

摘要:深度学习是一个既可以处理特征、学习特征又可以实现最后的排序打分的一套整体解决方案,借助深度学习的解决方案,搜索推荐的工作方式将发生巨大的变化。想知道阿里巴巴如何将在搜索推荐领域下应用深度学习技术的吗?想知道手淘和优酷搜索结果的个性化又是如何实现的吗?本文不容错过!
本节视频地址:click.aliyun.com/m/48161/
演讲嘉宾简介:
孙修宇(花名:翎翀),阿里巴巴机器智能技术实验室算法专家,工学硕士,2014年加入阿里巴巴,一直从事深度学习基础技术研究以及在各个行业的应用。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本文主要围绕以下几个方面进行分享:
- 为什么使用深度学习技术
- 手淘主搜索场景
- 手淘详情页推荐场景
- 优酷搜索场景
在本文中,首先将分享阿里巴巴为什么在搜索推荐里使用深度学习技术,并将以3个场景为例介绍深度学习相关的技术是如何被应用到搜索和推荐的场景里面的,这里所选取的3个场景分别是手淘主搜索场景、手淘详情页推荐场景以及优酷搜索场景,这些都是比较具有代表性的场景。
一、为什么使用深度学习技术
阿里巴巴为什么在搜索推荐里采用深度学习技术呢?正如大家所知,传统的搜索推荐任务相当于要针对商品、用户以及一些如检索词等的其他背景信息进行特征工程,其中包括了统计类的特征、ID类的特征以及各种各样其他的人工交叉类的特征等。之后将这些人工设计好的特征输入到一个像LR或者XGBOOST等的机器学习的工具中去,通过人工设计特征、点击或者用户行为的日志,再加上机器学习的工具三者结合起来,可以获得一个针对搜索或者推荐的特定领域的排序模型。

在具备了深度学习的解决方案之后,整体的工作方式就会发生改变。正如大家所了解到的,深度学习这套方案最早是应用于图像领域的,这套方案一个很大的优点就是可以直接学习出来一些人工设计的特征,或者可以根据之前的样本学习出其认为更加有价值的特征,这个特征可以代替人工设计的特征,这也就是深度学习所具有的特征抽取能力。同时,在分类的时候,深度学习的拟合能力也非常强,其拟合能力比XGBOOST、DBDT以及LR等方案更加优秀,所以深度学习是一个既可以处理特征、学习特征又可以实现最后的排序打分的一套整体的解决方案,以上这些也是阿里巴巴在搜索推荐里采用深度学习方案的原因。
