

项目主要技能
- 数据拆分 .split('')
- 将不完整的数据设定为缺失数据,并将其移除
- 将完整数据清洗成列表字典(json模式)
完成心得
经过一段时间的基础练习后,这是第一个接手完成的Python项目,毕竟是自学的关系所以容易陷入窘境。然而花了很多时间在复习网易课程视频、自己的笔记、以及在JupyterNotebook练习敲的代码中去研究Python逻辑,完成这次项目后很有成就感。继续努力。
项目题目
1、成功读取“商铺数据.csv”文件
2、解析数据,存成列表字典格式:[{'var1':value1,'var2':value2,'var3':values,...},...,{}]
3、数据清洗:
① comment,price两个字段清洗成数字
② 清除字段缺失的数据
③ commentlist拆分成三个字段,并且清洗成数字
4、结果存为.pkl文件
# 成功读取“商铺数据.csv”文件
path = '/Users/alice/Desktop/商铺数据.csv'
f=open(path,'r',encoding='UTF-8')
for i in f.readlines()[:10]: #给定范围(几笔数据)
print(i.split(',')[2]) #只print(i)太乱,按照逗号做split

#数据清洗:① comment,price两个字段将有完整数据的各'关键点'找出来并清洗成数字,没有关键点的一律成为缺失数据
f.seek(0)
def fcm(s):
if '条' in s: #comment:没有‘条’即表示缺失数据
return(int(s.split(' ')[0])) #以提行拆分后选择索引[0],最后进行数字整型化int()
else:
return('缺失数据')
for i in f.readlines()[:10]:
comm_count = fcm(i.split(',')[2]) #以逗号拆分并提出索引2位置的值为评论数的参数
print(comm_count)

def fpr(s):
if '¥' in s: #price:没有‘¥’即表示缺失数据
return(int(s.split('¥')[-1])) #以‘¥’作为拆分,并提取索引[-1]的值做数字整型化
else:
return('缺失数据')
for i in f.readlines()[:10]: #给定范围比较不会太多数据影响效率
price = fpr(i.split(',')[4]) #以逗号拆分数据并且提出索引4位置的值为price的参数
print(price)

#数据清洗:③ commentlist拆分成三个字段,并且清洗成数字
for i in f.readlines()[40:50]: #给定范围(几笔数据)
print(i.split(',')[-1].split(' '))
#以逗号拆分后取最后一个值,并且再以提行拆分成三个字段。
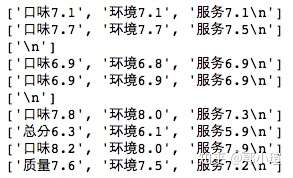
def fcl(s):
if len(s) == 3:
quality = float(s[0][2]) #第0个索引(质量)然后提取索引2位置(数字)为质量的值
environment = float(s[1][2])
service = float(s[2][2])
return([quality,environment,service])
else:
return('缺失数据')
for i in f.readlines()[40:50]:
commentlist = fcl(i.split(',')[-1].split(' '))
print(commentlist)
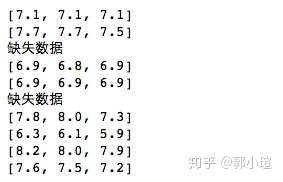
#数据清洗:② 清除字段缺失的数据:只将完整数据纳入新列表
f.seek(0) #将光标返回到开头,才能成功读取。
n=0
m=[]
for i in f.readlines()[1:]: #第一列(索引0)为标头,所以要从索引1开始读
data = (i.split(','))
#print(data) #data就是全部的数据
classi = data[0]
name = data[1]
comm_count = fcm(data[2]) #按照上面的自定义函数表示
star = data[3]
price = fpr(data[4])
add = data[5]
quali = fcl(data[-1].split(' '))[0] #直接从上面复制粘贴,将 (i.split(','))改成data。
envir = fcl(data[-1].split(' '))[1] #在最后表示每一个字段的索引位置
servi = fcl(data[-1].split(' '))[2]
if '缺失数据' not in [comm_count,price,quali,envir,servi]:
n+=1
datalst = [[ 'Classify', classi ], [ 'Restaurant', name ], [ '评论数量', comm_count ], [ '星级', star ], [ 'Price', price ], [ 'Address', add ], [ 'Quality', quali ], [ 'Environment', envir ], [ 'Service', servi ]]
#print(datalst) # 为复合列表,可进行转化成字典格式
#print(dict(datalst))
m.append(dict(datalst)) # 解析数据,存成列表字典格式:[{'var1':value1,'var2':value2,'var3':values,...},...,{}]
print(m[50:55])
print('------------------------')
print('成功读取共%i笔完整数据' %n) #将readlines()[]范围去掉,才可完整读取。
print('------------------------')
f.close()
print('finished!')

# 结果存为.pkl文件: pickle.dump()
import pickle
pic_file = open('/Users/alice/Desktop/商铺数据完整版.pkl','wb')
pickle.dump(m, pic_file) #m就是上面的列表字典内容
pic_file.close()
print('finished!')
finished!
# 读取.pkl文件: pickle.load()
在之后的Python中都可以任意import pickle并读取此次.pkl文件的内容
import pickle
file2 = open('/Users/alice/Desktop/商铺数据完整版.pkl','rb')
datalst = pickle.load(file2)
print(datalst[:10])

项目完成
