

本来是想写aop设计机制的,但是最近被session这个东西搞得有点头大,所以就抽点时间来整理下关于session的一些东西。
目录
- 从http协议的无状态性说起
- Cookie
- Session
从http协议的无状态性说起
HTTP是一种无状态协议。关于这个无状态之前我也不太理解,因为HTTP底层是TCP,既然是TCP,就是长连接,这个过程是保持连接状态的,又为什么说http是无状态的呢?先来搞清楚这两个概念:
无连接和无状态
-
无连接
每次连接只处理一个请求,服务端处理完客户端一次请求,等到客户端作出回应之后便断开连接;
-
无状态
是指服务端对于客户端每次发送的请求都认为它是一个新的请求,上一次会话和下一次会话没有联系;
无连接的维度是连接,无状态的维度是请求;http是基于tcp的,而从http1.1开始默认使用持久连接;在这个连接过程中,客户端可以向服务端发送多次请求,但是各个请求之间的并没有什么联系;这样来考虑,就很好理解无状态这个概念了。
持久连接
持久连接,本质上是客户端与服务器通信的时候,建立一个持久化的TCP连接,这个连接不会随着请求结束而关闭,通常会保持连接一段时间。
现有的持久连接类型有两种:HTTP/1.0+的keep-alive和HTTP/1.1的persistent。
- HTTP/1.0+的keep-alive
先来开一张图:

connection: keep-alive
我们每次发送一个HTTP请求,会附带一个connection:keep-alive,这个参数就是声明一个持久连接。
- HTTP/1.1的persistent
HTTP/1.1的持久连接默认是开启的,只有首部中包含connection:close,才会事务结束之后关闭连接。当然服务器和客户端仍可以随时关闭持久连接。
当发送了connection:close首部之后客户端就没有办法在那条连接上发送更多的请求了。当然根据持久连接的特性,一定要传输正确的content-length。
还有根据HTTP/1.1的特性,是不应该和HTTP/1.0客户端建立持久连接的。最后,一定要做好重发的准备。
http无状态
OK,首先来明确下,这个状态的主体指的是什么?应该是信息,这些信息是由服务端所维护的与客户端交互的信息(也称为状态信息); 因为HTTP本身是不保存任何用户的状态信息的,所以HTTP是无状态的协议。
如何保持状态信息
在聊这个这个问题之前,我们来考虑下为什么http自己不来做这个事情:也就是让http变成有状态的。
-
http本身来实现状态维护
从上面关于无状态的理解,如果现在需要让http自己变成有状态的,就意味着http协议需要保存交互的状态信息;暂且不说这种方式是否合适,但从维护状态信息这一点来说,代价就很高,因为既然保存了状态信息,那后续的一些行为必定也会受到状态信息的影响。
从历史角度来说,最初的http协议只是用来浏览静态文件的,无状态协议已经足够,这样实现的负担也很轻。但是随着web技术的不断发展,越来越多的场景需要状态信息能够得以保存;一方面是http本身不会去改变它的这种无状态的特性(至少目前是这样的),另一方面业务场景又迫切的需要保持状态;那么这个时候就需要来“装饰”一下http,引入一些其他机制来实现有状态。
-
cookie和session体系
通过引入cookie和session体系机制来维护状态信息。即用户第一次访问服务器的时候,服务器响应报头通常会出现一个Set-Cookie响应头,这里其实就是在本地设置一个cookie,当用户再次访问服务器的时候,http会附带这个cookie过去,cookie中存有sessionId这样的信息来到服务器这边确认是否属于同一次会话。
Cookie
cookie是由服务器发送给客户端(浏览器)的小量信息,以{key:value}的形式存在。
Cookie机制原理
客户端请求服务器时,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。而客户端浏览器会把Cookie保存起来。当浏览器再请求 服务器时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器通过检查该Cookie来获取用户状态。
我们通过看下servlet-api中Cookie类的定义及属性,来更加具体的了解Cookie。
Cookie在servlet-api中的定义
public class Cookie implements Cloneable, Serializable {
private static final long serialVersionUID = -6454587001725327448L;
private static final String TSPECIALS;
private static final String LSTRING_FILE =
"javax.servlet.http.LocalStrings";
private static ResourceBundle lStrings =
ResourceBundle.getBundle("javax.servlet.http.LocalStrings");
private String name;
private String value;
private String comment;
private String domain;
private int maxAge = -1;
private String path;
private boolean secure;
private int version = 0;
private boolean isHttpOnly = false;
//....省略其他方法
}
Cookie属性
-
name
cookie的名字,Cookie一旦创建,名称便不可更改
-
value
cookie值
-
comment
该Cookie的用处说明。浏览器显示Cookie信息的时候显示该说明
-
domain
可以访问该Cookie的域名。如果设置为“.baidu.com”,则所有以“baidu.com”结尾的域名都可以访问该Cookie;第一个字符必须为“.”