二、赋能电商-手淘主搜索场景
在手机淘宝(以下简称手淘)的主搜索场景下,设计了一套End2End的训练框架,针对最原始的行为数据,比如点击、购买以及用户的历史行为自动地学习特征,并使得模型最终可以对于用户、商品以及检索词更好地进行描述,从而提升最终业务指标(GMV)。

模型结构
如下图所示的是手淘中设计好的模型结构。在模型中将检索里面的各种信息分成了3个主要的领域:用户表达域、商品表达域以及检索词表达域。与传统方案不同的是在这个模型中并没有采用一些统计类的特征,而只是使用了用户、商品以及检索词这样ID类的特征,就像传统One-Hot的表达方式。这里的ID类特征覆盖了1亿多商品、2亿多用户以及5百多万个常用的query。
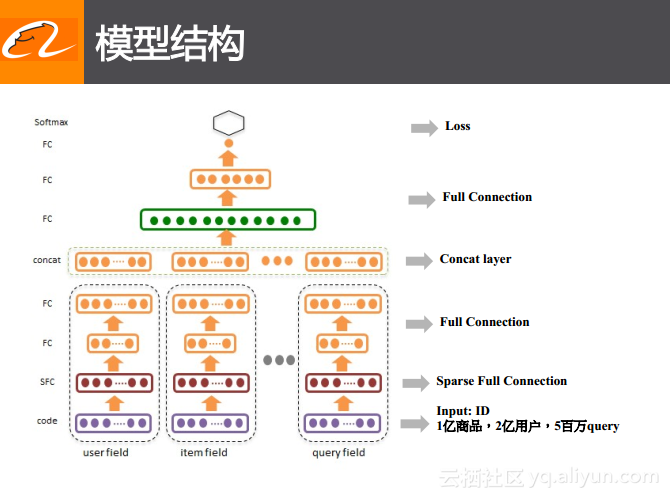
上图中虚线框表示的是embedding的过程,不同域下的信息通过一个三层的全连接网络会被embedding到一个低维的连续空间里面去,这里有所不同的就是第一层并不是全连接层,而是稀疏的全连接层,这样的设计更多地考虑到了计算的效率。三个领域内的ID都被映射到一个低维空间后,采用一个Concat层将这些信息整合到一起,之后又经过一个三层的全连接网络,而最终的学习目标就是前面所提到的点击、转化以及购买等行为。通过这样的模型结构就可以End2End地去获得搜索中排序的解决方案。
商品编码
前面也提到过最初手淘采用的是One-Hot的特征表达来表示商品、用户以及检索词,这样的方式会存在商品以及用户的维度特别高的问题,相当于维度会多于1亿,对于如此之高的维度直接使用One-Hot来进行表达就会占用大量的资源,所以手淘在主搜索里面就采用了随机编码的方式将N维的One-Hot的表达降低成N/20维这样更低维度的编码表达。
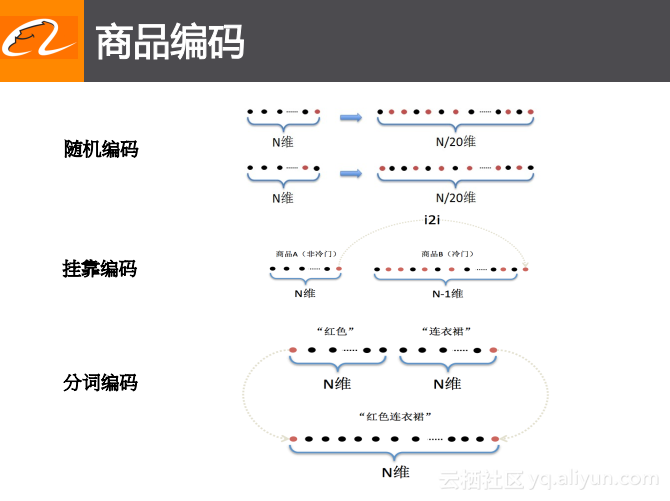
这里所采用的非常简单但是非常有效的方法就是做一个映射,可以假设N维的One-Hot的表达中的6个红色的点就表达6个唯一的值,而黑色的点表示为0值,用这6个不同的点来表达左侧的第一位,而下面的这个对应的One-Hot对应的是右边6个红色点的表达。这里做了一个限制,限制的原则就是不同的表达之间的重复的位最多只能达到3个,通过这样的限制方法就强行地将One-Hot映射到了一个低维的空间中去。