

在帝都打拼的小伙伴都知道,要租个合适的房子真心不易。中介要收一个月的房租作为中介费。而且很多黑中介打着租房的旗号各种坑蒙拐骗。要想在茫茫帖子中找到真正的房东,宛如大海捞针,同时需要和各路黑中介斗智斗勇。接下来就讲讲我浴血奋战的故事。
那么,How to start? 我们先选一块阵地。58赶集这样的网站,可以说中介占了大多数,地势险峻,易守难攻,果断放弃。闲鱼呢,资源又太少,攻下来的意义也不大,所以也放弃。我把目标放在了豆瓣上。在帝都的童鞋大部分都知道,豆瓣小组里面有很多租房小组,年轻人居多,很多都是转租,但很大一部分是和房东签的合同,省掉了中介费。我大致翻了一下,基本上一天内的更新量能刷到90页,每页25条数据,当然有一些是旧的被顶上来的。这个数据量已经不少了,虽然里面也混杂着大量的中介,但是相对来说比其他地方好很多。
郑重声明:各位在爬取数据的时候一定要控制频率,不要影响网站的正常访问!而且频率过高会被豆瓣干掉,且爬且珍惜! 另外,请详细阅读注释中的内容!
我们先分析一下要抓取页面的结构。以大名鼎鼎的北京租房小组举例。

https://www.douban.com/group/beijingzufang/discussion?start=0,第二页为https://www.douban.com/group/beijingzufang/discussion?start=25,每页25条数据,很清晰明了了吧?
这时候,我们只需要分别获取到每页的数据,然后再做一些过滤,就可以极大减少筛选的时间了。我们选择前二十个页面来作为爬取对象,一方面不会对网站造成影响,另一方面也保证数据尽可能使最新。
好的,重点来了,作为一个前端,我使用node来做抓取,先引入一些必要的依赖。
import fs from 'fs' // node的文件模块,用于将筛选后的数据输出为html
import path from 'path' // node的路径模块,用于处理文件的路径
// 以下模块非node.js自带模块,需要使用npm安装
// 客户端请求代理模块
import superagent from "superagent"
// node端操作dom的利器,可以理解成node版jQuery,语法与jQuery几乎一样
import cheerio from "cheerio"
// 通过事件来决定执行顺序的工具,下面用到时作详解
import eventproxy from 'eventproxy'
// async是一个第三方node模块,mapLimit用于控制访问频率
import mapLimit from "async/mapLimit"
然后就可以把我们要抓取的页面整理到一个数组里面了
let ep = new eventproxy() // 实例化eventproxy
let baseUrl = 'https://www.douban.com/group/beijingzufang/discussion?start=';
let pageUrls = [] // 要抓取的页面数组
let page = 20 // 抓取页面数量
let perPageQuantity = 25 // 每页数据条数
for (let i = 0; i < page; i++) {
pageUrls.push({
url: baseUrl + i * perPageQuantity
});
}
简单分析下页面的dom结构。页面中的有效数据全在table中,第一个tr是标题,接下来每个tr对应一条数据。然后每个tr下有4个td。分别存放着标题,作者,回应数和最后修改时间。
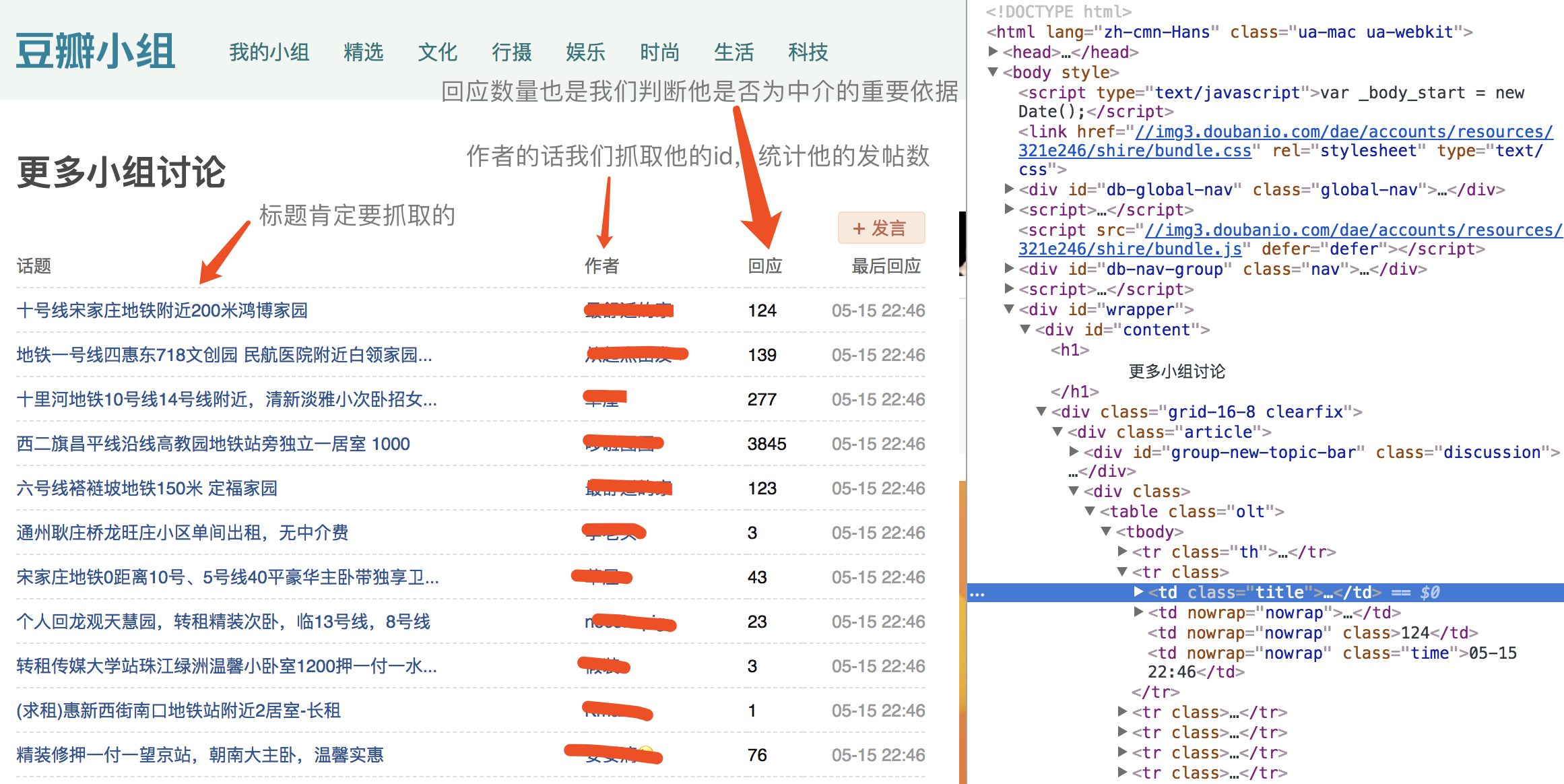
我们先写个入口函数,访问所有要抓取的页面并保存我们需要的数据。话说,好久不写jQuery都有点手生了。
function start() {
// 遍历爬取页面
const getPageInfo = (pageItem, callback) => {
// 设置访问间隔
let delay = parseInt((Math.random() * 30000000) % 1000, 10)
