

推荐阅读时间:10min~12min
主题:如何构建真实世界可用的ML模型
Python 作为当前机器学习中使用最多的一门编程语言,有很多对应的机器学习库,最常用的莫过于 scikit-learn 了。我们介绍下如何使用sklearn进行实时预测。先来看下典型的机器学习工作流。
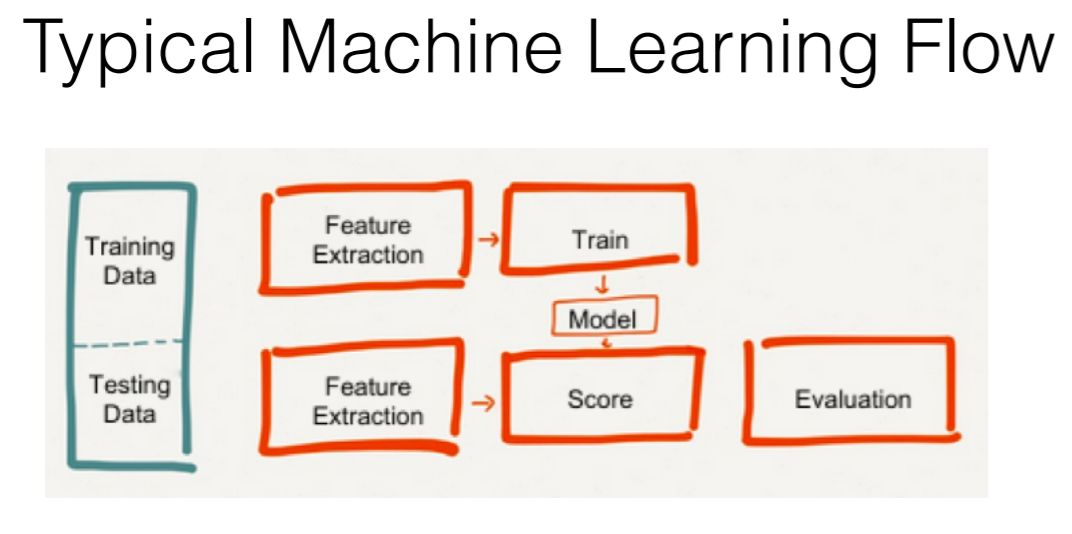
解释下上面的这张图片:
-
绿色方框圈出来的表示将数据切分为训练集和测试集。
-
红色方框的上半部分表示对训练数据进行特征处理,然后再对处理后的数据进行训练,生成 model。
-
红色方框的下半部分表示对测试数据进行特征处理,然后使用训练得到的 model 进行预测。
-
红色方框的右下角部分表示对模型进行评估,评估可以分为离线和在线。
典型的 ML 模型
介绍完了典型的机器学习工作流了之后,来看下典型的 ML 模型。
import numpy as npimport pandas as pdfrom sklearn.datasets import load_irisfrom sklearn.ensemble import RandomForestClassifier# 加载鸢尾花数据iris = load_iris()# 创建包含特征名称的 DataFramedf = pd.DataFrame(iris.data, columns=iris.feature_names)df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)# 生成标记,切分训练集、测试集df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75train, test = df[df['is_train']==True], df[df['is_train']==False]# 生成 X 和 yfeatures = df.columns[:4]y = pd.factorize(train['species'])[0]model = RandomForestClassifier(n_jobs=2)# 训练模型model.fit(train[features], y)# 预测数据model.predict(test[features])上面的模型对鸢尾花数据进行训练生成一个模型,之后该模型对测试数据进行预测,预测结果为每条数据属于哪种类别。
模型的保存和加载
上面我们已经训练生成了模型,但是如果我们程序关闭后,保存在内存中的模型对象也会随之消失,也就是说下次如果我们想要使用模型预测时,需要重新进行训练,如何解决这个问题呢?
