

以下内容仅为最近面试的一些知识点总结,答案也是我后来通过查各种资料后的总结。若有不准确甚至错误的地方,还请路过大神指正,在此感谢。
php
关于array的数组
extends和implements的区别
- 一个php对象只能继承一个父类,单继承;但可以实现多个接口类
- extends会继承父类的所有属性和方法,也可以对父类的方法进程重写。接口类方法中不能写逻辑,implements需要实现的类完全实现抽象类中的方法。
php7的新改变
- 类型的声明:可使用字符串,整数,浮点数来声明函数的参数类型与返回值类型
- 新增操作符
<=>,$a<=>$b,当b时,为1,相等为0,
b为-1
- 新增操作符
??,$a ?? 1;当$a存在并不为null,返回$a本身,反之返回1 - 定义常量数组
define('A', [1,2]); - 命名空间引用优化
use AppBundle\Entity\{A,B};
设计模式
php设计模式和应用场景
-
单例模式:
解决如何在整个项目中创建唯一对象实例问题
应用场景:当某个类只能被实例化一次的时候需要使用这个模式。例如:数据库连接
-
工厂模式
-
简单工厂模式:
解决当某个类改名后,所有调用这个类的地方都要改名。也就是通过一个工厂类定义方法,创建某个类,当改名时,只需修改工厂类里面的名称即可。
应用场景:需要多处进行实例化的类
-
抽象工厂模式
对简单工厂中的工厂类进一步抽象成接口。如有新增对象时,只要在实现对应的工厂类,不用修改之前的工厂类。
应用场景:适用于增加新工厂,不适用于增加产品线
-
-
策略模式
-
注册模式
-
适配器模式
-
观察者模式
-
装饰器模式
-
原型模式
手写单例模式(例子而已)
<?php
class Singleton
{
private static $instance;
private function __construct() {}
private function __clone() {}
static public function get()
{
if (!self::$instance) {
self::$instance = new Singleton();
}
return self::$instance;
}
}
Singleton::get();
git
git新建分支有几种方式
git checkout -b 分支
它是下面两条命令的简写
git branch 分支
git checkout 分支
因此两种方式可创建新分支
composer
使用composer好处
- 项目开发成员使用同版本的bundle,减少分歧
- 保证生产环境和开发环境使用bundle统一
- 不需要关心包的依赖性问题,也不会出现多个bundle依赖同一个bundle时,重复下载
- 当bundle有新的更新时,只需要
composer update,不需要手动修改任何文件
mysql
覆盖索引:包含所有满足查询需要的数据的索引(explain中extra为using index)
聚集索引:物理索引,也就是表中数据的物理顺序和索引顺序相同。一个表只能有一个聚集索引,一般为主键id,当没有主键id时,会以第一个唯一非空索引为聚集索引。若没有合适的唯一索引,innodb会自动生成隐藏的主键作为聚集索引
强制索引:当有多索引时,mysql会自动选择一个索引进行使用,而我们并不想使用此索引时,就会用到强制索引。使用方法:from 表名 index(要使用的索引名)
聚集索引和非聚集索引区别
- 聚集索引一张表只能有一个,非聚集所以可存在多个
- 聚集索引存储记录是物理上连续,非聚集索引是逻辑上连续
- 聚集索引: 物理存储按照索引排序;聚集索引是一种索引组织形式,索引的键值逻辑顺序决定了表数据行的物理存储顺序
非聚集索引: 物理存储不按照索引排序;非聚集索引则就是普通索引了,仅仅只是对数据列创建相应的索引,不影响整个表的物理存储顺序.
- 索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
优势与缺点 :
聚集索引插入数据时速度要慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入),查询数据比非聚集数据的速度快
查一行数据的最大值:greatest(字段)
mysql存储引擎
nosql
memcache和redis区别
- 数据结构:memcache只有key/value(value限制大小1M),redis数据类型较为丰富,string、list、hash、set、zset(512M)
- 存储:memcache存储在内存中,redis可以定期存储在磁盘中。因此redis数据具有持久化的特点
- 性能:Redis单核,memcache多核。在100k以上数据,memcache性能高于redis
memcache和redis的应用场景
memcache应用场景:
- 减少数据库负载,提升性能,需要缓存只是简单的key-value结构数据,并且value小于1M,适合多读少写
- 秒杀功能
redis应用场景:
- 数据需要持久化
- 处理业务复杂的数据
- 对安全性要求高的
redis持久化的方式
有两种持久化方式:RDB持久化和AOF持久化
RDB持久化是将redis内存中的数据定时dump到磁盘上
AOF持久化是将redis的操作日志以追加的形式写入文件
二者区别
RDB持久化是指定时间间隔内将内存中数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,成功后,在替换之前的文件,用二进制压缩存储。
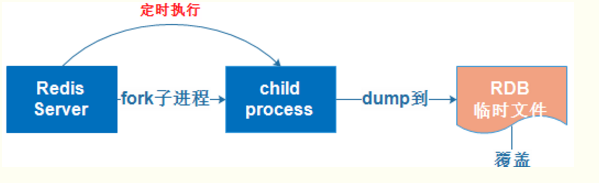
AOF持久化是以日志的形式记录服务器每个写、删除操作

redis中set和list区别
list是链表结构,双向链表,可以在左右两边对数据进行操作;有序
set是一个集合,集合中的数据不能重复;无序
前端
如何理解css盒模型
盒模型,从里到外,content,padding,border,margin
分为w3c标准模型和ie模型