pageUrls.forEach(pageUrl => {
superagent.get(pageUrl.url)
// 模拟浏览器
.set('User-Agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36')
// 如果你不乖乖少量爬数据的话,很可能被豆瓣kill掉,这时候需要模拟登录状态才能访问
// .set('Cookie','')
.end((err, pres) => {
let $ = cheerio.load(pres.text) // 将页面数据用cheerio处理,生成一个类jQuery对象
let itemList = $('.olt tbody').children().slice(1, 26) // 取出table中的每行数据,并过滤掉表格标题
// 遍历页面中的每条数据
for (let i = 0; i < itemList.length; i++) {
let item = itemList.eq(i).children()
let title = item.eq(0).children('a').text() || '' // 获取标题
let url = item.eq(0).children('a').attr('href') || '' // 获取详情页链接
// let author = item.eq(1).children('a').attr('href').replace('https://www.douban.com/people', '').replace(/\//g, '') || '' // 获取作者id
let author = item.eq(1).children('a').text() || '' // 这里改为使用作者昵称而不是id的原因是发现有些中介注册了好多账号,打一枪换个地方。虽然同名也有,但是这么小的数据量下,概率低到忽略不计
let markSum = item.eq(2).text() // 获取回应数量
let lastModify = item.eq(3).text() // 获取最后修改时间
let data = {
title,
url,
author,
markSum,
lastModify
}
// ep.emit('事件名称', 数据内容)
ep.emit('preparePage', data) // 每处理完一条数据,便把这条数据通过preparePage事件发送出去,这里主要是起计数的作用
}
setTimeout(() => {
callback(null, pageItem.url);
}, delay);
})
})
}
}
我们通过mapLimit来控制访问频率,mapLimit的细节参照官方文档。传送门
mapLimit(pageUrls, 2, function (item, callback) {
getPageInfo(item, callback);
}, function (err) {
if (err) {
console.log(err)
}
console.log('抓取完毕')
});
简单说一下过滤的策略吧,首先在标题里,过滤掉不合适的地点,以及中介最常用的话术。也可以自己添加想要的关键词,有针对性的进行筛选。然后统计每个作者的发帖数,这里的判断条件是如果每个人发帖数在抓取的页面中出现超过5次以上,则被认为是中介。如果某个帖子的回复量巨大,要么是个旧帖子被顶上来了,要么很可能是有人在不停的刷排名,我这里设置的阈值是100。试想一个正常的房东不会这么丧心病狂的刷存在感,因为好房根本不愁租不出去,很可能是中介每天在刷旧帖子。即便是因为房子比较好所以大家都在围观,那其实你租到的概率已经很小了,所以直接过滤掉。
// 我们设置三个全局变量来保存一些数据
let result = [] // 存放最终筛选结果
let authorMap = {} // 我们以对象属性的方式,来统计每个的发帖数
let intermediary = [] // 中介id列表,你也可以把这部分数据保存起来,以后抓取的时候直接过滤掉!