-
maxAge
Cookie失效的时间,单位秒。
- 正数,则超过maxAge秒之后失效。
- 负数,该Cookie为临时Cookie,关闭浏览器即失效,浏览器也不会以任何形式保存该Cookie。
- 为0,表示删除该Cookie。
-
path
该Cookie的使用路径。例如:
- path=/,说明本域名下contextPath都可以访问该Cookie。
- path=/app/,则只有contextPath为“/app”的程序可以访问该Cookie
path设置时,其以“/”结尾.
-
secure
该Cookie是否仅被使用安全协议传输。这里的安全协议包括HTTPS,SSL等。默认为false。
-
version
该Cookie使用的版本号。
- 0 表示遵循Netscape的Cookie规范,目前大多数用的都是这种规范;
- 1 表示遵循W3C的RFC2109规范;规范过于严格,实施起来很难。
在servlet规范中默认是0;
-
isHttpOnly
HttpOnly属性是用来限制非HTTP协议程序接口对客户端Cookie进行访问;也就是说如果想要在客户端取到httponly的Cookie的唯一方法就是使用AJAX,将取Cookie的操作放到服务端,接收客户端发送的ajax请求后将取值结果通过HTTP返回客户端。这样能有效的防止XSS攻击。
上述的这些属性,除了name与value属性会被提交外,其他的属性对于客户端来说都是不可读的,也是不可被提交的。
创建Cookie
Cookie cookie = new Cookie("cookieSessionId","qwertyuiop");
cookie.setDomain(".baidu.com"); // 设置域名
cookie.setPath("/"); // 设置路径
cookie.setMaxAge(Integer.MAX_VALUE); // 设置有效期为永久
response.addCookie(cookie); // 回写到客户端
创建Cookie只能通过上述方式来创建,因为在Cookie类中只提供了这样一个构造函数。
//Cookie的构造函数
public Cookie(String name, String value) {
if (name != null && name.length() != 0) {
//判断下是不是token
//判断是不是和Cookie的属性字段重复
if (this.isToken(name) && !name.equalsIgnoreCase("Comment") &&
!name.equalsIgnoreCase("Discard") &&
!name.equalsIgnoreCase("Domain") &&
!name.equalsIgnoreCase("Expires") &&
!name.equalsIgnoreCase("Max-Age") &&
!name.equalsIgnoreCase("Path") &&
!name.equalsIgnoreCase("Secure") &&
!name.equalsIgnoreCase("Version") && !name.startsWith("$")) {
this.name = name;
this.value = value;
} else {
String errMsg =
lStrings.getString("err.cookie_name_is_token");
Object[] errArgs = new Object[]{name};
errMsg = MessageFormat.format(errMsg, errArgs);
throw new IllegalArgumentException(errMsg);
}
} else {
throw new IllegalArgumentException(lStrings.getString
("err.cookie_name_blank"));
}
}
Cookie更新
在源码中可以知道,Cookie本身并没有提供修改的方法;在实际应用中,一般通过使用相同name的Cookie来覆盖原来的Cookie,以达到更新的目的。
但是这个修改的前提是需要具有相同domain,path的 Set-Cookie 消息头
Cookie cookie = new Cookie("cookieSessionId","new-qwertyuiop");
response.addCookie(cookie);
Cookie删除
与Cookie更新一样,Cookie本身也没有提供删除的方法;但是从前面分析Cookie属性时了解到,删除Cookie可以通过将maxAge设置为0即可。
Cookie cookie = new Cookie("cookieSessionId","new-qwertyuiop");
cookie.setMaxAge(0);
response.addCookie(cookie);
上面的删除是我们自己可控的;但是也存在一些我们不可控或者说无意识情况下的删除操作:
- 如果maxAge是负值,则cookie在浏览器关闭时被删除
- 持久化cookie在到达失效日期时会被删除
- 浏览器中的 cookie 数量达到上限,那么 cookie 会被删除以为新建的 cookie 创建空间。
其实很多情况下,我们关注的都是后者。关于数量上限后面会说到。
从请求中获取Cookie
Cookie[] cookies = request.getCookies();
Cookie同源与跨域
我们知道浏览器的同源策略:
URL由协议、域名、端口和路径组成,如果两个URL的协议、域名和端口相同,则表示他们同源。浏览器的同源策略,限制了来自不同源的"document"或脚本,对当前"document"读取或设置某些属性。
对于Cookie来说,Cookie的同源只关注域名,是忽略协议和端口的。所以一般情况下,https://localhost:80/和http://localhost:8080/的Cookie是共享的。
Cookie是不可跨域的;在没有经过任何处理的情况下,二级域名不同也是不行的。(wenku.baidu.com和baike.baidu.com)。
Cookie数量&大小限制及处理策略
| IE6.0 | IE7.0/8.0 | Opera | FF | Safari | Chrome | |
|---|---|---|---|---|---|---|
| 个数/个 | 20/域 | 50/域 | 30/域 | 50/域 | 无限制 | 53/域 |
| 大小/Byte | 4095 | 4095 | 4096 | 4097 | 4097 | 4097 |
注:数据来自网络,仅供参考
因为浏览器对于Cookie在数量上是有限制的,如果超过了自然会有一些剔除策略。在这篇文章中Browser cookie restrictions提到的剔除策略如下:
The least recently used (LRU) approach automatically kicks out the oldest cookie when the cookie limit has been reached in order to allow the newest cookie some space. Internet Explorer and Opera use this approach.
