

文: 孙成
本文原创,转载请注明作者及出处
我所在的公共业务团队为沪江提供底层业务服务,为了保证系统有能力抗住高并发大流量的压力,我们保证包括数据库在内的系统各个节点的性能,而了解实现原理则会让优化更加精准有效。沪江在去年完成了主要系统的去 Windows 化,数据库也从 SQL Server 切换到了 MySQL 。作为一款被业界广泛使用的数据库,MySQL 早已是当今世界上最流行的关系型数据库之一,但是对于曾经比较熟悉微软生态的开发人员来说,可能更加熟悉 SQL Server。虽然 MySQL 和 SQL Server 使用起来很相似,但是具体实现细节上它们仍然有很大的差异。下面我将分享 MySQL InnoDB 存储引擎中关于一致性读的相关实现原理。
一致性读(consistend read)
InnoDB 中的一致性读(consistend read)指的是利用多版本查询数据库在某个时间点的快照。此查询可以看到该时间点之前提交的事务所做的更改并且不会被之后的修改或者未提交事务所影响。但是对于同一事务中的较早语句的修改则不适用此规则,这种情况会产生以下异常:如果你更新表中的某些行,一次 SELECT 可能看到更新行的最新版本也可能看到任一行的旧版本;如果其它会话同时更新到同一个表,则可能会看到该表处于数据库中从未存在过的状态。
-
当事务隔离级别为 REPEATABLE READ 时,同一个事务中的一致性读都是读取的是该事务下第一次查询所建立的快照。
-
当事务隔离级别为 READ COMMITTED 时,同一事务下的一致性读都会建立和读取此查询自己的最新的快照。
一致性读是 InnoDB 在 REPEATABLE READ 和 READ COMMITTED 事务隔离中处理 SELECT 语句的默认模式。一致性读不会在表上设置任何锁,所以其它会话可以对表进行读写操作。
数据库状态的快照适用于事务中的 SELECT 语句,而不一定适用于 DML 语句。如果执行 INSERT 或者 UPDATE某些行然后提交该事务,则从另一个并发 REPEATABLE READ 事务发出的 DELETE 或 UPDATE 语句则会影响那些刚刚提交的数据行。
下面这个示例展示了这种场景:
Session A Session B
begin; begin;
-------------------------------------------------------------------------------------
SELECT * FROM t; SELECT * FROM t;
> empty set > empty set
-------------------------------------------------------------------------------------
INSERT INTO t (id) VALUES (1);
> 1 row affected
SELECT * FROM t;
-----------
| id |
-----------
| 1 |
-----------
-------------------------------------------------------------------------------------
SELECT * FROM t;
> empty set
-------------------------------------------------------------------------------------
COMMIT;
-------------------------------------------------------------------------------------
SELECT * FROM t;
> empty set
-------------------------------------------------------------------------------------
DELETE FROM t WAERE id = 1;