// 还记得之前的ep.emit()吗,它的每次emit都被这里捕获。ep.after('事件名称',数量,事件达到指定数量后的callback())。
// 也就是说,总共有20*25(页面数*每页数据量)个事件都被捕获到以后,才会执行这里的回调函数
ep.after('preparePage', pageUrls.length * page, function (data) {
// 这里我们传入不想要出现的关键词,用'|'隔开 。比如排除一些位置,排除中介常用短语
let filterWords = /押一付一|短租|月付|蛋壳|有房出租|6号线|六号线/
// 这里我们传入需要筛选的关键词,如没有,可设置为空格
let keyWords = /西二旗/
// 我们先统计每个人的发帖数,并以对象的属性保存。这里利用对象属性名不能重复的特性实现计数。
data.forEach(item => {
authorMap[item.author] = authorMap[item.author] ? ++authorMap[item.author] : 1
if (authorMap[item.author] > 4) {
intermediary.push(item.author) // 如果发现某个人的发帖数超过5条,直接打入冷宫。
}
})
// 数组去重,Set去重了解一下,可以查阅Set这种数据结构
intermediary = [...new Set(intermediary)]
// 再次遍历抓取到的数据
data.forEach(item => {
// 这里if的顺序可是有讲究的,合理的排序可以提升程序的效率
if (item.markSum > 100) {
console.log('评论过多,丢弃')
return
}
if (filterWords.test(item.title)) {
console.log('标题带有不希望出现的词语')
return
}
if(intermediary.includes(item.author)){
console.log('发帖数过多,丢弃')
return
}
// 只有通过了上面的层层检测,才会来到最后一步,这里如果你没有设期望的关键词,筛选结果会被统统加到结果列表中
if (keyWords.test(item.title)) {
result.push(item)
}
})
// .......
});
到此为止,我们已经拿到了期望的结果列表,但是直接打印出来,并不那么的好用,所以我们把它生成一个html。我们只需简单的进行html的拼装即可
// 设置html模板
let top = '<!DOCTYPE html>' +
'<html lang="en">' +
'<head>' +
'<meta charset="UTF-8">' +
'<style>' +
'.listItem{ display:block;margin-top:10px;text-decoration:none;}' +
'.markSum{ color:red;}' +
'.lastModify{ color:"#aaaaaa"}' +
'</style>' +
'<title>筛选结果</title>' +
'</head>' +
'<body>' +
'<div>'
let bottom = '</div> </body> </html>'
// 拼装有效数据html
let content = ''
result.forEach(function (item) {
content += `<a class="listItem" href="${item.url}" target="_blank">${item.title}_____<span class="markSum">${item.markSum}</span>____<span class="lastModify">${item.lastModify}</span>`
})
let final = top + content + bottom
// 最后把生成的html输出到指定的文件目录下
fs.writeFile(path.join(__dirname, '../tmp/result.html'), final, function (err) {
if (err) {
return console.error(err);
}
console.log('success')
});
最后,我们只需把入口函数暴露出去即可
export default {
start
}
由于我们是使用ES6的语法写的,所以在使用的时候,需要借助babel-node。首先安装babel-cli,你可以选择全局安装或者局部安装, npm i babel-cli -g。同时别忘了文章开头三个依赖的安装。
最终我们在index.js文件中引入上面的脚本,并执行babel-node index.js。我们看到了激动人心的success。
// index.js
import douban from './src/douban.js'
douban.start()

最后我们打开HTML看一看效果吧,标红的是回复数量,点击标题可以直接跳转到豆瓣对应的页面。同时,利用a标签点击过后变色的效果,我们可以方便的判断是否已经看过这条数据。

我简单设置了一些过滤条件,数据由500条直线下降到138条,极大的缩短了我们的筛选时间。如果我加一些指定的筛选关键词,搜索结果还会更精准!
好了,时候不早了,今天的分享就到此为止。如果大家觉得找房子比较费劲,还是要去找链家,我爱我家等这样的大中介,比较靠谱省心。最后祝大家找到暖心的小窝!
