

复盘日常问题板的时候,看到了曾经听到后端同学讨论的回源的问题。一直以来对 cdn 相关的知识一知半解,借此机会彻底梳理一下。
文章目录:
- 访问 cdn 资源和不通过 cdn 访问的过程有什么不同
- 回源是什么意思?
- 除了静态资源,API 是否可以缓存?
- 资源的过期如何判定?cdn 是如何更新数据的?
- 几个专业术语
访问 cdn 资源和不通过 cdn 访问的过程有什么不同
一般的过程我们都知道了,不再赘述。下面我们来看看访问 cdn 的过程。
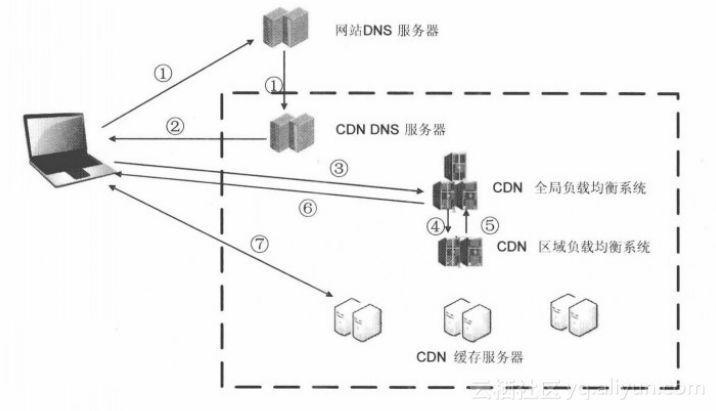
简单来说,其实 cdn 就是个放服务端资源的一个仓库。康师傅的泡面如果不是有家门口的小卖部,我们就得去人家的工厂门口拿。有了小卖部,我们只需要去一个卖康师傅&&有货的小卖部拿,就是这个道理。
其中有一个比较重要的点,在过程1里:这个过程中,有一个 CNAME 的过程,我们访问 cdn 资源的地址一般是 a.cloud.com 或者类似的地址,是一个公司的访问 cdn 的专用地址。但是我们用的 cdn 的服务却是第三方的,即其实资源在他们的地址上比如 tencent.cdn。这时候就需要在 dns 查询的时候,需要把我们访问 a.cloud.com的地址映射到 tencent.cdn 的地址上,然后拿着映射后的地址再去走一遍 dns 解析,成功之后才获取到第三方提供的全局负载均衡系统的 IP。再继续走后面的流程。
回源是什么意思?
当 cdn 缓存服务器中没有符合客户端要求的资源的时候,缓存服务器会请求上一级缓存服务器,以此类推,直到获取到。最后如果还是没有,就会回到我们自己的服务器去获取资源。 那都有哪些时候会回源呢?没有资源,资源过期,访问的资源是不缓存资源等都会导致回源。其他情况欢迎小伙伴们在评论区补充~
除了静态资源,API 是否可以缓存?
注意题目所描述的情况不是 cdn 的动态加速。
动态加速的对象是动态生成的网页,动态加速一般是对针对内容(如数据库信息等)在用户与- 源站之间建立高速通道,通过路由优化、TCP加速等技术手段对动态内容进行加速,降低节点到源站之间的时延,从而大大降低了用户访问动态网页的延迟。
其实这个问题我没有找到比较合适的解答,下面我想说一下我个人的见解。 我们使用 cdn 的原因是,我们经常有一些比较频繁请求且容量比较大的文件,并且更新频率不那么高的文件。这些文件如果我们都放在自己的服务器上,于客户端问题在于访问时间长,于服务器端是占用服务器端的资源。所以我们采用分布式的方式扔在 cdn 上。但是 API 不同,首先他常更新,其次他多和用户信息等相关联,并且 cdn 判断是否缓存是依靠 url,意味着他只能缓存 get 请求,所以他的应用范围是有限的。并且 api 常更新,推送更新到所有 cdn 节点同样是需要耗费资源的。所以 API 是不适合放在 cdn 上的。但是如果你的内容是相对静态的,不涉及和用户信息关联,并且能在一段时间内容忍缓存,更新不频繁,那么也不是不能考虑。
资源的过期如何判定?cdn 是如何更新数据的?
资源过期时间就是根据我们老生常谈的请求头部来判定。这个后面会单拎出一篇文章带大家复习一下。 那么 cdn 是如何更新数据的?分两种,主动(PUSH)和被动(PULL)。被动刚才我们已经提到过了,利用回源就可以被动在途经的 cdn 节点缓存数据。 而主动指的是,我们从服务器主动往 cdn 推送数据。
几个专业术语
边缘节点:指距离最终用户接入具有较少的中间环节的网络节点
参考文献: CDN 学习中的一点小思考 CDN 命中率、回源率常见问题 CDN缓存那些事 让 API 也上 CDN 吧 CDN的基本工作过程 CDN是什么?使用CDN有什么优势? cname记录是什么?他存在的意义是什么? CDN工作原理(CNAME) 【CDN 最佳实践】CDN缓存策略解读和配置策略 CDN缓存那些事儿