这样既能保证多个点来表达编码,也保证点与点之间或者不同表达之间的差异性足够大,从而实现对于One-Hot编码进行压缩。而挂靠编码和分词编码则是在此基础之上的两种改进方式,比如挂靠编码就是对于一些热门商品而言,其行为是比较丰富的,这个时候就认为热门商品有自己唯一的表达,而对于冷门的商品而言,则认为其行为会比较稀疏,可以使用一些类似于哈希的方法将被认为可能会存在关系的商品用相近的方式进行表达。分词编码与挂靠编码的意思类似,只不过在前面的随机编码方式的基础之上引入了一些人工设计出来的编码方式,比如对于query中的“红色”以及“连衣裙”都会有一个特别的表达,而对于分不清的部分则可以使用一个特别的编码进行表达。
稀疏编码层
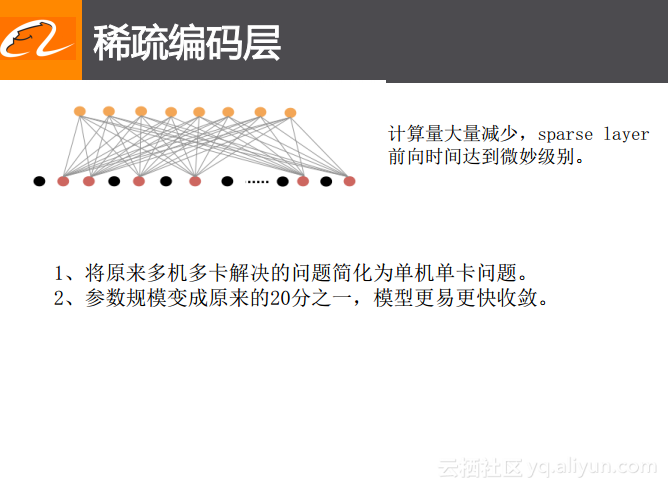
正如前面所提到的,稀疏编码层的具体实现就是稀疏的全连接层。其主要的目的就是减少计算量。一方面可以将原本稠密的矩阵乘法改成了稀疏的矩阵乘法,计算量会大大降低,计算效率也将大大提升,与此同时还解决了内存的使用问题,将原本可能需要多机多卡才能解决的问题简化成为单机单卡就可以解决的问题,提升了训练的效率。
多任务学习
在手淘搜索推荐中采用了多任务学习的方法来学习最终排序的分数。
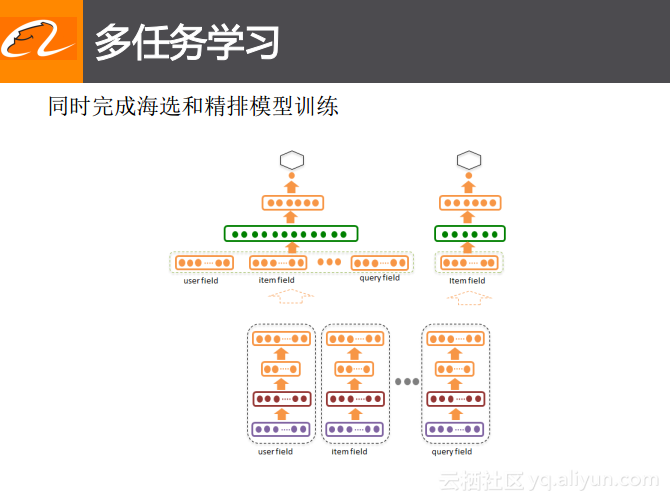
在传统的检索排序里面的实现方案通常分为两到三步,第一步一般是一个召回的过程,也就是根据检索词选取出来与当前检索词相关的商品的信息,将这些与检索词相关的商品做成候选商品池,在这些池中再一层一层地实现。首先,需要根据商品本身的一些历史统计信息或者打分等其他信息对于池中的商品再进行一次排序,之后进一步取出商品的信息。这样就会实现数据量从上亿到百万量级,再到万量级的转变过程。最后还会进行精排的过程,此时为了更好地提升转化率会将用户的个性化信息加入进来构成排序模型。这里将商品数据量从百万到万的级别叫做海选,这部分可能只是与商品相关的,把这部分的训练以及后面排序的训练同时去做,这就相当于一方面在训练用户自己表达的同时对于商品进行打分,学习出商品的好坏的表达方式。通过这两个任务的学习同时获得了两个分数,即海选部分的分数以及精排部分的分数,通过排序这两个部分的同时作用将会更好地增加排序所得结果的多样性,进而通过多样性来提升最终转化的目标。
