

3月27号 Google Brain 的 David Ha 跟 Swiss AI Lab的人合作发了一篇叫世界模型(world model)的论文,还跟着发了一个网站,标题是"智能体能在自己的梦里学习么"(Can agents learn inside of their own dreams?),我觉得非常有意思,跟大家分享一下。原文在这里:arxiv.org/pdf/1803.10… 网站在这里:World Models
背景知识
这个论文讨论的是强化学习(reinforcement learning),这个世界模型可以把现在训练这些Agent(智能体)的环境压缩,这样可以训练出更简练的policy来解决agent的问题。甚至这个agent可以在这个world model里面先训练好了(就像在梦中训练一样),再放到真实环境里面去解决问题。文中提到,这个训练方式的想法是来自于人类大脑解决问题的方式。每天人类大脑会接受非常多的讯息,必须根据观察到的时间和空间去压缩。也有证据表明, 人类对未来的感知是跟着大脑里面对未来的判断走的,这样在未来可以做出非常快的反应。这个道理也被应用在reinforcement learning里,很多模型都有记忆和预期的部分。
现在大量的RNN模型是非常有利于做记忆和预期的部分,但是很多reinforcement learning的算法都被限制在在credit assignment的部分,所以现在很多reinforcement learning用的都是小的模型,然后快速迭代,但是这个文章讨论的就是如何用大的RNN来训练一个agent。
训练是一个很大的问题,要训练一个很大的RNN是需要很多cycle的。这个文章把训练RNN的问题拆成了训练一个大的世界模型跟训练一个小的控制模型,然后这个小的控制模型在大的世界模型里面训练。小的控制模型保留credit assignment可以快速迭代的优势,又可以用大的模型来保留RNN的优势。在这个想法出来之前,有很多用NN来做reinforcement learning的想法,具体可以看这个文章 [1708.05866] A Brief Survey of Deep Reinforcement Learning ,把在2017年中之前的想法都总结了一遍。
Agent(智能体)模型
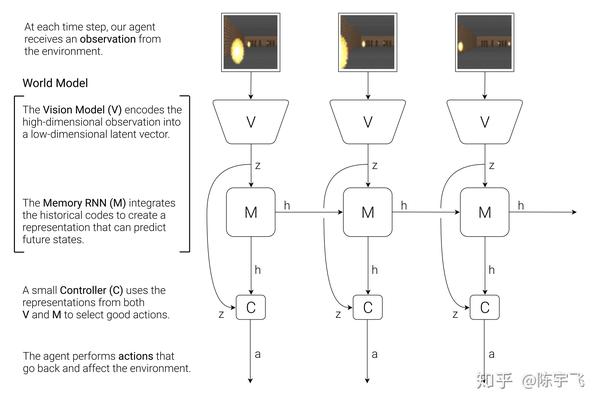
Agent的模型分三个部分:视觉,记忆,跟控制器。
视觉的输入是2D图片,用的是Variational Autoencoder(VAE)。对这方面感兴趣的同学可以看这里:[1312.6114] Auto-Encoding Variational Bayes ; [1401.4082] Stochastic Backpropagation and Approximate Inference in Deep Generative Models
记忆模型用的是 Mixture Density Network(MDM), 模型的输出不是单纯一个对未来的预期,而是对未来判断的分布。这个模型之前是应用在Google画画的那个问题上面,你一边画,模型可以一边判断你下一步要画什么。文章在这里 arxiv.org/pdf/1704.03… 。
控制器模型用的是一个线性模型, 。z是VAE模型的输出,h是MDM模型的输出,所以W跟b都是要学习的参数,所以整个模型长这样:
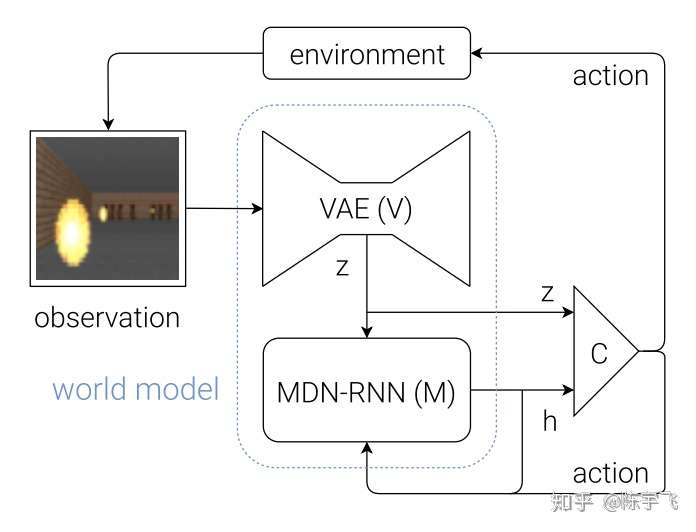
这个模型里面大部分的参数都是在视觉和记忆模型里面,控制器模型只有小几千个。真个所谓的“世界模型”的部分,就是视觉和记忆的模型。
开小汽车实验
如何把上述的模型放到实际应用里面呢?在一个模拟的道路上开车是一个很好的例子(文中说这个模型是目前效果最好的)。训练的过程是
- 先随机运行一万次
- 训练视觉模型,最小化输入图像跟模型重建图像的差别(输出是32维的向量)
- 再来训练记忆模型,记忆模型每次可以拿到的输入是这一帧的行为和压缩的视觉数据,然后来训练对未来的判断
- 再来训练控制器模型,训练用的是CMA-ES,一种遗传算法
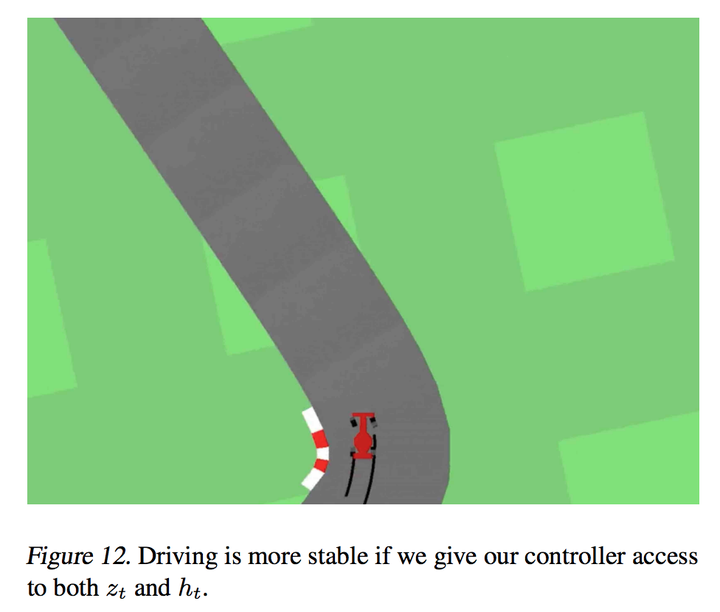
文中特别提到视觉模型跟内存模型是可以一起训练的,但是分开训练比较好操作一点。视觉模型虽然会丢失细节,但是重点都有抓住,下图可以看出来原图跟视觉模型重建的图片:
因为记忆模型可以用来判断未来,整个训练甚至可以在“梦中”进行,像这样:

玩射击游戏(Doom)
接下来讨论的是如何在梦中训练,然后把在梦中训练的结果放到模拟环境中。Doom是很经典的射击游戏,里面有火球的设定,然后玩家要懂得如何去躲飞来的火球。跟开车相比,两个模型的差别在于
- 随意收取60秒(2100帧)的数据
- 视觉模型输入是64维而不是32维
- 这里内存模型不仅要预测未来的分布,还要预测下一帧玩家是不是挂了,这样的话整个训练就可以在梦里面了,因为控制器可以知道如何去进化了。真实的环境跟压缩的环境也是非常的相像

整个训练过程用的都是记忆模型来判断到底控制器是不是害死的玩家,为了增加难度,MDM模型有一个参数是“温度”,可以用来增加输出的不确定性,增加不确定性之后可以帮助控制器不去过多的利用模拟环境里面的失真的错误。这是一个非常关键的变化,如果输出是一定的话,控制器会快速的发现内存模型的漏洞。这个”温度“模型也不能调的太高,不然的话梦境里面游戏难度会太高,导致控制器什么都学不到。
迭代训练过程
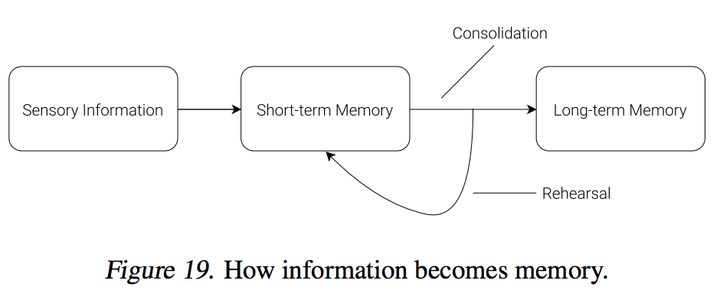
这个提出的方案是很好和很有新意,但是这个模型只适合相对简单的环境,毕竟视觉模型跟内存模型都是体现训练好的,然后收取的记忆也就每次几千到上万个图片。文章给出的解决方案是迭代训练,把内存拆成短期记忆跟长期记忆,内存模型也得通过修改loss function来确保在新的训练里面,控制器足够”好奇“,来收集不同的信息去重试它的世界模型
总结
这个文章把很多不是特别新的reinforcement learning的概念巧妙的结合了一下,整个概念我觉得非常有意思。难得的是这个文章居然有这么完整的demo,其中内存模型的“温度”的概念在demo网站里面有(World Models),我建议大家去玩一下,看看梦境里面训练作为人类到底是什么感受,我自己玩了两下,确实有做梦的感觉,哈哈。