> 1 row affected
-------------------------------------------------------------------------------------
SELECT * FROM t;
-----------
| id |
-----------
| 1 |
-----------
-------------------------------------------------------------------------------------
COMMIT;
-------------------------------------------------------------------------------------
SELECT * FROM t;
> empty set
-------------------------------------------------------------------------------------
SELECT * FROM t;
-----------
| id |
-----------
| 1 |
-----------
-------------------------------------------------------------------------------------
一致的读取不适用于某些 DDL语句,如:
1) 一致性读不适用于 DROP TABLE ,因为表已经被 InnoDB 销毁了。 2) 一致性读不适用于 ALTER TABLE ,因为 ALTER TABLE 实际是生成一张原始表的临时表,并在构建完成后删除原始表。 在事务中进行一致的读取时,新表中的行不可见,这种情况下事务会返回 ERTABLEDEF_CHANGED 错误(表定义已更改,请重试事务)。
在没有指定 FOR UPDATE 或者 LOCK IN SHARE MODE 的情况下 INSERT INTO ... SELECT ,UPDATE ...(SELECT)和 CREATE TABLE... 等语句中的的读取会有以下差异:
-
默认情况下,就像 READ COMMITTED 一样,即使在同一事务中,每个一致性读都会建立和读取自己的快照。
-
如果将 innodblocksunsafe forbinlog 设置为了 enable 并且事务隔离级别不是 SERIALIZABLE,则读操作不会再行上加锁。
多版本并发控制
上面说的一致性读(consistend read)的主要是基于MVCC实现,而 MySQL 中大多数事务型(如:InnoDB、Falcon 等)存储引擎都同时实现了 MVCC(Multi-Version Concurrency Control) 。
当前不仅仅是 MySQL,其它数据库系统(如:Oracle、PostgreSQL)也都实现了 MVCC。值得注意的是 MVCC 并没有一个统一的实现标准,所以不同的数据库,不同的存储引擎的实现都不尽相同。
多版本控制的核心是数据快照,而 InnoDB 则是通过 undo log 来存储数据快照。
下面展示了在不考虑 redo log 的情况下利用 undo log工作的简化过程:
| 序号 | 动作 |
|---|---|
| 1 | 开始事务 |
| 2 | 记录数据行数据快照到undo log |
| 3 | 更新数据 |
| 4 | 将undo log写到磁盘 |
| 5 | 将数据写到磁盘 |
| 6 | 提交事务 |
1)为了保证数据的持久性数据要在事务提交之前持久化。 2)undo log的持久化必须在在数据持久化之前,这样才能保证系统崩溃时,可以用undo log来回滚事务。
Innodb中的隐藏列
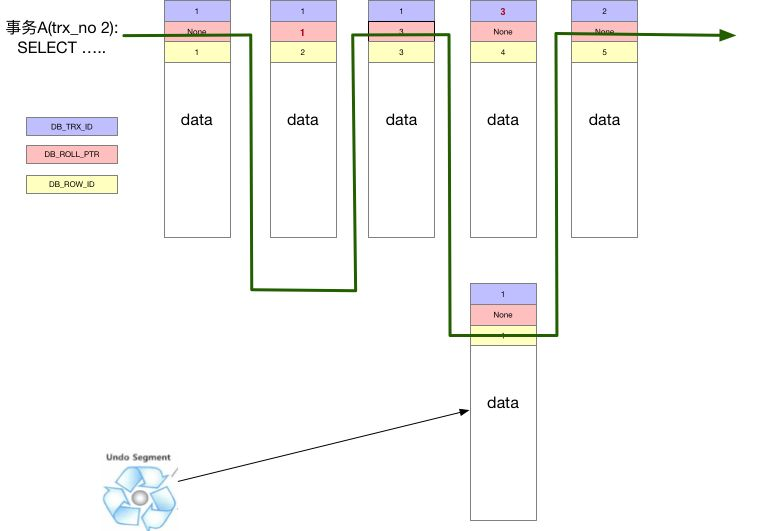
InnoDB 通过 undo log 保存了已更改行的旧版本的信息的快照。InnoDB 的内部实现中为每一行数据增加了三个隐藏列用于实现 MVCC 。
| 列名 | 长度(字节) | 作用 |
|---|---|---|
