

距离上次教程已经过了快两周了,没办法啊,学业繁忙(¬、¬) (¬_¬)
本文用到的三个工具为
- cheerio:jQuery语法,帮助你在非浏览器环境下解析网页用的
- 上次没用到,这个肯定用到啦
- segment 一个基于盘古词库的中文分词工具,cnode大神写的,手动@leizongmin大神
cheerio用法
const cheerio = require('cheerio'),
$ = cheerio.load('<h2 class="title">Hello world</h2>');
$('h2.title').text('Hello there!');
$('h2').addClass('welcome');
$.html();
//=> <h2 class="title welcome">Hello there!</h2>
额外用法戳这里
segment 用法
const Segment = require('segment');
// 创建实例
const segment = new Segment();
// 使用默认的识别模块及字典,载入字典文件需要1秒,仅初始化时执行一次即可
segment.useDefault();
// 开始分词
console.log(segment.doSegment('这是一个基于Node.js的中文分词模块。'));
// [ { w: '这是', p: 0 },
// { w: '一个', p: 2097152 },
// { w: '基于', p: 262144 },
// { w: 'Node.js', p: 8 },
// { w: '的', p: 8192 },
// { w: '中文', p: 1048576 },
// { w: '分词', p: 4096 },
// { w: '模块', p: 1048576 },
// { w: '。', p: 2048 } ]
但是我们一般不需要输出词性,也不需要输出多余的标点符号,所以
const result = segment.doSegment(text, {
simple: true, //不输出词性
stripPunctuation: true //去除标点符号
});
// [ '这是', '一个', '基于', 'Node.js', '的', '中文', '分词', '模块' ]
更高级用法见segment
全部代码见github
基本用法也了解了,接下来进入正题吧╰(●’◡’●)╮
爬取图片
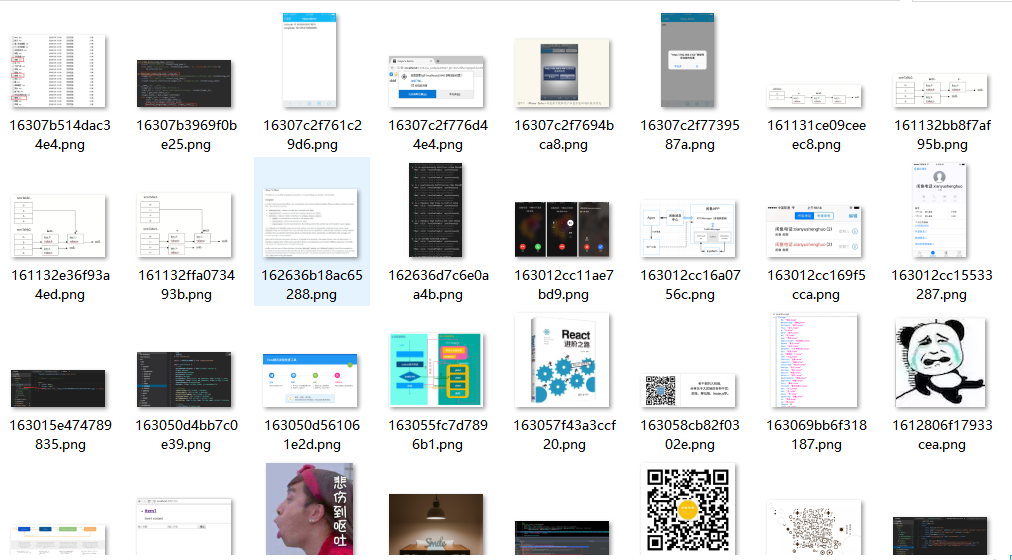
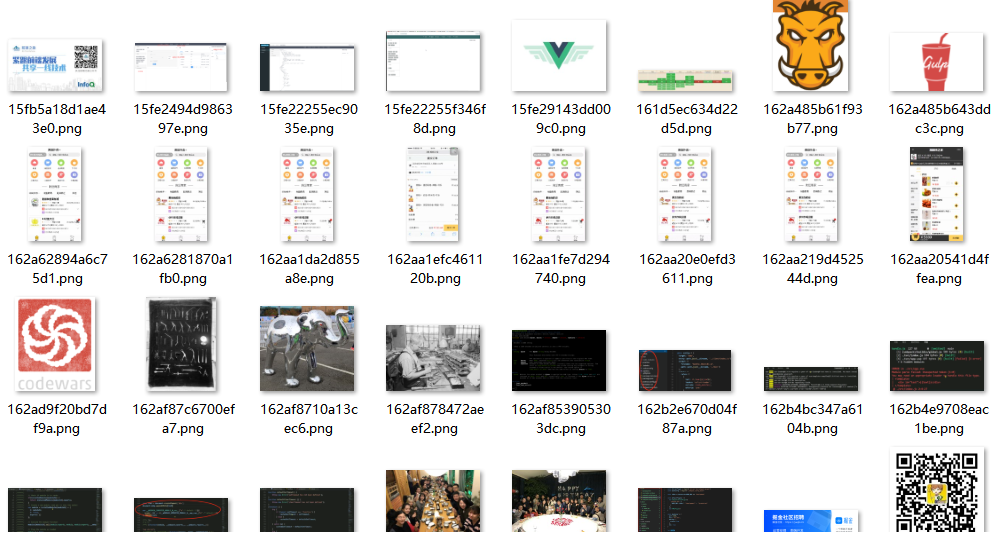
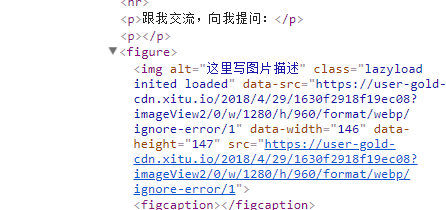
可以看到img元素上面src和自定义的data-src属性都带有图片地址,至于为什么再下面的代码中我没有获取src的值
完全是我太菜了◔ ‸◔?,img.eq(i).src 获取不到值,只能 prop('data-src') 了
自定义属性兼容性很差劲
Internet Explorer 11+ Chrome 8+ Firefox 6.0+ Opera 11.10+ Safari 6+
熟悉正则的同学,稍微分析下图片的地址就可以通过正则来获取url了,以下是我给出的示例
/(https:\/\/user-gold-cdn).+?\/ignore-error\/1/g
需要注意的是/的转义,以及惰性匹配.+?,关于惰性匹配我这里不打算说了(稍微提一下下(//▽//),其实就是匹配符合要求的最短串),要是说起来又可以写一大堆了
想详细了解的同学可以看看这个解释
/**
*
* @param {any} $ cheerio
* @param {any} request 请求函数
*/
function saveImg($, request) {
const img = $('.lazyload');
const origin = request.default(); //这里是我对request进行了一个简单的封装,default返回未封装的request
for (let i = 0; i < img.length; ++i) {
//data.body.match(/(https:\/\/user-gold-cdn).+?\/ignore-error\/1/g)
let src = img.eq(i).prop('data-src');