多模态和在线学习
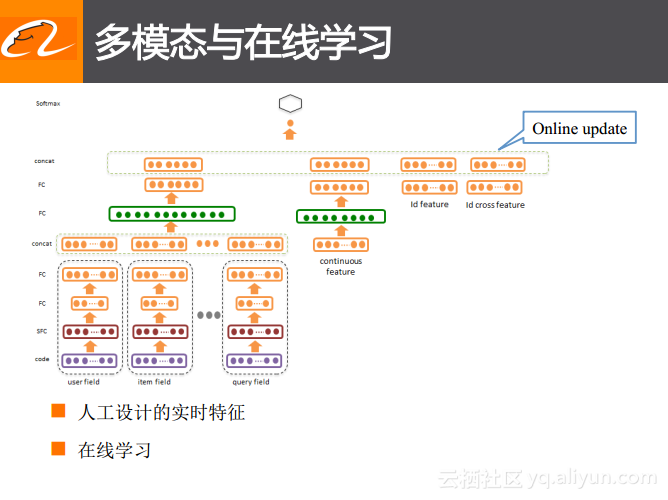
在实现手淘主搜索场景业务的同时还引入了多模态和在线学习,这两个技术更多地是为了应对淘宝的大促场景。众所周知,“双11”就是一个非常典型的大促场景,用户在那天的行为非常丰富,不同的推销或者促销的商品以及行为也都是多种多样的,这时候淘宝所采用的方案就是使用深度学习的技术将用户、商品以及检索词等之间长期稳定的关系学习出来,同时再引入一些连续类的特征以及ID类或者交叉类这些传统的人工设计的特征,此外还引入一些商品的实时表达的特征,将这两部分特征融合到一起,之后通过在线学习的机制来学习最后的三层全连接,或者只去学习最后一层的LR来实现既可以考虑到商品以及用户稳定的偏好,也能够同时考虑到用户在当时的大促场景下的偏好的结果。通过深度学习所获得的特征与人工设计的特征这两部分的融合,淘宝的推荐在“双11”等大促场景中取得了非常不错的效果提升。
三、赋能电商-详情页看了又看
前面为大家分享了在搜索领域下常用的深度学习技术以及所获得的效果提升,接下来为大家分享推荐的场景。推荐场景与搜索场景既有相似之处,也有不同之处。在搜索场景下,候选商品是与当前的检索词相关的,而在推荐场景下,则需要猜测哪些商品会与用户之前的历史行为相关,比如在下图所展示的详情页的场景下,所推荐的商品也会是与其详情页相关的,比如在召回的过程中对于候选的商品究竟应该如何选择,在搜索和推荐场景下会具有一定差异性,并且在最后的排序过程中,搜索和推荐场景下所完成的任务则是比较类似的,这也是认为可以使用一套类似的方案来解决两个场景的问题的原因。
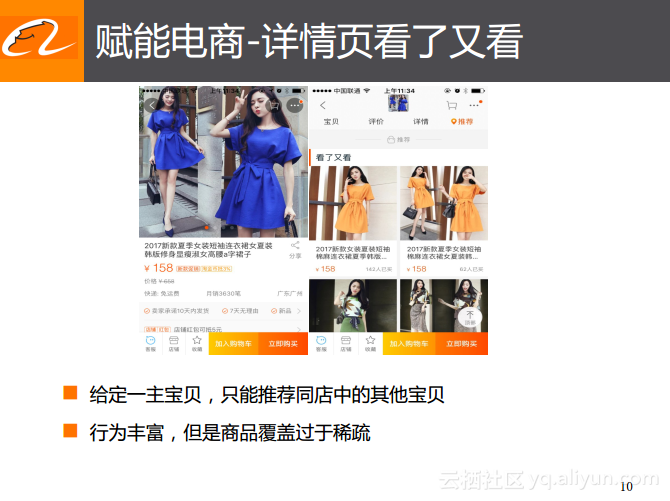
对于详情页的推荐场景的设计方式是给定一个主宝贝,根据这个宝贝来推荐当前同一个店铺中的其他商品。在这个场景下非常有意思的一点就是行为往往非常丰富,因为一方面用户每天浏览过的商品可能会有上亿或者上十亿个,另一方面与商品相关的其他商品的关系却是非常稀疏的,虽然用户每天都会看到很多商品,但是商品之间发生了有效行为的情况却是非常少的,并且非常不均衡,这就使得直接训练可能会造成不均衡,而整个模型由于数据的分布以及用户行为的稀疏度,所训练出来的效果也不会特别好。
迁移学习