两者的区别在于,w3c模型的height是content的height,width是content的width。而ie的height和width是content+padding+border的height和width;
服务器
从浏览器输入地址到页面展现的过程
- 根据域名寻找ip
- 通过ip找到服务器
- 向服务器发送三次握手,建立连接
- 向服务器发送请求
- Nginx通过配置文件,执行相应的操作。当请求为静态请求时,直接找到静态文件。当请求为动态请求时,将调用fastcgi接口,也就是socket
- socket将请求传给php-fpm,php-fpm通过master找到空闲的进程wrapper,将请求传给他进行php的解析处理。
- 解析完成后,wrapper将结果通过fastcgi接口,沿着固定的socket传递给Nginx,Nginx将数据传回客户端
- 浏览器就行dom渲染
如何通过域名寻找到ip
- 浏览器缓存中查找
- 本地host查找
- DNS解析中查找
- 到Root Server域名服务器解析
- 根据根域名返回的主域名服务器地址发送请求找到二级域名地址
- 在获取三级域名,直到最后获取了域名的ip返回
Nginx和php是如何通信的
Nginx和php之间是通过fastcgi接口,而具体实现fastcgi接口的方式有两种:
一种是unix socket。优点:快,消耗资源少
另一种是tcp socket。优点:Nginx和php-fpm不再相同机器上时,可通信。像负载均衡。保证数据正确性、完整性
php-fpm的配置参数
pm:dynamic (动态);static(静态)
当pm为static时:
pm.max_children:n (进程数量)
当pm为dynamic时:
pm.min_spare_servers (空闲进程最小值)
pm.max_spare_servers (空闲进程最大值)
pm.start_server (启动时的进程数)
GET和POST区别
-
语义不同,get用于获取数据,post用于提交数据
-
get的url长度是和浏览器有关的,http协议中并没有做限制。ie为2803字符;Chrome 8182;firefox 65536;Safari 80000。Apache:8192;Nginx:配置:
client_header_buffer_size和large_client_header_buffer配置。post也是没有限制的,php中POST参数大小是有做限制的,
post_max_size默认为20m -
get是幂等的,post是不幂等的。【幂等:一次请求和多次请求具有同样的副作用=】
-
POST相对get请求来说会安全一些
session和cookie区别
- session存在服务器端,cookie存在客户端
- session一般依赖于cookie:session是用session ID来确认当前会话的,而session id 是存在cookie中,通过cookie来进行传递的。
【那浏览器禁用cookie之后是不是session就没有作用了呢】 在php中,通过配置session.use_trans_sid=1,可以使得当浏览器禁用cookie的时候,通过url传参将session id传过去。(url重写)
- cookie不是很安全,访问页面时可以进行cookie伪装。
可以在哪些地方做缓存
-
数据库端缓存
单独使用一张表存储统计结果,定时进行更新。提高查询速度和数据库性能。
-
应用层缓存
缓存数据库查询结果,memcache、redis
缓存磁盘文件数据。常用数据可存至内存
-
前端缓存 一般css,js,图片静态文件这样缓存比较多
-
客户端缓存 浏览器访问一次后,缓存在浏览器端,在请求不向服务器发起请求,减轻服务器分担加快访问速度
HTTP状态码
301 永久重定向
302 临时重定向
414 url长度过长,超过限制
419 客户端访问过于频繁,超出限制
503 服务器超负荷,暂时不能处理请求
http和https的区别
- http传输内容为明文未加密的,较为不安全;https是基于http+ssl协议进行加密传输
- https需要申请证书,需要费用
- http端口是80;https端口是443
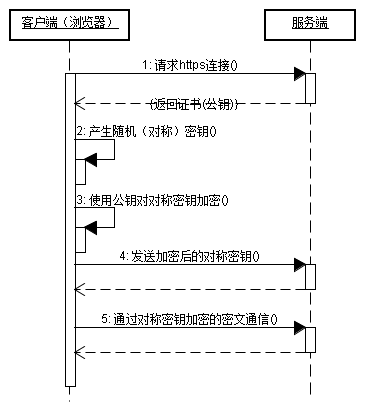
https需要几次握手
负载均衡原理
- 重定向实现负载均衡
- DNS负载均衡
- 反向代理负载均衡
- ip负载均衡
负载均衡策略
- 轮询:依次分发到每台应用服务器上,所以每台处理请求数相同
- 加权轮询:按照配置的权重将请求分发,高性能的服务器分配更多请求。
- 随机:随机分配
- 加权随机:
- 最少连接:记录每个应用服务器正在处理的连接数,将新的请求分发到最少连接的服务器上。
- 加权最少连接
- 源地址散列:根据来源的IP地址进行Hash计算得到应用服务器,这样来自同一个IP地址的请求总在同一个服务器上处理。该请求的上下文信息可以存储在这台服务器上
linux常用操作命令
日志分析
查看访问量前十的ip
cat log | awk '{print $n}' | sort | uniq -c | sort -k 1 -n -r | head -10
查看日志中出现一百次以上的ip
cat log | awk '{print $n}' |sort | uniq -c |awk '{if ($1>100) print $0}' |sort -nr
查看页面中访问超过100次的页面
cat log | awk '{print $7}' | sort | uniq -c | awk '{if ($1>100) print $0}'
统计某url一天的访问次数
cat log | grep '04/Jun/2018' | grep 'url/url...' | wc | awk '{print $1}'
进程
查看进程:ps -ax (-a all;-x 显示没有控制终端的进程)
查看所有php进程:ps -ax | grep php
杀某个进程:kill -9 进程号
杀掉所有php进程:pkill -9 php
