

本文使用Scikit-learn库做机器学习。
一、问题解读
这是有监督分类问题,我们的目标是通过使用有监督机器学习模型来更好的学习消费者吐槽与产品信息之间的关系。
当有新的吐槽信息时,我们可以基于之前训练的模型给出预测结果(消费者对什么产品吐槽),然后将消费者分发给相应产品部门售后服务部门,快速高效的对消费者做出售后服务保障,提高客户满意度。
二、 数据探索
这个数据集文件(Consumer_Complaints.csv)有565M,真的很大。在训练机器学习模型前,我们先看看数据有哪些字段,他们是什么形式。
import pandas as pddf = pd.read_csv('Consumer_Complaints.csv')#前5行数据df.head(5)
在本案例我们只需要上面的两列Product和 Consumer complaint narrative(产品类别、用户抱怨描述)。
机器学习输入端输入的数据为 Consumer complaint narrative
机器学习输出端输出的数据为 Product
我们将做两个主要工作:
-
剔除掉
Consumer complaint narrative中的空值(NaN) -
将
Product产品类别转化为数字类别
#只使用两列数据(注意:这里的方括号有两层)df = df[['Product', 'Consumer complaint narrative']]#剔除掉Consumer complaint narrative列中的空数据(注意方括号只有一层)df = df[pd.notnull(df['Consumer complaint narrative'])]#将列名调整,方便后续调用df.columns = ['Product', 'Consumer_complaint_narrative']factorize()
pandas有factorize()函数,可以将标称型数据转化为数字。
factorize()的返回结果是一个包含两个数组的元组。第一个数组是转化后得到的分类数字,第二个数组为原始类别
categories = ['a', 'b', 'c', 'a', 'a', 'd', 'f']pd.factorize(categories)(array([0, 1, 2, 0, 0, 3, 4]), array(['a', 'b', 'c', 'd', 'f'], dtype=object))#将Product产品类别转化为类别数字,方便机器理解df['category_id'] = pd.factorize(df['Product'])[0]#将类别与数字信息去重,排序category_id_df = df[['Product', 'category_id']].drop_duplicates().sort_values('category_id')#类别转数字category_to_id = dict(category_id_df)#数字转类别id_to_category = dict(category_id_df[['category_id', 'Product']])df.head(5)
三、不均衡数据问题
我们看看用户对不同产品吐槽的分布情况发现产品类别是不均衡分布的。消费者对于Debt Collection、Credit report、Mortgage槽点较多。
df.groupby('Product')<pandas.core.groupby.dataframegroupby object="" at="" 0x1a3bd61278="" style="font-size: inherit;color: inherit;line-height: inherit;"></pandas.core.groupby.dataframegroupby>
df.groupby('Product').Consumer_complaint_narrative<pandas.core.groupby.seriesgroupby object="" at="" 0x1a3bd617b8="" style="font-size: inherit;color: inherit;line-height: inherit;"></pandas.core.groupby.seriesgroupby>
df.groupby('Product').Consumer_complaint_narrative.count()运行
Product Bank account or service 14887 Checking or savings account 7278 Consumer Loan 9474 Credit card 18842 Credit card or prepaid card 12058 Credit reporting 31593 Credit reporting, credit repair services, or other personal consumer reports 54480 Debt collection 66594 Money transfer, virtual currency, or money service 3494 Money transfers 1497 Mortgage 45133 Other financial service 293 Payday loan 1748 Payday loan, title loan, or personal loan 2445 Prepaid card 1450 Student loan 17380 Vehicle loan or lease 3153 Virtual currency 16 Name: Consumer_complaint_narrative, dtype: int64%matplotlib inlineimport matplotlib.pyplot as pltfig = plt.figure(figsize=(8, 6))df.groupby('Product').Consumer_complaint_narrative.count().plot.barh(ylim=0)plt.show()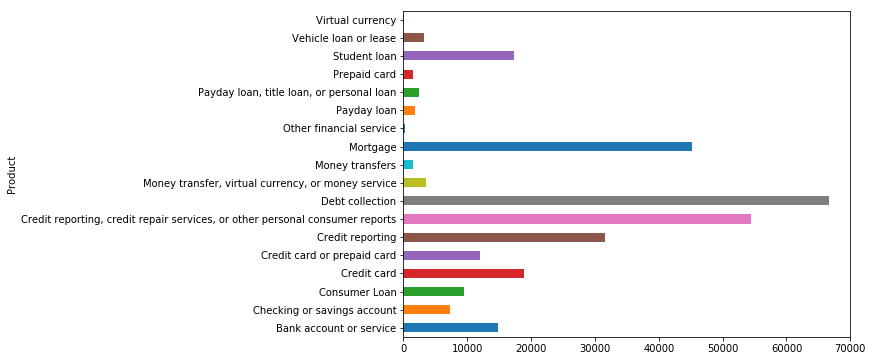
