


Summary of background
论文链接:arxiv.org/abs/1711.11…
论文代码:暂未公布
在深度学习兴起前,目标检测领域不少改进方法都是在经典检测模型上加入对象的上下文信息和对象间的关系以提升目标检测的性能,但这种方式在深度学习的架构中似乎不怎么起作用(以前我也想过这种改进方法,但深度学习发展的还真像炼丹,直接丢原始数据训练效果反而更好),这是由于深度学习发展到如今仍然是一个黑盒模型,主流的观点认为卷积神经网络具有很大的感受野,在网络训练时已经学习到了对象的上下文信息。
这篇文章算是将关系模型应用到CV领域很成功的文章了,由于是受到谷歌在NLP方向的文章《Attention
is All You Need》的启发,文中的许多变量公式都与谷歌的文章对比。谷歌的文章中完全基于Attention,而没有使用任何神经网络的结构,却取得了state-of-the-art的效果。由于我对NLP不怎么了解,在看这篇文章前还没有看过谷歌的文章。不过这篇文章的思路很有趣,相信从Attention模型的巧妙和CNN强大的特征提取能力结合这个角度出发,会有更多值得期待的改进。
Object Relation Module
在之前使用CNN进行目标检测的方法中,都是每个对象被单独识别,而这篇文章将一组对象同时做了Relation Module处理,即一个对象上融合了其他对象的关系特征,
好处在于丰富了特征,而且Relation Module处理前后,维度不会发生变化,这意味着该模型可以扩展到经典的任意基于CNN的目标检测框架中。
该模型的模块示意图如下:
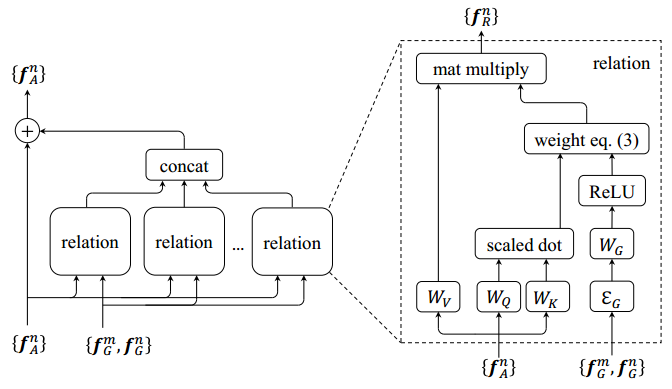
其中对每一个对象有几何特征
f
G
" role="presentation" style="position: relative;">(四维的bbox),外观特征
f
A
" role="presentation" style="position: relative;">
(文中为1024维),给定N个对象的输入集合为
{
f
A
n
,
f
G
n
}
n
=
1
N
" role="presentation" style="position: relative;">
,对于第n个对象,则它的关系特征为
其中
W
V
" role="presentation" style="position: relative;">为显性转换,
ω
m
n
" role="presentation" style="position: relative;">
为关系权重,表示该对象受到其他对象的影响。
分母是对分子的 归一化,
ω
A
m
n
" role="presentation" style="position: relative;">为外观权重,用点积dot计算
其中
W
K
" role="presentation" style="position: relative;">与
W
Q
" role="presentation" style="position: relative;">
用于将原始特征
f
A
m
" role="presentation" style="position: relative;">
和
f
A
n
" role="presentation" style="position: relative;">
投影到子空间,以测量它们之间的匹配程度。
W
G
m
n
" role="presentation" style="position: relative;">
为几何权重,
其中
W
G
m
n
" role="presentation" style="position: relative;">的计算分为两步
- 将两个对象的几何特征嵌入到高维表示中,记为
ξ
G
" role="presentation" style="position: relative;">
,计算目标m和n的相对位置 ( l o g ( x m − x n ω m ) , l o g ( y m − y n h m ) , l o g ( ω n ω m ) , l o g ( h n h m ) ) T " role="presentation" style="position: relative;">