很简单,既然内存中的对象会随着程序的关闭而消失,我们能不能将训练好的模型保存成文件,如果需要预测的话,直接从文件中加载生成模型呢?答案是可以的。
sklearn 提供了 joblib 模型,能够实现完成模型的保存和加载。
from sklearn.externals import joblib# 保存模型到 model.joblib 文件joblib.dump(model, "model.joblib" ,compress=1)# 加载模型文件,生成模型对象new_model = joblib.load("model.joblib")new_pred_data = [[0.5, 0.4, 0.7, 0.1]]# 使用加载生成的模型预测新样本new_model.predict(new_pred_data)构建实时预测
前面说到的运行方式是在离线环境中运行,在真实世界中,我们很多时候需要在线实时预测,一种解决方案是将模型服务化,在我们这个场景就是,我告诉你一个鸢尾花的 sepal_length, sepal_width, petal_length, petal_width 之后,你能够快速告诉我这个鸢尾花的类型,借助 flask 等 web 框架,开发一个 web service,实现实时预测。
因为依赖于 flask 框架,没有安装的需要安装下:
pip install flask创建一个 ml_web.py 文件,内容如下:
# coding=utf-8from urlparse import urljoinimport flaskfrom flask import Flask, request, url_for, Responsefrom sklearn.externals import joblibapp = Flask(__name__)# 加载模型model = joblib.load("model.joblib")@app.route("/", methods=["GET"])def index(): with app.test_request_context(): # 生成每个函数监听的url以及该url的参数 result = {"predict_iris": {"url": url_for("predict_iris"), "params": ["sepal_length", "sepal_width", "petal_length", "petal_width"]}} result_body = flask.json.dumps(result) return Response(result_body, mimetype="application/json")@app.route("/ml/predict_iris", methods=["GET"])def predict_iris(): request_args = request.args # 如果没有传入参数,返回提示信息 if not request_args: result = { "message": "请输入参数:sepal_length, sepal_width, petal_length, petal_width" } result_body = flask.json.dumps(result, ensure_ascii=False) return Response(result_body, mimetype="application/json") # 获取请求参数 sepal_length = float(request_args.get("sepal_length", "-1")) sepal_width = float(request_args.get("sepal_width", "-1")) petal_length = float(request_args.get("petal_length", "-1")) petal_width = float(request_args.get("petal_width", -1)) # 构建特征矩阵 vec = [[sepal_length, sepal_width, petal_length, petal_width]] print("vec: {0}".format(vec)) # 生成预测结果 predict_result = int(model.predict(vec)[0]) print("predict_result: {0}".format(predict_result)) # 构造返回数据 result = { "features": { "sepal_length": sepal_length, "sepal_width": sepal_width, "petal_length": petal_length, "petal_width": petal_width }, "result": predict_result } result_body = flask.json.dumps(result, ensure_ascii=False) return Response(result_body, mimetype="application/json")if __name__ == "__main__": app.run(port=8000)在命令行启动它:
$ python ml_web.py * Running on http://127.0.0.1:8000/ (Press CTRL+C to quit)在 PostMan(也可以在浏览器中打开) 中打开 http://127.0.0.1:8000/ml/predict_iris ,得到以下结果:
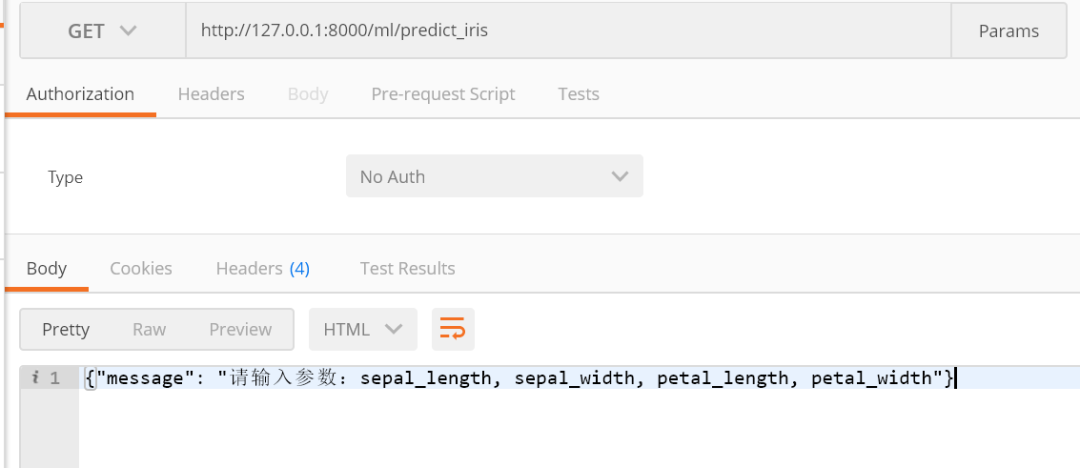
可以看到,这里提示我们输入 sepal_length, sepal_width, petal_length, petal_width 参数,所以我们需要添加上参数重新构造一个请求 url:http://127.0.0.1:8000/ml/predict_iris?sepal_length=10&sepal_width=1&petal_length=3&petal_width=2
再次请求得到的结果如下:
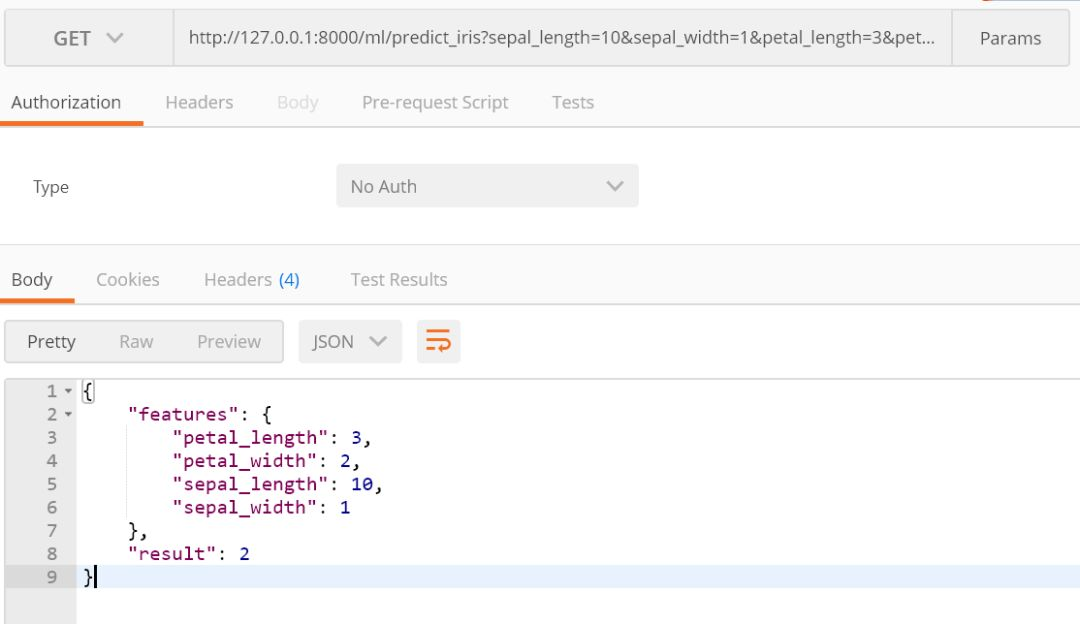
可以看到,模型返回的结果为 2,也就是说模型认为这个鸢尾花的类别是 2。
总结
在真实世界中,我们经常需要将模型进行服务化,这里我们借助 flask 框架,将 sklearn 训练后生成的模型文件加载到内存中,针对每次请求传入不同的特征来实时返回不同的预测结果。


往期精彩回顾

吴恩达|机器学习秘籍(Machine Learning Yearning)
脑洞科技栈 专注于人工智能领域作者:1or0,脑洞大开(www.naodongopen.com)签约作者,专注于机器学习研究。
 长按,识别二维码,加关注
回复关键字可获取大量学习资料!
长按,识别二维码,加关注
回复关键字可获取大量学习资料!
更多精彩内容,请点击“阅读原文”
 戳这里戳这里~
戳这里戳这里~