let name = src.match(/\/.{16}\?/g) && src.match(/\/.{16}\?/g)[0].slice(1, -1); //匹配出图片名称
if (name) {
origin.get(src).pipe(fs.createWriteStream(`./images/${name}.png`)); //愉快的下载图片
}
}
}
数据处理
介绍下用的数据结构Map,用来存储词频(词-词出现的次数)
类似于对象,也是键值对的集合,但是“键”的范围不限于字符串,各种类型的值(包括对象)都可以当作键。也就是说,Object 结构提供了“字符串—值”的对应,Map 结构提供了“值—值”的对应,是一种更完善的 Hash 结构实现。如果你需要“键值对”的数据结构,Map 比 Object 更合适。
其实对于本文来讲,键都为字符串,用对象也完全没有问题,使用Map完全是为了尝鲜 (●’◡’●)ノ 关于Map复制的解释,这一点和对象又不一样
Map复制


async function getPage(request, url) {
const data = await request.get({ url });
const $ = cheerio.load(data.body);
saveImg($, request);
//获取内容
let length = $('p').length;
for (let i = 0; i < length; ++i) {
let result = segment.doSegment(
$('p') //大部分内容都是p标签包裹的,这里不做过复杂的处理
.eq(i)
.text(),
{
simple: true, //不输出词性
stripPunctuation: true //去除标点符号
}
);
result.forEach((item, key) => {
map.set(item, map.get(item) + 1 || 1); //1 + undefined || 1 => 1
});
}
map = sortToken(map);
}
function sortToken(map) {
const words = {}; //存储词
let mapCopy = new Map(map); //获取副本,Map直接赋值应该也是地址引用,参见上文
map.forEach((value, key) => {
//分词长度大于1
if (value !== 1 && key.length > 1) { //词频大于1且不是单个字的留下,单字没有什么号分析的吧?
words[key] = value;
}
if (value === 1) { //词频过低,直接刷了
mapCopy.delete(key);
}
});
const keys = Object.keys(words);
//排序
keys.sort((a, b) => {
return words[b] - words[a];
});
// 每篇文章词频最高的20个词,有兴趣了解的同学可以去看看top k算法(我们是获取前k个,它是获取第k个,但是它这样需要把前k个都保存下来,用来比较哪些是前k大)
// 我这个方法只是粗略的获取词频最高的20个词,实际上会有偏差,假设第一次排序,第十一个词词频为23,而第二次排序,第十个词词频为12,这样本来之前词频高的反被刷了
// 但这样的好处是节省内存(其实是假的),真正的可以利用最大堆和利用数据库存储,这样就不用存在内存了
// 最后爬取完了,从数据库取出数据,再参照top k思想算法得出结果
keys.slice(0, 20).forEach(item => {
console.log(item, words[item]);
});
//返回分词中词频为1的分词
return mapCopy;
}
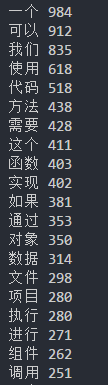
代码,方法,函数,对象,执行,调用,组件等等跟代码有关的中文词语都出现了
不过还是一个最受欢迎,出现次数快1000次了 (」゜ロ゜)」
有兴趣的同学,可以使用英文分词进行分析,分析下程序员们写文章喜欢写什么代码
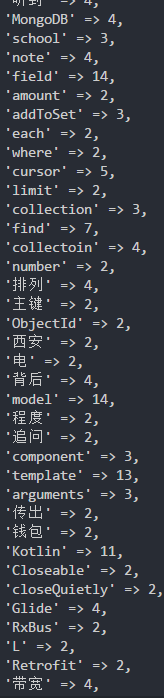
还可以再分析标题,然后还可以改进排序算法,直接把整个article-content(class)的text进行分析,而不是像我一样,只是分析p标签 (๑•̀_•́๑) ,最后用可视化工具(例如e-cahrt)把数据展示出来
喜欢的同学可以star哦github
以上,如有错误,欢迎大家指正