| DBTRXID | 6 | 插入或更新行的最后一个事务的事务标识符。(删除视为更新,将其标记为已删除) |
| DBROLLPTR | 7 | 写入回滚段的撤消日志记录(若行已更新,则撤消日志记录包含在更新行之前重建行内容所需的信息) |
| DBROWID | 6 | 行标识(隐藏单调自增id) |
MVCC 只在 READ COMMITED 和 REPEATABLE READ 两个隔离级别下工作。READ UNCOMMITTED 总是读取最新的数据行,而不是符合当前事务版本的数据行。而 SERIALIZABLE 则会对所有读取的行都加锁。
SELECT
InnoDB 会根据两个条件来检查每行记录:
1) InnoDB 只查找版本(DBTRXID)早于当前事务版本的数据行(行的系统版本号 <= 事务的系统版本号,这样可以确保数据行要么是在开始之前已经存在了,要么是事务自身插入或修改过的)。 2) 行的删除版本号(DBROLLPTR)要么未定义(未更新过),要么大于当前事务版本号(在当前事务开始之后更新的)。这样可以确保事务读取到的行,在事务开始之前未被删除。
INSERT
InnoDB 为新插入的每一行保存当前系统版本号作为行版本号。
DELETE
InnoDB 为删除的每一行保存当前的系统版本号作为行删除标识。
UPDATE
InnoDB 为插入一行新记录,保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为行删除标识。
Undo log
在 InnoDB 存储引擎中,它的主要作用除了实现 MVCC 和数据回滚,undo log 是一种逻辑日志,它只是将数据库 逻辑 地回滚到原来的样子,所有的修改都被 逻辑地取消,但是数据结构和数据页本身在回滚之后与之前可能已经发生的变化,这样做的目的是因为数据库可能会同时存在多个并发事务,他们可能同时修改一个页上的其它数据行,如果因为一个事务的回滚而将数据页回滚到该事务开始时的状态,则会影响其它正在执行的事务。
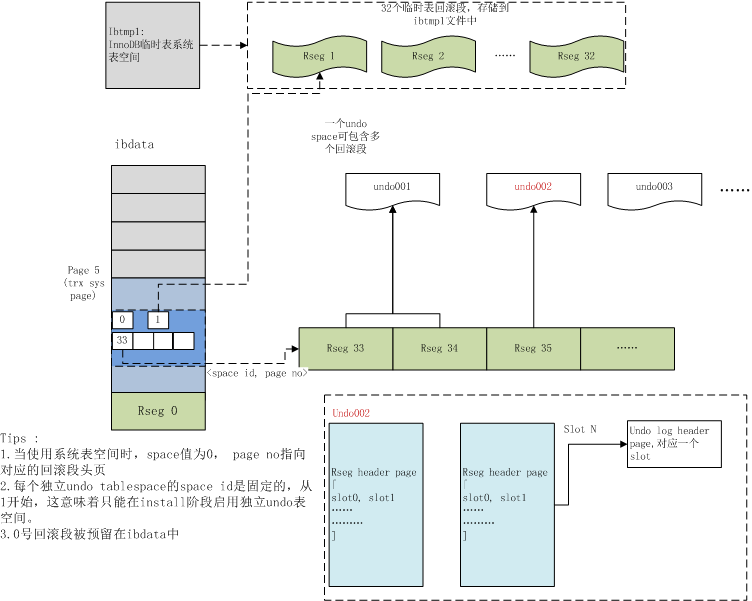
undo log 存在于 undo log segments 中,undo log segments 位在于 rollback segments 中,而 rollback segments 则可能存在于系统系统表空间(system tablespace)、临时表空间( temporary tablespace)、撤销表空间(undo tablespaces)中。
回滚段(rollback segment)
| 属性 | 值 |
|---|---|
| 命令行格式 | --innodb-rollback-segments=# |
| 系统变量 | innodbrollbacksegments |
| 范围 | 全局 |
| 动态配置 | 是 |
| 数据类型 | Integer |
| 默认值 | 128(最大值) |
| 最小值 | 1 |
| 最大值 | 128 |
InnoDB 最多支持 128 个回滚段,每个回滚段最多可以支持1023个数据修改事务,回滚段最多可以设置128。
mysql> show variables like 'innodb_rollback_segments';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_rollback_segments | 128 |
+--------------------------+-------+
具体的分配策略如下:
-
必然有一个回滚段是被分配到系统表空间中的
-
当 innodbrollbacksegments 的值小于等于32时, InnoDB 会将一个回滚段分配给系统表空间,将32个回滚段分配给临时表空间。
-
当 innodbrollbacksegments 的值大于32时, InnoDB 会将一个回滚段分配给系统表空间,将32个回滚段分配给临时表空间,并将剩下的回滚段分配给 撤销表空间 ,如果不存在撤销表空间则,则会将剩下的回滚段分配给系统表空间(5.7默认)。
