`ps_hosts`" ) if FLAGS.worker_hosts is None or FLAGS.worker_hosts == "" : raise ValueError ("Must specify an explicit
`worker_hosts`" )
cluster_spec = tf.train.ClusterSpec({ "ps": FLAGS.ps_hosts.split("," ), "worker": FLAGS.worker_hosts.split("," ), })
server = tf.train.Server(
cluster_spec, job_name = FLAGS.job_name, task_index= FLAGS.task_index) if FLAGS.job_name == "ps" : server.join()
worker_device = "/job:worker/task:{}" .
format(FLAGS.task_index) # The device setter will automatically place Variables
ops on separate
# parameter servers (ps). The non-Variable ops will
be placed on the workers. return (
tf.train.replica_device_setter( worker_device= worker_device, cluster= cluster_spec), server.target, )
device, target = device_and_target() # Defining graph with tf.device(device): # TODO define your graph here ... # Defining the number of training steps hooks = [tf.train.StopAtStepHook(last_step= 100000 )] with tf.train.MonitoredTrainingSession(master= target, is_chief= (FLAGS.task_index == 0 ), checkpoint_dir= FLAGS.logs_dir, hooks= hooks) as sess: while not sess.should_stop(): # execute training step here (read data,
feed_dict, session)
# TODO define training ops data_batch = ...
feed_dict = {...}
loss, _ = sess.run(...)
原文发布时间为:2018-06-22 本文作者:专知 本文来自云栖社区合作伙伴“专知”,了解相关信息可以关注“ 专知”。
