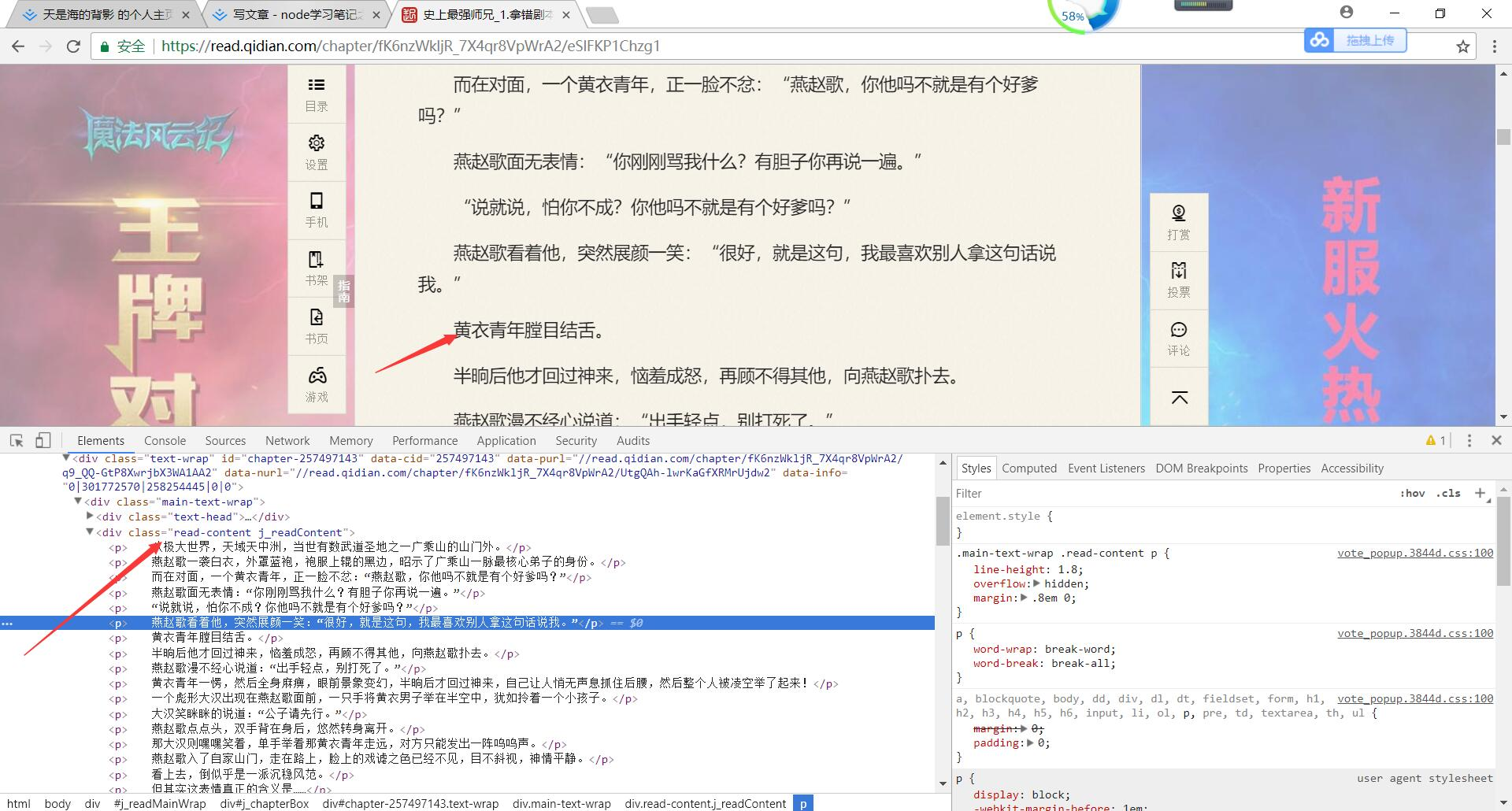
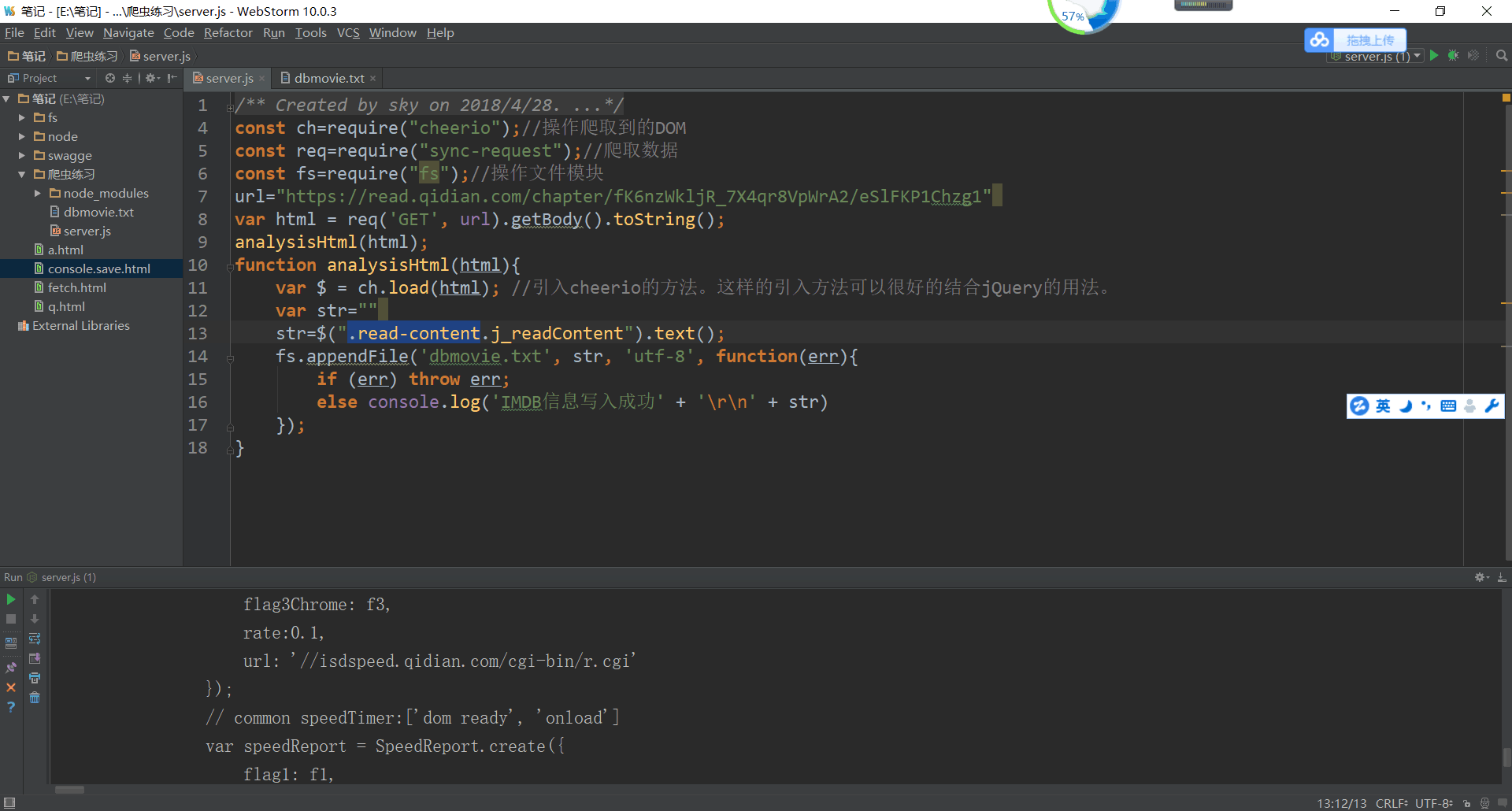
node学习笔记之爬虫 天是海的背影 2018-04-28 235 阅读1分钟 之前一至在想用node写一次爬虫,正好今天看到一篇文章是讲爬虫的,正好写写练练手 分析爬虫的过程, 1 确定目标(我这以奇点为准 2 爬取数据 3 分析数据 4 存绪数据 下面开始开撸 引入头部文件 爬取到了网页数据。现在开始分析网页结构 通过分析得到我们要的是一个为“.read-content”类名的内容 现在开始操作它 到此完了 这只是一个小DEMO,个人感觉其它的都是大同小异,更深入的比较网页编码格式 问题,廷时什么 的有待大神们指导