常规的机器学习算法能处理类别均匀分布的数据,但是当我们将其应用到不均衡分布的数据,常规机器学习的结果会产生偏差。
例如,如果让机器同时学习正面评论和负面评论,正面评论有800条,负面评论有200条。经过训练,模型对正面评论预测会更准,但是对负面评论准确率会大大降低。原因是学习时,机器学的好评太多,差评太少。
这种不均衡数据,会出现的问题叫做欠抽样(undersample)和过抽样(oversample)。
然而在我们的例子中,为了对少数产品类别也能预测准确,我们需要对出现次数较多的产品类别信息量瘦身。让每种产品类别数据量相对均衡。
Virtual currency一共只有16条,我们将该类剔除掉。Other financial service有293条,我们以此为基准。每一类产品随机抽取300条数据。
Bank_account_or_service = df[df.Product=='Bank account or service'].sample(300)Checking_or_savings_account = df[df.Product=='Checking or savings account'].sample(300)Consumer_Loan = df[df.Product=='Consumer Loan'].sample(300)Credit_card = df[df.Product=='Credit card'].sample(300)Credit_card_or_prepaid_card = df[df.Product=='Credit card or prepaid card'].sample(300)Credit_reporting = df[df.Product=='Credit reporting'].sample(300)Credit_reporting_credit_repair_services_or_other_personal_consumer_reports = df[df.Product=='Credit reporting, credit repair services, or other personal consumer reports'].sample(300)Debt_collection = df[df.Product=='Debt collection'].sample(300)Money_transfer_virtual_currency_or_money_service = df[df.Product=='Money transfer, virtual currency, or money service'].sample(300)Money_transfers = df[df.Product=='Money transfers'].sample(300)Mortgage = df[df.Product=='Mortgage'].sample(300)Other_financial_service = df[df.Product=='Other financial service']Payday_loan = df[df.Product=='Payday loan'].sample(300)Payday_loan_title_loan_or_personal_loan = df[df.Product=='Payday loan, title loan, or personal loan'].sample(300)Prepaid_card = df[df.Product=='Prepaid card'].sample(300)Student_loan = df[df.Product=='Student loan'].sample(300)Vehicle_loan_or_lease = df[df.Product=='Vehicle loan or lease'].sample(300)df_objs = [Bank_account_or_service, Checking_or_savings_account, Consumer_Loan, Credit_card, Credit_card_or_prepaid_card, Credit_reporting,Credit_reporting_credit_repair_services_or_other_personal_consumer_reports, Debt_collection,Money_transfer_virtual_currency_or_money_service,Money_transfers,Mortgage, Other_financial_service, Payday_loan, Payday_loan_title_loan_or_personal_loan, Prepaid_card, Student_loan,Vehicle_loan_or_lease]new_df = pd.concat(df_objs)new_df.describe()
四、文本特征提取
我们继续使用TfidfVectorizer作为文本特征提取器,TfidfVectorizer有以下参数:
-
sublinear_tf:设置为True以使用对数形式的频率。作用是将不同词语的词频量级保持在较小量级差异之内。
-
max_df: 整数或者小数(0-1),表示出现的文档数目或者文档比例。词语在文档集中出现次数超过max_df的,该词语特征不保留。 有些词语重复出现,不会带来信息量,max_df作用就是剔除掉这些词
-