撤销表空间在 5.7.21 版本之后被标记为 弃用 未来可能被删除,目前(MySQL5.7 )innodbundo_tablespaces默认值为 0 即不启用。
事务提交
根据行为的不同 undo log 分为两种 insert undo log / update undo log。
insert undo log 是在 insert 操作中产生的 undo log。因为 insert 操作的记录只对事务本身可见,对于其它事务此记录是不可见的,所以 insert undo log 可以在事务提交后直接删除而不需要进行 purge 操作。
update undo log 是 update 或 delete 操作中产生的 undo log,因为会对已经存在的记录产生影响,为了提供 MVCC机制,因此 update undo log 不能在事务提交时就进行删除,而是将事务提交时放到入 history list 上,等待 purge 线程进行最后的删除操作。
当事务 commit 时,需要将事务状态设置为 COMMIT 状态,并将事务包含的 Undo 都设置为完成状态
-
如果当前 undo log 只占一个 page,且占用的 header page 大小不足其 3/4 时,将其加入到 undo cache list上,以便分配给下个事务使用,并将状态设置为 TRXUNDOCACHED
-
如果当前 undo log 是 insertundo ,则状态设置为 TRXUNDOTOFREE
-
如果不满足1和2,则表明该undo可能需要 purge 线程去执行清理操作,状态设置为 TRXUNDOTO_PURG。
MySQL 5.7 对临时表 undo 和普通表 undo 分别做了处理,前者在写 undo 日志时总是不需要记录 redo,后者则需要记录。
清理
delete和update 操作可能并不会直接删除原有数据,delete 操作只是将聚集索引列的 delete flag 置为 1 ,记录仍然存在于 B+ 树中,最终的删除在 purge 线程中完成(这样的设计是因为其它事务可能引用这行,所以不能立刻删除)。
值得注意的是 innodb 对于 update 的处理其实是分两步处理的: 1.将原聚集索引记录标记为已经删除 。 2.插入一条新记录,所以 purge 操作只需要针对 delete flag 为1的记录即可。
history list
history list 根据事务提交的顺序将 undo log 进行链接,先提交的事务总是在 history list 的尾部,同一 undo page 中的 undo log 也总是按照顺序排列的。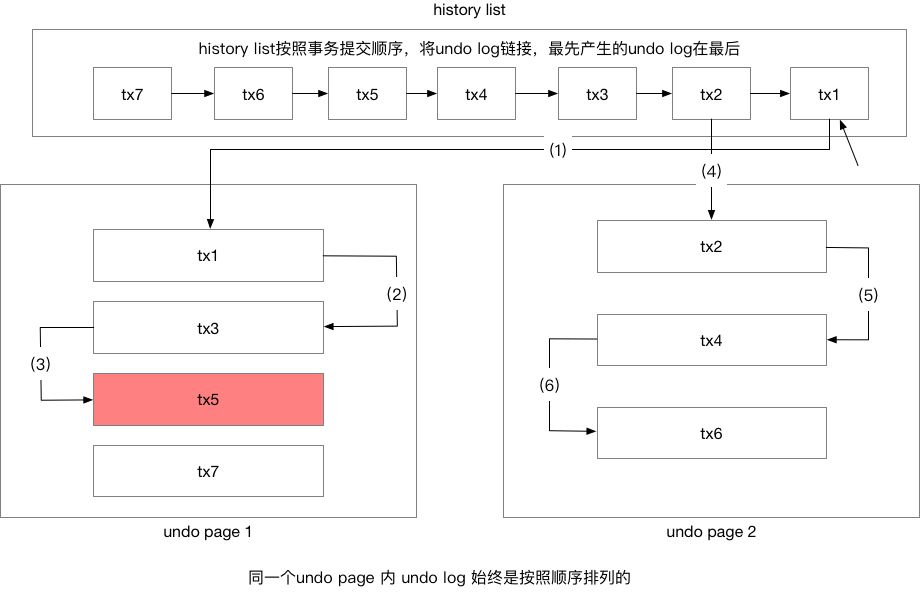
具体清理过程为 innoDB 会默认从 history list 中找到第一个需要被清理的数据tx1,清理成功之后清理线程会继续在 tx1 所在页中 继续查找需要被清理的 __undo log (即 tx3,注意这里并不会从 history list 继续查找tx2),之后继续向后查找,找到 tx5,此时发现 tx5 被其它事务引用不能清理(trx no 比当前 purge 到的位置更大),所以再次去 history list 中查找尾部记录,此时为tx2 重复以上步骤。
简单来说 InnoDB 的一致性读主要依赖 MVCC 实现,而 MVCC 的核心则是依赖 undo log 来保存事务快照,使得 InnoDB 在不使用锁的前提下依然能保证事务中数据的一致性,减少了锁的开销,大大提高了查询性能。
参考文档:
-
MySQL 5.7 Reference Manual:
https://dev.mysql.com/doc/refman/5.7/en/
-
MySQL · 引擎特性 · InnoDB undo log 漫游:
http://mysql.taobao.org/monthly/2015/04/01/
-
《高性能Mysql》(第三版)
-
《Myql技术内幕-Innodb存储引擎》
推荐阅读
从 SQL Server 到 MySQL (一):异构数据库迁移