最近最少使用(LRU)方法:在达到cookie限制时自动地剔除最老的cookie,以便腾出空间给许最新的cookie。Internet Explorer和Opera使用这种方法。
Firefox does something strange: it seems to randomly decide which cookies to keep although the last cookie set is always kept. There doesn’t seem to be any scheme it’s following at all. The takeaway? Don’t go above the cookie limit in Firefox.
Firefox决定随机删除Cookie集中的一个Cookie,并没有什么章法。所以最好不要超过Firefox中的Cookie限制。
超过大小长度的话就是直接被截取丢弃;
Session
Cookie机制弥补了HTTP协议无状态的不足。在Session出现之前,基本上所有的网站都采用Cookie来跟踪会话。
与Cookie不同的是,session是以服务端保存状态的。
session机制原理
当客户端请求创建一个session的时候,服务器会先检查这个客户端的请求里是否已包含了一个session标识 - sessionId,
- 如果已包含这个sessionId,则说明以前已经为此客户端创建过session,服务器就按照sessionId把这个session检索出来使用(如果检索不到,可能会新建一个)
- 如果客户端请求不包含sessionId,则为此客户端创建一个session并且生成一个与此session相关联的sessionId
sessionId的值一般是一个既不会重复,又不容易被仿造的字符串,这个sessionId将被在本次响应中返回给客户端保存。保存sessionId的方式大多情况下用的是cookie。
HttpSession
HttpSession和Cookie一样,都是javax.servlet.http下面的;Cookie是一个类,它描述了Cookie的很多内部细节。而HttpSession是一个接口,它为session的实现提供了一些行为约束。
public interface HttpSession {
/**
* 返回session的创建时间
*/
public long getCreationTime();
/**
* 返回一个sessionId,唯一标识
*/
public String getId();
/**
*返回客户端最后一次发送与该 session 会话相关的请求的时间
*自格林尼治标准时间 1970 年 1 月 1 日午夜算起,以毫秒为单位。
*/
public long getLastAccessedTime();
/**
* 返回当前session所在的ServletContext
*/
public ServletContext getServletContext();
public void setMaxInactiveInterval(int interval);
/**
* 返回 Servlet 容器在客户端访问时保持 session
* 会话打开的最大时间间隔
*/
public int getMaxInactiveInterval();
public HttpSessionContext getSessionContext();
/**
* 返回在该 session会话中具有指定名称的对象,
* 如果没有指定名称的对象,则返回 null。
*/
public Object getAttribute(String name);
public Object getValue(String name);
/**
* 返回 String 对象的枚举,String 对象包含所有绑定到该 session
* 会话的对象的名称。
*/
public Enumeration<String> getAttributeNames();
public String[] getValueNames();
public void setAttribute(String name, Object value);
public void putValue(String name, Object value);
public void removeAttribute(String name);
public void removeValue(String name);
/**
* 指示该 session 会话无效,并解除绑定到它上面的任何对象。
*/
public void invalidate();
/**
* 如果客户端不知道该 session 会话,或者如果客户选择不参入该
* session 会话,则该方法返回 true。
*/
public boolean isNew();
}
创建session
创建session的方式是通过request来创建;
// 1、创建Session对象
HttpSession session = request.getSession();
// 2、创建Session对象
HttpSession session = request.getSession(true);
这两种是一样的;如果session不存在,就新建一个;如果是false的话,标识如果不存在就返回null;
生命周期
session的生命周期指的是从Servlet容器创建session对象到销毁的过程。Servlet容器会依据session对象设置的存活时间,在达到session时间后将session对象销毁。session生成后,只要用户继续访问,服务器就会更新session的最后访问时间,并维护该session。
之前在单进程应用中,session我一般是存在内存中的,不会做持久化操作或者说使用三方的服务来存session信息,如redis。但是在分布式场景下,这种存在本机内存中的方式显然是不适用的,因为session无法共享。这个后面说。
session的有效期
session一般在内存中存放,内存空间本身大小就有一定的局限性,因此session需要采用一种过期删除的机制来确保session信息不会一直累积,来防止内存溢出的发生。
session的超时时间可以通过maxInactiveInterval属性来设置。
如果我们想让session失效的话,也可以当通过调用session的invalidate()来完成。
分布式session
首先是为什么会有这样的概念出现?
