

谢邀,好问题。(最近正在给公司进行容器化,累死我了还要邀请我讲那么烧脑的问题哈哈哈...
奇巧淫技这种东西嘛,我也不知道算不算,但是最近在commit中看到一个,nextTick队列被重新设计。
(文末有彩蛋)
实际上还有挺多的:
- async hook的设计
- timer时间轮优化,http date缓存获取
- 包机制(我觉得挺巧的
- stream的设计(back press,hwm)等等...
戏说nextTick队列
熟悉 node 事件循环的同学应该知道,我们在一个循环中设置nextTick回调的时候,会在本轮循环的末尾,mirco task前面执行。
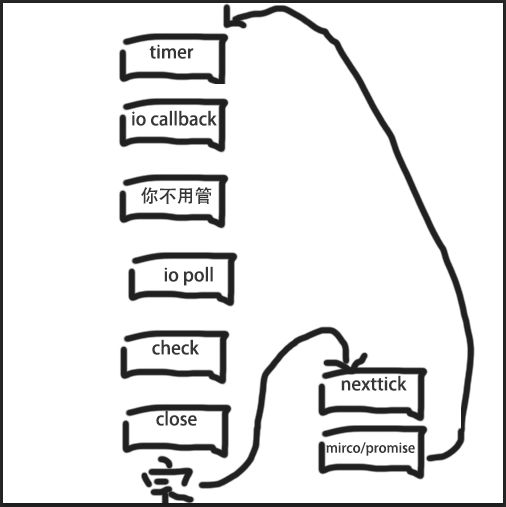
事件循环其实要分,你要分为除去libuv提供的 6大阶段之外,还要加上 node.js 本身实现的两个阶段,才构成了完整的事件循环。
那么本轮的最后会执行所有的nexttick,在实际上,我们会大量使用nexttick这个回调(无论是node开发者,还是node使用者)。在最初的版本里,nextick的队列是这样的:
var nexTickCallback = [];
简单粗暴。早期实现中,这并没有什么问题,直到后来这个pr的出现:#13446,这个哥们发现了一个神奇的现象:使用es6构造一个数组,手动添加clear,push,shift等方法,比原生的[]要快接近20%.以下是结果:
improvement confidence p.value
process/next-tick-breadth-args.js millions=2 27.75 % *** 1.271176e-20
process/next-tick-breadth.js millions=2 7.71 % *** 4.155765e-13
process/next-tick-depth-args.js millions=12 47.78 % *** 4.150674e-52
process/next-tick-depth.js millions=12 47.32 % *** 7.742778e-31
那么他给nextTick添加了一个什么代码呢?没有错,他只是简单的使用es6的class自己写了一个function:
class NextTickQueue {
constructor() {
this.head = null
this.tail = null
this.length = 0
}
push(v) {
const entry = { data: v, next: null }
if (this.length > 0) this.tail.next = entry
else this.head = entry
this.tail = entry
++this.length
}
shift() {
if (this.length === 0) return
const ret = this.head.data
if (this.length === 1) this.head = this.tail = null
else this.head = this.head.next
--this.length
return ret
}
clear() {
this.head = null
this.tail = null
this.length = 0
}
}
就这样一个修改,性能提升20%!
这个函数是有通用性的,也就是说我们可以运用到现实生活中去优化我们队列的大量操作。为此,我特地写了一份测试函数。得到的结果真是让人兴奋。
使用一个特殊的可重用单向链表去优化速度
又过了一段时间,nextTick的实现再次被踢翻,具体的pr再这里:pr:#18617,这位哥们的做法更加变态:他的思路其实很简单,我们push操作的时候,系统都会申请一块新的空间来存储,清理的时候会将一大块内存都清理掉,那么这样实在是有点浪费,不如一次性申请好一堆内存,push的时候按位置放进去不就完了?于是有了现在的实现:
// 现在的设计变成了这样子:是一个单项链表,每个链表中的元素,都有一个固定为2048长度的数组
// 如果单次注册回调的次数少于2048次,那么只会一次性分出2048个长度的array提供使用
//这2048长度的数组中的内存是可以重复使用的
//
// head tail
// | |
// v v
// +-----------+ <-----\ +-----------+ <------\ +-----------+
// | [null] | \----- | next | \------- | next |
// +-----------+ +-----------+ +-----------+
// | tick | <-- bottom | tick | <-- bottom | [empty] |
// | tick | | tick | | [empty] |
// | tick | | tick | | [empty] |
// | tick | | tick | | [empty] |
// | tick | | tick | bottom --> | tick |
// | tick | | tick | | tick |
// | ... | | ... | | ... |
// | tick | | tick | | tick |
// | tick | | tick | | tick |
// | [empty] | <-- top | tick | | tick |
// | [empty] | | tick | | tick |
// | [empty] | | tick | | tick |
// +-----------+ +-----------+ <-- top top --> +-----------+
//
//回调比较少的情况
// head tail head tail
// | | | |
// v v v v
// +-----------+ +-----------+
// | [null] | | [null] |
// +-----------+ +-----------+
// | [empty] | | tick |
// | [empty] | | tick |
// | tick | <-- bottom top --> | [empty] |
// | tick | | [empty] |
// | [empty] | <-- top bottom --> | tick |
// | [empty] | | tick |
// +-----------+ +-----------+
//
//当往队列中插入一个callback的时候,top就会往下走一个格子
//当从中取出的时候,bottom也会从中取出一个,如果不为空,则直接返回,
//调整bottom的位置往下走
//
//
//判断一个表是否满了或者全空非常简单(2048),当top===bottom的时候,
//list[top] !== undefine 那就是满了
//会重新生成一个表
//如果top===bottom && list[top] === void 666
//那就证明,这个表已经空了
经过这个commits的测试,性能提高40%
confidence improvement accuracy (*) (**) (***)
process/next-tick-breadth-args.js millions=4 *** 40.11 % ±1.23% ±1.64% ±2.14%
process/next-tick-breadth.js millions=4 *** 7.16 % ±3.50% ±4.67% ±6.11%
process/next-tick-depth-args.js millions=12 *** 5.46 % ±0.91% ±1.22% ±1.59%
process/next-tick-depth.js millions=12 *** 23.26 % ±2.51% ±3.36% ±4.40%
process/next-tick-exec-args.js millions=5 *** 38.64 % ±1.16% ±1.55% ±2.01%
process/next-tick-exec.js millions=5 *** 77.20 % ±1.63% ±2.18% ±2.88%
Be aware that when doing many comparisions the risk of a false-positive
result increases. In this case there are 6 comparisions, you can thus
expect the following amount of false-positive results:
0.30 false positives, when considering a 5% risk acceptance (*, **, ***),
0.06 false positives, when considering a 1% risk acceptance (**, ***),
0.01 false positives, when considering a 0.1% risk acceptance (***)
总结一下nexttick
其实也不算是什么奇巧淫技,也就是业界中常用的「空间换时间」的做法了。
这个「空间换时间」的做法总结成:
当构建一个复杂javascript对象时,我们可以使用对象池的方式进行对对象的重用,能够大量减少系统压力,虽然说多费一点内存,但是现阶段来说,内存几乎是不值钱的。
出题:
通过这种思想,我们在设计web框架的时候,有一个东西大量创建,这个东西具体是什么呢?嘿嘿嘿嘿嘿....
(我才不说,免得抢我pr)
