


如图所示,利用pipeline我们可以方便的减少代码量同时让机器学习的流程变得直观,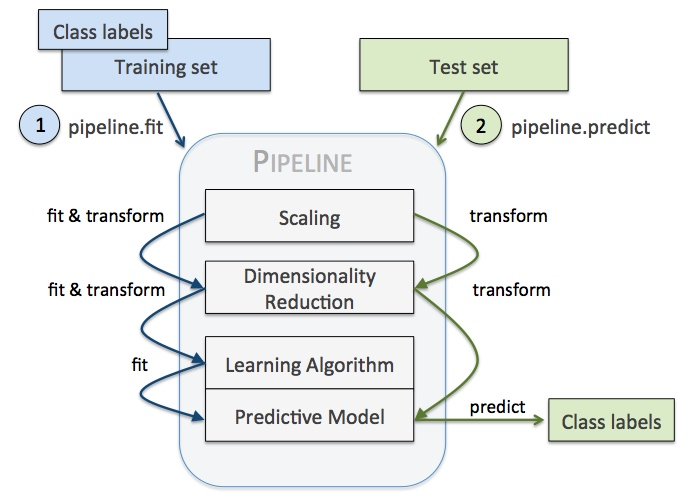
例如我们需要做如下操作,容易看出,训练测试集重复了代码,
vect = CountVectorizer()
tfidf = TfidfTransformer()
clf = SGDClassifier()
vX = vect.fit_transform(Xtrain)
tfidfX = tfidf.fit_transform(vX)
predicted = clf.fit_predict(tfidfX)
# Now evaluate all steps on test set
vX = vect.fit_transform(Xtest)
tfidfX = tfidf.fit_transform(vX)
predicted = clf.fit_predict(tfidfX)利用pipeline,上面代码可以抽象为,
pipeline = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('clf', SGDClassifier()),
])
predicted = pipeline.fit(Xtrain).predict(Xtrain)
# Now evaluate all steps on test set
predicted = pipeline.predict(Xtest)注意,pipeline最后一步如果有predict()方法我们才可以对pipeline使用fit_predict(),同理,最后一步如果有transform()方法我们才可以对pipeline使用fit_transform()方法。
使用pipeline做cross validation
看如下案例,即先对输入手写数字的数据进行PCA降维,再通过逻辑回归预测标签。其中我们通过pipeline对
PCA的降维维数n_components和逻辑回归的正则项C大小做交叉验证,主要步骤有:
- 依次实例化各成分对象如
pca = decomposition.PCA() - 以(name, object)的tuble为元素组装pipeline如
Pipeline(steps=[('pca', pca), ('logistic', logistic)]) - 初始化CV参数如
n_components = [20, 40, 64] - 实例化CV对象如
estimator = GridSearchCV(pipe, dict(pca__n_components=n_components, logistic__C=Cs)),其中注意参数的传递方式,即key为pipeline元素名+函数参数
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model, decomposition, datasets
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
logistic = linear_model.LogisticRegression()
pca = decomposition.PCA()
pipe = Pipeline(steps=[('pca', pca), ('logistic', logistic)])
digits = datasets.load_digits()
X_digits = digits.data
y_digits = digits.target
# Prediction
n_components = [20, 40, 64]
Cs = np.logspace(-4, 4, 3)
pca.fit(X_digits)
estimator = GridSearchCV(pipe,
dict(pca__n_components=n_components, logistic__C=Cs))
estimator.fit(X_digits, y_digits)
plt.figure(1, figsize=(4, 3))
plt.clf()
plt.axes([.2, .2, .7, .7])
plt.plot(pca.explained_variance_, linewidth=2)
plt.axis('tight')
plt.xlabel('n_components')
plt.ylabel('explained_variance_')
plt.axvline(
estimator.best_estimator_.named_steps['pca'].n_components,
linestyle=':',
label='n_components chosen')
plt.legend(prop=dict(size=12))
plt.show()自定义transformer
我们可以如下自定义transformer(来自Using Pipelines and FeatureUnions in scikit-learn - Michelle Fullwood)
from sklearn.base import BaseEstimator, TransformerMixin
class SampleExtractor(BaseEstimator, TransformerMixin):
def __init__(self, vars):
self.vars = vars # e.g. pass in a column name to extract
def transform(self, X, y=None):
return do_something_to(X, self.vars) # where the actual feature extraction happens
def fit(self, X, y=None):
return self # generally does nothing另外,我们也可以对每个feature单独处理,例如下面的这个比较大的流水线(来自Using scikit-learn Pipelines and FeatureUnions | zacstewart.com),我们可以发现作者的pipeline中,首先是一个叫做features的FeatureUnion,其中,每个特征分别以一个pipeline来处理,这个pipeline首先是一个ColumnExtractor提取出这个特征,后续进行一系列处理转换,最终这些pipeline组合为特征组合,再喂给一系列ModelTransformer包装的模型来predict,最终使用KNeighborsRegressor预测(相当于两层stacking)。
pipeline = Pipeline([
('features', FeatureUnion([
('continuous', Pipeline([
('extract', ColumnExtractor(CONTINUOUS_FIELDS)),
('scale', Normalizer())
])),
('factors', Pipeline([
('extract', ColumnExtractor(FACTOR_FIELDS)),
('one_hot', OneHotEncoder(n_values=5)),
('to_dense', DenseTransformer())
])),
('weekday', Pipeline([
('extract', DayOfWeekTransformer()),
('one_hot', OneHotEncoder()),
('to_dense', DenseTransformer())
])),
('hour_of_day', HourOfDayTransformer()),
('month', Pipeline([
('extract', ColumnExtractor(['datetime'])),
('to_month', DateTransformer()),
('one_hot', OneHotEncoder()),
('to_dense', DenseTransformer())
])),
('growth', Pipeline([
('datetime', ColumnExtractor(['datetime'])),
('to_numeric', MatrixConversion(int)),
('regression', ModelTransformer(LinearRegression()))
]))
])),
('estimators', FeatureUnion([
('knn', ModelTransformer(KNeighborsRegressor(n_neighbors=5))),
('gbr', ModelTransformer(GradientBoostingRegressor())),
('dtr', ModelTransformer(DecisionTreeRegressor())),
('etr', ModelTransformer(ExtraTreesRegressor())),
('rfr', ModelTransformer(RandomForestRegressor())),
('par', ModelTransformer(PassiveAggressiveRegressor())),
('en', ModelTransformer(ElasticNet())),
('cluster', ModelTransformer(KMeans(n_clusters=2)))
])),
('estimator', KNeighborsRegressor())
])class HourOfDayTransformer(TransformerMixin):
def transform(self, X, **transform_params):
hours = DataFrame(X['datetime'].apply(lambda x: x.hour))
return hours
def fit(self, X, y=None, **fit_params):
return selfclass ModelTransformer(TransformerMixin):
def __init__(self, model):
self.model = model
def fit(self, *args, **kwargs):
self.model.fit(*args, **kwargs)
return self
def transform(self, X, **transform_params):
return DataFrame(self.model.predict(X))FeatureUnion
sklearn.pipeline.FeatureUnion — scikit-learn 0.19.1 documentation 和pipeline的序列执行不同,FeatureUnion指的是并行地应用许多transformer在input上,再将结果合并,所以自然地适合特征工程中的增加特征,而FeatureUnion与pipeline组合可以方便的完成许多复杂的操作,例如如下的例子,
pipeline = Pipeline([
('extract_essays', EssayExractor()),
('features', FeatureUnion([
('ngram_tf_idf', Pipeline([
('counts', CountVectorizer()),
('tf_idf', TfidfTransformer())
])),
('essay_length', LengthTransformer()),
('misspellings', MispellingCountTransformer())
])),
('classifier', MultinomialNB())
])整个features是一个FeatureUnion,而其中的ngram_tf_idf又是一个包括两步的pipeline。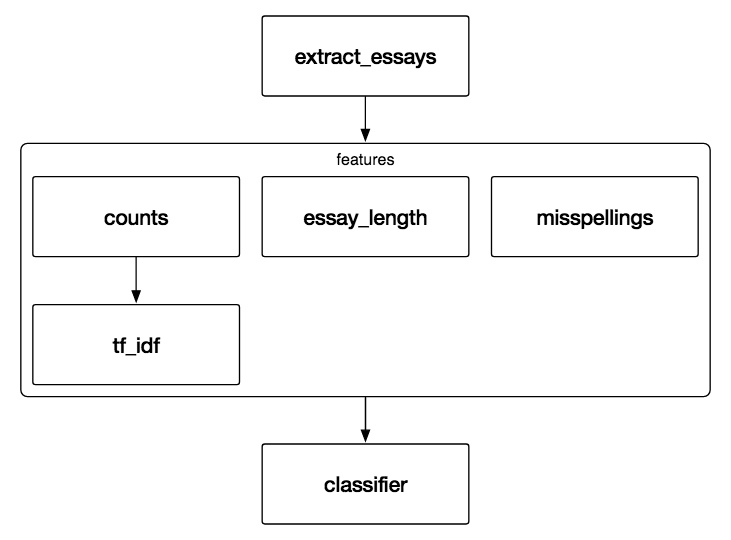
下面的例子中,使用FeatureUnion结合PCA降维后特征以及选择原特征中的几个作为特征组合再喂给SVM分类,最后用grid_search 做了 pca的n_components、SelectKBest的k以及SVM的C的CV。
from sklearn.pipeline import Pipeline, FeatureUnion
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest
iris = load_iris()
X, y = iris.data, iris.target
print(X.shape, y.shape)
# This dataset is way too high-dimensional. Better do PCA:
pca = PCA()
# Maybe some original features where good, too?
selection = SelectKBest()
# Build estimator from PCA and Univariate selection:
svm = SVC(kernel="linear")
# Do grid search over k, n_components and C:
pipeline = Pipeline([("features",
FeatureUnion([("pca", pca), ("univ_select",
selection)])), ("svm",
svm)])
param_grid = dict(
features__pca__n_components=[1, 2, 3],
features__univ_select__k=[1, 2],
svm__C=[0.1, 1, 10])
grid_search = GridSearchCV(pipeline, param_grid=param_grid, verbose=10)
grid_search.fit(X, y)
grid_search.best_estimator_
grid_search.best_params_
grid_search.best_score_