面对以上所提到的问题,手淘在详情页推荐中就采取了一个新的思路:迁移学习。首先,利用了淘宝中与用户历史行为相关的全量数据,其中包括了搜索、推荐以及广告等数据,对于这些数据进行统一的处理,然后使用上述在搜索场景中所提到的模型结构去训练深度学习模型,并学习用户和商品之间的特征。这里为了统一地进行处理,就将搜索场景中的query或者检索词相关的域与推荐场景中的信息,比如详情页中的主商品信息都统一地去除掉,只去考虑用户点击过或者购买过的商品之间的关系,通过深度学习的方案可以学习出用户和商品的特征表达。
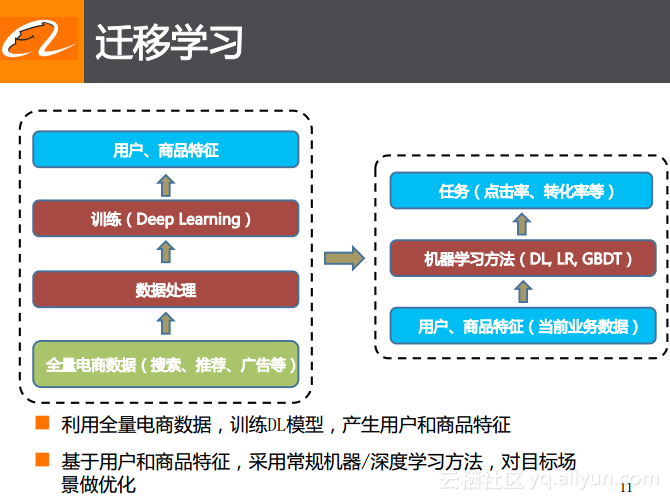
前面也曾提到,深度学习技术之所以有效的很重要的一个原因就是其可以自己学习出来针对于原始输入的特征表达,也就是可以学习出当前目标下的更好的特征表达。而使用迁移学习的方案,就能够得到稳定的、鲁棒的用户与商品的特征表达,将这个特征直接作为商品和用户的表达,同时与当前业务也就是商品详情页推荐业务下的日志相结合,之后使用类似于传统的机器学习的方法,比如可以将传统机器学习方法中的LR、GBDT通过DL进行实现,通过这两部分的结合形成的迁移学习方案得到了很好的效果提升。同时,采用这样的方法可以保证所学习出来的仅具有少量数据或者数据比较稀疏的场景下也能获得稳定的转化以及点击率的提升。
四、新场景探索-优酷短视频搜索
接下来以优酷短视频搜索为例为大家分享阿里巴巴在新场景下应用深度学习的探索。前面所提到的搜索、推荐以及个性化基本都是在电商领域下,现在也将其推广到了优酷的短视频搜索场景下。
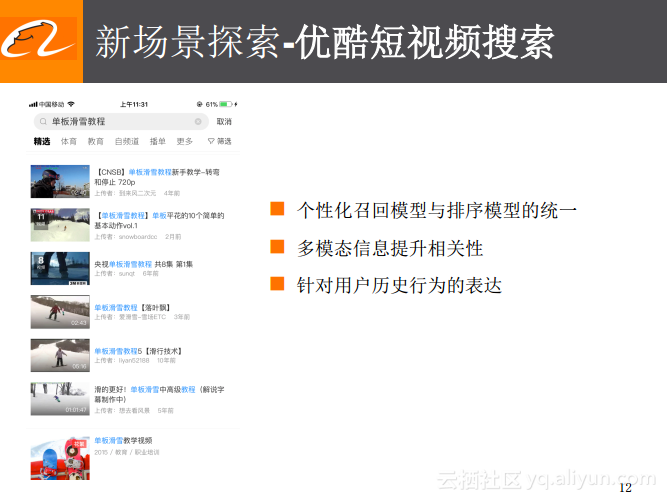
短视频的搜索与传统的电视剧的搜索不完全一样,一方面短视频的搜索需要考虑到检索词与短视频之间的相关性,另一方面还需要考虑短视频的真正质量,所以这里也存在转化的概念。在短视频搜素场景下需要对之前的整体模型方案进行改进,所做的改进主要可以分为三点:首先,之前的检索方案只有在最后的几万个或者几千个商品的重排过程中才会引入个性化的信息,而在短视频搜索场景下的模型中则是将个性化前移到召回的部分,同时与最终的排序模型进行了统一;其次就是多模态信息的使用,视频检索需要考虑到相关性,相关性最简单的是文本与文本之间的相关性,但是对于短视频而言,最终需要搜索到的是视频内容,所以一方面采用了文本信息,另一方面采用了视频以及图像信息来进行表达,而对于这些不同域下的信息都做了embedding,之后再使用之前提到的统一的模型,该模型将行为编码和内容相关的编码整合到一起,这样既考虑到了相关性,同时又可以提升最终转化率。