先考虑这样一个问题,现在我的应用需要部署在3台机器上。是不是出现这样一种情况,我第一次登陆,请求去了机器1,然后再机器1上创建了一个session;但是我第二次访问时,请求被路由到机器2了,但是机器2上并没有我的session信息,所以得重新登录。当然这种可以通过nginx的IP HASH负载策略来解决。对于同一个IP请求都会去同一个机器。
但是业务发展的越来越大,拆分的越来越多,机器数不断增加;很显然那种方案就不行了。那么这个时候就需要考虑是不是应该将session信息放在一个独立的机器上,所以分布式session要解决的问题其实就是分布式环境下的session共享的问题。
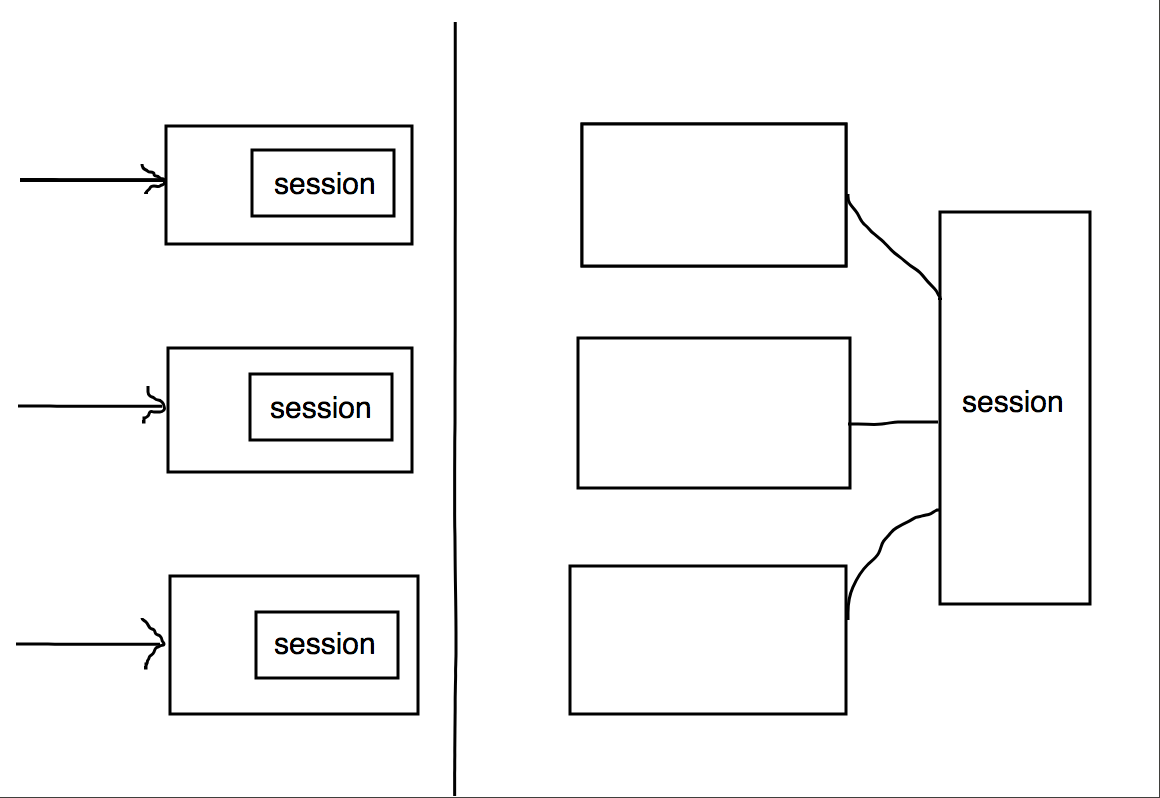
上图中的关于session独立部署的方式有很多种,可以是一个独立的数据库服务,也可以是一个缓存服务(redis,目前比较常用的一种方式,即使用Redis来作为session缓存服务器)。
参考
- https://www.cnblogs.com/icelin/p/3974935.html
- https://www.nczonline.net/blog/2008/05/17/browser-cookie-restrictions/
- https://zh.wikipedia.org/wiki/%E8%B6%85%E6%96%87%E6%9C%AC%E4%BC%A0%E8%BE%93%E5%8D%8F%E8%AE%AE