min_df: 表示一个词语特征至少要出现min_df(跟max_df差不多,可以为整数或者小数),该特征才保留。
-
norm:范数,为了保证尽可能多的特征保留,使用
l2 -
ngram_range: 词元范围,这里设置为(1,2)表示我们只使用一元词袋和二元词袋。
-
stop_words:设置为
``english剔除掉停止词
from sklearn.feature_extraction.text import TfidfVectorizertfidf = TfidfVectorizer(sublinear_tf=True, min_df=5, max_df=0.8, norm='l2', ngram_range=(1, 2), stop_words='english')X = tfidf.fit_transform(new_df.Consumer_complaint_narrative).toarray()y = new_df.category_idX.shape运行
(5093, 15131)一共有5093条数据,特征数15131。
五、多分类训练
经过上面将数据变为均衡数据、提取文本特征,现在我们开始训练。朴素贝叶斯算法是非常适合应用到多分类文本分析之中的。我们使用yelloebrick做可视化查看模型预测能力,如果不熟悉的话可以查看之前的文章《yellowbrick:机器学习的可视化分析诊断库》。我们学习下如何查看训练的数据集是否均衡分布,这里使用yellowbrick。
from sklearn.naive_bayes import MultinomialNBfrom yellowbrick.classifier import ClassBalanceclf = MultinomialNB()visualizer = ClassBalance(clf)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True, random_state=100)visualizer.fit(X_train, y_train) visualizer.score(X_test, y_test) g = visualizer.poof() 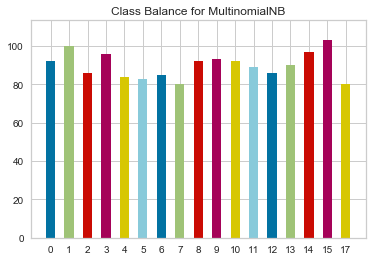
%matplotlib inlineimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import MultinomialNBfrom yellowbrick.classifier import ClassificationReportdef model_selection(X, y, estimator): X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True, random_state=100) visualizer = ClassificationReport(estimator) visualizer.fit(X_train, y_train) visualizer.score(X_test, y_test) visualizer.poof()#看看MultinomialNB分类效果model_selection(X, y, MultinomialNB())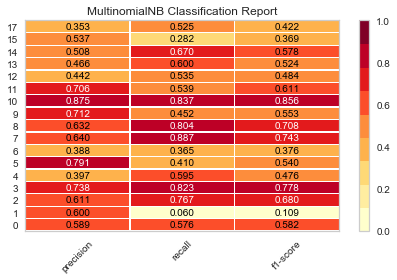
六、模型选择
我们准备使用逻辑回归、贝叶斯、支持向量机、随机森林这四种模型分别训练,并打印四种模型的表现
from sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.svm import LinearSVCfrom sklearn.model_selection import cross_val_scoreimport seaborn as snsmodels = [ RandomForestClassifier(), LinearSVC(), MultinomialNB(), LogisticRegression(random_state=0)]CV = 5entries = []for model in models: #模型的名字 model_name = model.__class__.__name__ accuracies = cross_val_score(model, X, y, scoring='accuracy', cv=CV) for fold_idx, accuracy in enumerate(accuracies): entries.append((model_name, fold_idx, accuracy))cv_df = pd.DataFrame(entries, columns=['model_name', 'fold_idx', 'accuracy'])sns.boxplot(x='model_name', y='accuracy', data=cv_df)sns.stripplot(x='model_name', y='accuracy', data=cv_df, size=8, jitter=True, edgecolor="gray", linewidth=2)plt.show()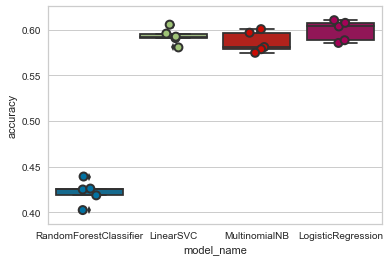
cv_df.groupby('model_name').accuracy.mean()运行
model_name LinearSVC 0.592968 LogisticRegression 0.599053 MultinomialNB 0.586291 RandomForestClassifier 0.422151 Name: accuracy, dtype: float64准确率有点低啊,不均衡的数据不是理想的数据,模型训练效果不好。今天就写到这里,大家有什么解决办法也可留言。