最后一点的改进就是针对用户历史行为的表达,之前在做用户表达时更多地采用了历史的行为信息来表达用户,但是这里面存在的问题就是在淘宝场景下,用户的行为是非常丰富的,每个用户在一个月内都会产生大量的行为,而且行为的稳定性也非常好,这时候就可以加入很多的历史数据以此较好地描述出用户的行为偏好是什么,但是在像优酷短视频搜索这样的新场景下,用户的行为是很稀疏的,很可能用户一个月内的短视频类的搜索仅有几次,这就使得用户的历史行为很难去描述出真正的偏好,所以在这样的场景中采用了新的方案就是将用户全网的观看历史行为全部提取出来,利用这些信息来表达用户的偏好,然后再将用户表达的其他信息整合到排序模型里面来提升个性化的影响。
个性化的召回
在个性化的召回方面采用了一个非常经典的模型结构——DSSM。通过这样的模型结构可以直接去学习检索词、用户以及视频表达的embedding之间的关系,进而最小化embedding之间的距离。在模型中,为了简化线上操作,用户和检索词的embedding只是进行了简单的累加,并没有对其进行统一的编码。累加之后的结果直接与视频相关的embedding做COS距离的最小化。
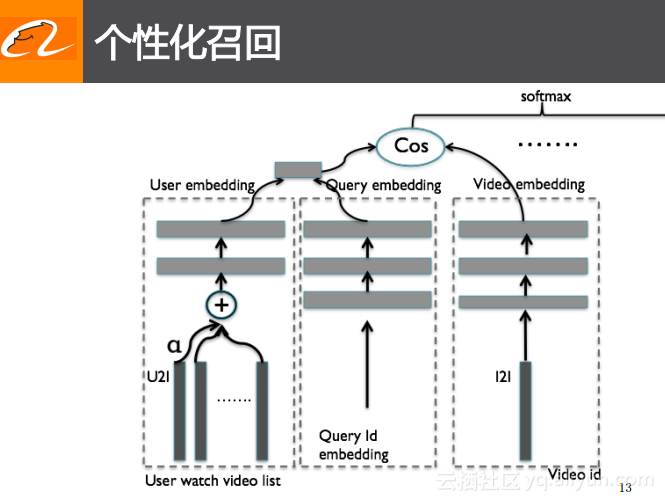
如上图左侧所示,模型中并没有对每个用户都进行ID表达,这是因为使用ID表达需要大量的有效的行为数据,而是将ID表达都转换成了视频的ID表达,用户所观看过的历史视频的ID可以做一个简单的平均来用于表达用户。通过这个框架就可以直接去学习出不同的embedding之间的距离,并根据距离从小到大进行排序进而得到最终想要的排序结果。之所以说这是一个个性化的召回模型,是因为可以直接将检索词与视频之间相关的部分加入用户的信息,也就是说在检索的第一步中就会考虑到用户信息。不同于以往的召回模型只需要做一个倒排表就可以完成,现在优酷短视频搜索场景下的基于embedding的方案可以采用新的量化索引的解决方案来处理海量数据的检索,最终通过工程以及针对量化索引引擎的优化可以实现实时地完成个性化召回计算,并且可以在计算时间不变化的情况下获得更好的效果。