,这是一个四维的向量,分别表示中心点的坐标和宽高。
- 将4维的相对位置矩阵映射到64维向量,再与
W
G
" role="presentation" style="position: relative;">
做内积,然后再通过ReLU激活函数。
式(1)中的
f
R
(
n
)" role="presentation" style="position: relative;">表示第n个对象提取的一个关系特征(relation feature),一个对象会提取
N
r
" role="presentation" style="position: relative;">
种关系特征(作者的论文中是16种),然后将
N
r
" role="presentation" style="position: relative;">
种关系特征concat起来,再与原来第n个对象本身的特征相加,得到融合关系特征后的特征,公式如下:
为了匹配关系特征和对象本身的特征间的维度,
W
V
" role="presentation" style="position: relative;">能对
f
A
m
" role="presentation" style="position: relative;">
起到降维的作用。
Relation Networks For Object Detection
这篇文章是将提出的relative module应用于目标检测,目前基于CNN的目标检测架构包含4个步骤
- 现在大数据集(一般是ImageNet)上预训练网络模型;
- 提取候选区域特征
- 实例检测
- 去除重复检测框
作者基于relative module的特性,将relative module用于每个全连接层之后,并且替代常用的NMS算法去除重复检测框。如下图所示
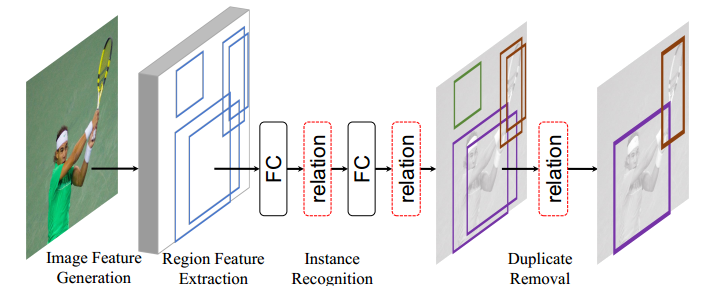
Relation for Instance Recognition
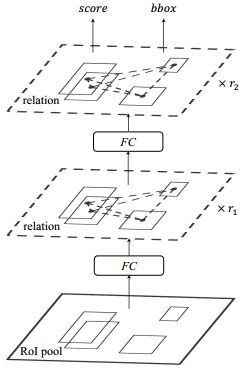
在原本的RCNN模型中,经过ROI Pooling处理后,会经过两个全连接层后再进行边界框回归和目标分类,步骤如下图
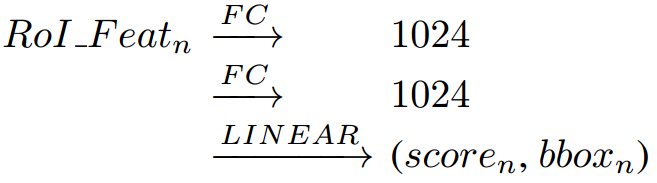
由于relative module处理特征后,特征的维度不会发生变化,因此可以在每个全连接层后接一个relative module。则实例检测的流程变为:
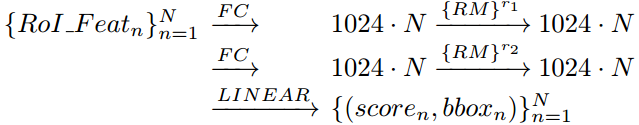
在上式中,R1和R2表示为relative module重复的次数。Instance Recognition的检测示意图如下图所示。
Relation for Duplicate Removal
作者首先指出NMS由于是贪心算法且需要手工选择参数,是一个次优选择,然后说明Duplicate Removal问题实际是一个二分类问题,即对于每一个ground truth object,只有一个检测框是正确的,其余的检测框都可认为是duplicate。
作者提出的这个模块的输入是instance recognition的输出,也就是一系列检测对象,每个对象都有1024维的特征,携带的信息有Bbox和分类分数
s
0
" role="presentation" style="position: relative;">,从下图可以看到模块的输出是s_0和s_1的乘积,接下来看看
s
1
" role="presentation" style="position: relative;">
的计算方法。这个模块的具体步骤如下
- 首先作者指出将分类分数转换为rank更有效,而不是具体的数值。然后将rank和1024维的appearance feature转换为128维(通过上图中的
W
f
R
" role="presentation" style="position: relative;">
和 W f " role="presentation" style="position: relative;">
)
- 将融合后的特征通过relation module改变所有对象的外观特征
- 将每个转换的特征通过线性分类(下图中的
W
s
" role="presentation" style="position: relative;">
),再通过Sigmoid将输出归一化到[0,1]之间。
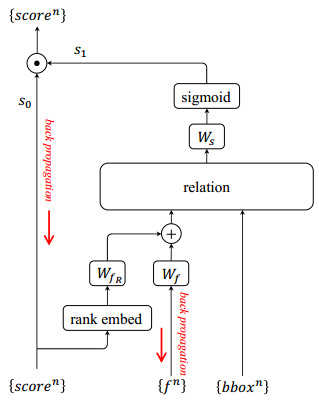
relation module是上述步骤的核心,因为使用relation module可以是整合Bbox,原始的appearance feature和分类分数,使整个目标检测框架仍然是一个端到端的模型。
紧接着面临的任务就是如何判断哪个detected object是正确,哪些是duplicate。作者首先设置了一个阈值
η" role="presentation" style="position: relative;">,输出大于该阈值的都会保留,然后在保留的detected object中,选择IOU最大的作为正确的保留,其余为duplicate。
Experiments
实验部分数据集是具有80个类别的COCO数据集,CNN模型用的ResNet-50和ResNet101。
Relation for Instance Recognition
首先看Instance Recognition的实验,首先比较了单纯2fc的Instance Recognition,和2fc+RM(relation module),比较了RM的多种参数。

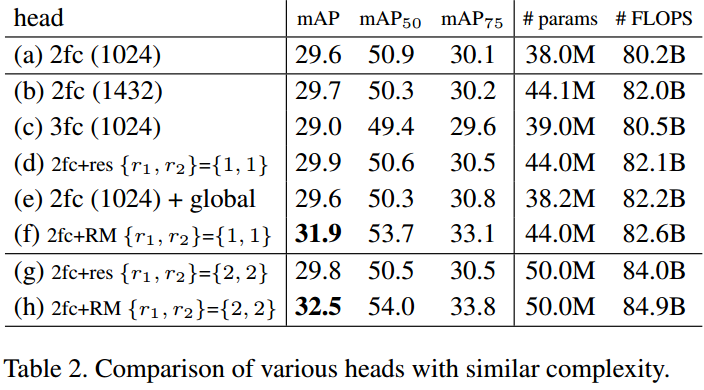
从上图可以看到,使用rank这个策略确实能使准确率提升,但作者没有解释这是为什么。
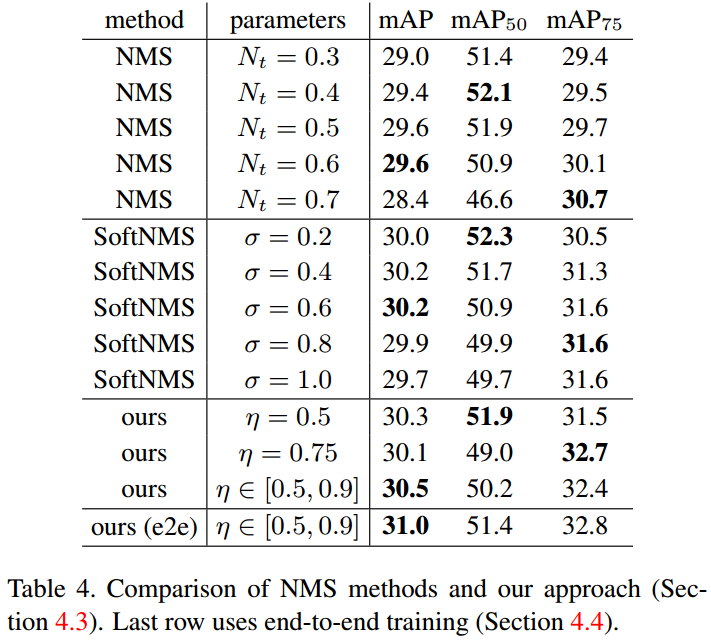
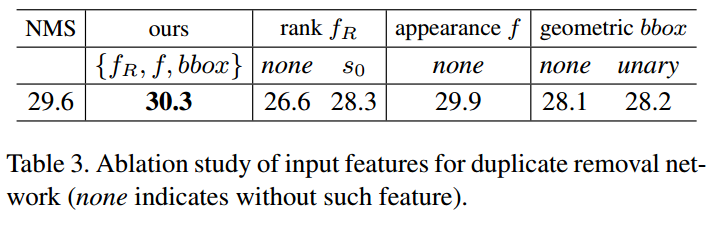
Relation for Duplicate Removal
多种网络模型,多种参数比较
Relation module究竟学习到了什么
作者提出的Relation module是一个很好的研究点,遗憾的是文中没有很好的解释Relation module学到了什么,作者说这个不在文章的讨论范围。为了对文章所提出的模型给出一个直观的解释,作者分析了Relation module中最后一个fc之后的RM中的关系权重,如下图所示,蓝色代表检测到的物体,橙色框和数值代表对该次检测有帮助的关联信息。

作者提出的问题
1.只有一个样本被划分为correct,会不会导致严重的正负样本不均衡?
答案是否定,网络工作的很好,这是为什么呢?因为作者实际运行发现,大多数的object的 s 0 " role="presentation" style="position: relative;">得分很低,因此 s 0 " role="presentation" style="position: relative;">
就很小,从而导致 L = − l o g ( 1 − s 0 s 1 )" role="presentation" style="position: relative;">
和梯度 ∂ L ∂ S 1 " role="presentation" style="position: relative;">
都会比较小。
2.设计的两个模块功能是否矛盾?因为instance recognition要尽可能多地识别出high scores的物体,而duplicate removal的目标是只选择一个正样本。作者认为这个矛盾是由 s 0 " role="presentation" style="position: relative;">
3.duplicate removal是一个可以学习的模块,和NMS不同,在end2end训练中,instance recognition输出的变化会直接影响到该模块,是否会产生不稳定性?答案也是否定的,实际上,作者发现end2end的训练方式更好,作者认为这是由于不稳定的label某种程度上起到了平均正则化的作用。
