

本文抓取赶集网小狗数据存储到MySQL
关于pyquery的使用可以参考这篇文章pyquery全面总结
在安装配置好MySQL的情况下,创建名为ganji的数据库,在ganji中创建名为dog的表,然后运行下面代码(里面要填写读者安装mysql时创建的密码)
import requests # 导入请求库
from pyquery import PyQuery as pq # 导入解析库
import pymysql # 用于连接并操作MySQL数据库
def start_requests(url):
r = requests.get(url)
return r.content
def parse(text):
doc = pq(text)
for li in doc('.petItem'):
doci = pq(li)
counts = doci('span.counts').text().split(' ')
yield {
'title': doci('.itemTitle').text().replace('\xa0', ''),
'price': doci('.price').text().split(' ')[0],
'store': doci('.storeName').text().strip(),
'score': counts[0],
'sold': counts[1],
'url': doci.attr('href')
}
def main():
url = 'http://www.xinchong.com/xm/idog/?source=p_ganji_dog_list_1&fcity=xm&gj_other_ca_kw=-&gj_other_ca_s=-&gj_other_sid=&gj_other_gjuser=-&gj_other_ifid=from_ganji&gj_other_gc_1=chongwu&gj_other_city_id=12&gj_other_ca_i=-&gj_other_ca_n=-&gj_other_uuid=-'
text = start_requests(url)
connection = pymysql.connect(host='localhost', # 连接数据库
user='root',
password='', # 你安装mysql时设置的密码
db='ganji',
charset='utf8',
cursorclass=pymysql.cursors.DictCursor)
sql = "insert into dog(title, price, store, score, sold, url)values(%s,%s,%s,%s,%s,%s)"
try:
with connection.cursor() as cursor:
for item in parse(text):
cursor.execute(sql, (
item['title'], item['price'], item['store'], item['score'], item['sold'], item['url']))
connection.commit() # 提交刚刚执行的SQL处理,使其生效
finally:
connection.close()
if __name__ == '__main__':
main()
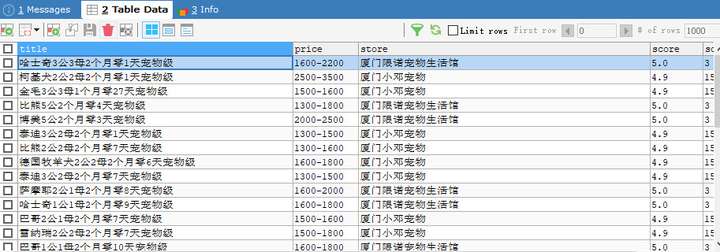
抓取结果如下
如果想要不用事先在数据库中创建再用python连接,而是直接在python中创建数据库和表,可以这样
import requests # 导入请求库
from pyquery import PyQuery as pq # 导入解析库
import pymysql # 用于连接并操作MySQL数据库
def start_requests(url):
r = requests.get(url)
return r.content
def parse(text):
doc = pq(text)
for li in doc('.petItem'):
doci = pq(li)
counts = doci('span.counts').text().split(' ')
yield {
'title': doci('.itemTitle').text().replace('\xa0', ''),
'price': doci('.price').text().split(' ')[0],
'store': doci('.storeName').text().strip(),
'score': counts[0],
'sold': counts[1],
'url': doci.attr('href')
}
def main():
url = 'http://www.xinchong.com/xm/idog/?source=p_ganji_dog_list_1&fcity=xm&gj_other_ca_kw=-&gj_other_ca_s=-&gj_other_sid=&gj_other_gjuser=-&gj_other_ifid=from_ganji&gj_other_gc_1=chongwu&gj_other_city_id=12&gj_other_ca_i=-&gj_other_ca_n=-&gj_other_uuid=-'
text = start_requests(url)
connection = pymysql.connect(host='localhost', # 少了指定数据库
user='root',
password='', # 你安装mysql时设置的密码
charset='utf8',
cursorclass=pymysql.cursors.DictCursor)
# 加两条SQL执行语句,创建数据库和表
# 注意这时每次调用表都要前面先指定数据库(因为connection没有指定哪个数据库了)
create_db = 'CREATE DATABASE IF NOT EXISTS ganji2;'
create_table = '''create table ganji2.dog
(
title char(20),
price char(20),
store char(20),
score char(20),
sold char(20),
url char(100)
);
'''
# 其他的都没有变
sql = 'insert into ganji2.dog(title, price, store, score, sold, url)values(%s,%s,%s,%s,%s,%s)'
try:
with connection.cursor() as cursor:
cursor.execute(create_db)
cursor.execute(create_table)
for item in parse(text):
cursor.execute(sql, (
item['title'], item['price'], item['store'], item['score'], item['sold'], item['url']))
connection.commit()
finally:
connection.close()
if __name__ == '__main__':
main()
上面代码的基础已经在前面文章中讲过,有问题可以参考下面文章
专栏信息
专栏主页:python编程
专栏目录:目录
爬虫目录:爬虫系列目录
版本说明:软件及包版本说明