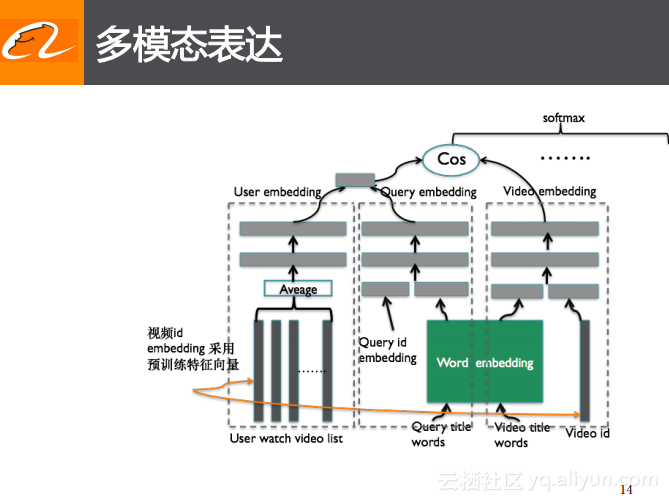
多模态表达
上一个图中的模型只是采用了与query以及ID相关的表达,其实在做与召回更加相关的任务时需要考虑检索词的文本信息以及视频的文本信息,以及如下图所示的视频相关的一些展示图embedding信息。需要同时考虑以上这些信息,然后使用多个行为信息、文本信息、视频信息以及图像信息等的融合表达来提升整体的效果。这个方案相比于之前的ID方案,鲁棒性会更强,这是因为文本信息的加入会对于新产生的视频起到更好的召回效果。
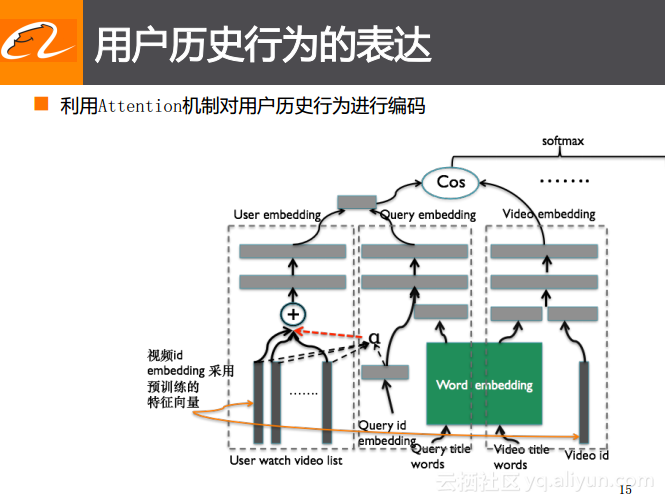
用户历史行为的表达
用户历史行为表达的最简单的方案就是用视频表示用户,也就是将用户之前所观看过的视频的列表的ID放在一起存储起来,或者先做一个embedding的编码,然后将embedding向量进行平均,用平均数来表达用户的历史偏好。但是这里也存在一定的问题,就是用户历史的观看行为以及在电商中的购买行为是多种多样的,可能是多个领域下的行为,而这些信息中究竟哪些信息与当前场景下的检索词是更加相关的呢?所以如果能够找到与当前检索词更加相关的历史偏好就能够极大地提升排序的结果。举个简单的例子就是用户搜索了“体育视频”这个词,某些用户之前观看过足球类的视频,而有些用户则观看过篮球类的视频,通过检索词的embedding与之前embedding的相似度比较或者做一个Attention,用当前这个“体育视频”去找到与其更加相关的这些历史行为,这样就能实现对于不同用户产生不同的表达,并且忽略掉其他不相关的信息,这样就能更好地获取用户在当前检索词下的偏好,使用此偏好与之前提到的整体的模型框架整合到一起之后就能够将召回的结果展示给用户。这就是对于表达用户历史行为的改进方案,通过利用Attention机制的方案以及前面几种不同的改进方法在优酷短视频搜索场景里对于转化产生了很大的提升。
总结
总结而言,本文首先针对于深度学习的特点进行了分享,深度学习具有很强的特征提取能力以及拟合能力。之后针对手淘几个场景介绍了具体使用的深度学习技术,最后介绍了如何将电商领域中的推荐实践扩展到短视频领域的新场景下,帮助实现效果的提升。
阅读更多干货好文,请关注扫描以下二维码:

